Quicktrader,
Any resemblance to Zodiac symbol is coincidental and irrelevant.
I suggest 3 symbols form 1 letter or 2 symbols forming one letter which is less likely but plausible.
I stole this idea from Harvey Colliver partially.
Yes, dyslexia is probably my first undiagnosed language.

Crickedicracke….Polly wants..
QrickedicrackaTiquracker..kraaah!
*ZODIACHRONOLOGY*
Guess not, It’s to easy to be true.
Yes, dyslexia is probably my first undiagnosed language.
I wish it was that easy..for the first, easiest, slightest step, my pc is computing since approximately 1-2 weeks, few hours per day.
Besides IoFBc (65 most frequent), there is
– 1 bigram (30)
– 3 variables A-Z (26^3)
– 1 variable frequent (11 – ETAOIN..)
to get the first section in line 17, thus:
65x30x26^3×11 = 377,005,200 x 4,500 x 4,500 words (2 words to be found!) = 1,696,523,400,000 or 1.7 trillion words to be placed at any position of the string (x 3-5…depending on word length found..).
And that’s only the beginning: Computation continues only with results found, nevertheless in further steps there (currently) are considered an additional
– 2 bigrams (30)
– 2 variables A-Z (26^2)
– 1 trig (1000 frequent) and to make it easy, in further steps
– 2 additional variables A-Z (26^2)
leading us to a total of 53,672,571,501,120,000,000,000 or 53.7 sextillion different letter variations ‘covered’ with a total of nine different strings of the Z340 cipher. If anybody thinks calculating with less would make sense: No problem as long as you can handle 2 billion results..
All of the previous 53.7 sextillion variations are considered during the computation process (all..). However, "exclusion happens during computation", that means that e.g. if there are no two words found in string on line 17, the rest will not be computed (and so on, step by step over all nine sections of the cipher).
Nevertheless, computation takes days, if not weeks or months (or forever..) for each pre-set configuration. If one (repeating) bigram is not amongst the chosen 30, the whole computation process will remain without result.
Not to think what if the IoFBc section represented a non-frequent 5-gram..there is a total of 1,490,116,119,384,765,625 variations for those five letters alone! And, so far, we deal with the most frequent 65 only! The only ‘hope’ is that due to IoF as well as FBc repeating in the cipher, the approach to start with the most frequent ones could be a good one..
QT
*ZODIACHRONOLOGY*
I’m sorry i said anything ![]() but i’m glad someone finds it intersting.
but i’m glad someone finds it intersting.
My view is that it is tri-gram where symbols are for either A,B,C,D. I know bigram looks to be more fitting but the methodology of which a human might have made this makes me believe it is tri-gram (also the low variety of symbols producing few codes.
also with a trigram you start to notice that many of the symbols are just artistic noise to distract – whatever that means but it’s what i notice.
anyway what i suggest is that the symbols follow this key or one very similar
AAA = A
AAB = B
AAC = C
AAD = D
ABA = E
ABB = F
ABC = G
Etc etc until Z where it starts over again until DDD.
Some letters may be a Bigram because the structure allows it for instance A can just be “AA” instead of “AAA”
Anyway i wish you success, The Tri gram is most interesting, if you want my notes it might help you start i made progress with many symbols and have narrowed things down using common sense and pen and paper. (made guesses that certain letters wouldn’t be in certain places there by narrowing protential values for symbols.
Yes, dyslexia is probably my first undiagnosed language.
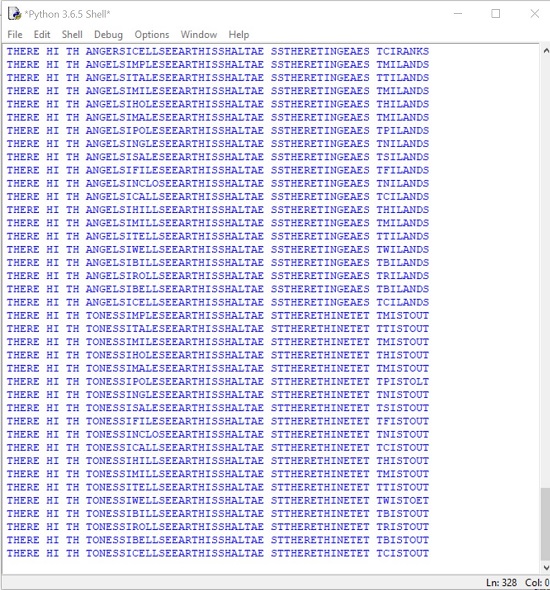
Update…slight modifications in which lines, where they start, which order etc..meanwhile finding a total of eleven (11) words of length >4 on different sections of the Z340 cipher. Results look like this (first shows chosen 5-gram, 3-gram):
.. THERE VEN SEEARTHISSHAREAE SEVENTHEES EHSTERNA TONESSREST SSETHEREE EUSANTAEHISE NRREPOLESHS REPULSESRPENT EITETOORESTS EEAFSHOSTS THERE VEN SEEARTHISSHAREAE SEVENTHEES EHSTERNA TONESSREST SSETHEREE EUSANTAEHISE NRREPOLESHS REPULSESRPENT EITETOORESTS EEAFSCOSTS THERE VEN SEEARTHISSHAREAE SEVENTHEES EHSTERNA TONESSREST SSETHEREE EUSANTAEHISE NRREPOLESHS REPULSESRPENT EITETOORESTS EEAFSPOSTS THERE VEN SEEARTHISSHAREAE SEVENTHEES EHSTERNA TONESSREST SSETHEREE EUSANTAEHISE NRREPOLESHS REPULSESRPENT EITETOORESTS EEAPSHOSTS THERE VEN SEEARTHISSHAREAE SEVENTHEES EHSTERNA TONESSREST SSETHEREE EUSANTAEHISE NRREPOLESHS REPULSESRPENT EITETOORESTS EEAPSCOSTS THERE VEN SEEARTHISSHAREAE SEVENTHEES EHSTERNA TONESSREST SSETHEREE EUSANTAEHISE NRREPOLESHS REPULSESRPENT EITETOORESTS EEAPSPOSTS
Still finding 100,000+ different variations just on that pre-setting. Some might seem to be duplicates, however might be configured based on e.g. different bigrams (e.g. EN and AN both contain N as the second letter).
‘Cleartext’ strings already cover 223 out of 340 symbols, thus more than 65% of the total cipher (of course only searching one word in each section, not overall cleartext, so far).
Thus, now adding a twelvth word the program shall search for. We’ll see.
QT
*ZODIACHRONOLOGY*

Hey Quicktrader,
Index of coincidence of such a string is 0.1359. Should be closer to 0.0667 for English. You may need frequency control.
THEREVENSEEARTHISSHAREAESEVENTHEESEHSTERNATONESSRESTSSETHEREEEUSANTAEHISENRREPOLESHSREPULSESRPENTEITETOORESTSEEAFSPOSTS
Thank you for the hint. The IoC is based on frequency of the (alphabetical) letters. However, we deal with homophones’ frequencies (first), thus the IoC of an encrypted message (homophones = 63) is way different than that of the same message in decrypted status (alphabet = 26). Because different frequencies as well as overall amount of homophones lead to different IoC values of encrypted and decrypted texts.
From en- to decrypted messages, the IoC value might therefore be multiplicated by the average amount of homophones per alphabetical letters (in use). Should be aware that latter could be wrong as homophones are not necessarily used equally often for each letter..
It is possible to test the aspect of different IoCs regarding encrypted and decrypted messages: If you enter the encrypted message of the Z408 cipher into an IoC analysis tool, you should get an IoC value of about 0.0269 instead of 0.066 (for English language). Nevertheless, the Z408 – as a cleartext – is written in English, has a higher IoC value when decrypted:
54 homophones vs. 23 alphabetical letters in use [‘in use’ correct?] is 2.3478 homophones per alphabetical letter, thus the cleartext should actually have an IoC of
0.0269 x 2.3478 = IoC 0.063 (Z408 expected)
(IoC English language ~ 0.066)
which is actually very close to the English language, while the IoC of the encrypted Z408 message has only an IoC value of 0.0269. The Z408 cleartext has a IoC of 0.0634, thus the multiplication is actually a ‘match’.
Same with the Z340, even more homophones, though.
It would be nice to engineer the computation process to a degree that it decides while computing on which IoC level the computation itself is actually deciding where to compute..the problem is. If there is a short python script for that, I’d love to implement it (based on multiple IF/FOR loops, eg. ‘interrupting’ or rowing back if the first loop has a bad IoC). I’d appreciate..maybe sometime in the future.
The problems are manifold..with a solid dictionary it is obviously possible to find 10 words of length >4 or more (like ZDK does often). But that is not necessarily the cleartext solution. As if that wasn’t worse enough, the more ‘steps’ are performed, the more computational effort is actually required. To find three words in the cipher can be done in a second..to find more than 10-12, however, could take us into the year 3,000..
Please keep in mind that the encrypted IoC values are not ‘wrong’ – they just deal with a different sized alphabet (e.g. 54…like an alien language ![]() ). Of course that has to be a different situation than (cleartext) English language (with a max. of 26 letters). Most likely, a language with 54 letters actually has a IoC level of less than three.
). Of course that has to be a different situation than (cleartext) English language (with a max. of 26 letters). Most likely, a language with 54 letters actually has a IoC level of less than three.
IoC calculator
https://planetcalc.com/7944/
IoC based on frequencies
https://pages.mtu.edu/~shene/NSF-4/Tuto … g-IOC.html
Because of the effects above, I wouldn’t rely too much on the IoC for homophone ciphers, at least not without considering the differences between encrypted and decrypted text.
Based on the previous thoughts, with 63 homophones divided by a max. of 26 letters (2.423 homophones per letter), as well as an English language IoC of 0.066, we could reconstruct if the Z340 is English language or not:
0.066 / 2.423 = 0.0272 IoC encrypted (Z340 expected).
Entering the encrypted message in the IoC calculator (considering 63 homophones!) indeed leads us to an encrypted IoC value of 0.0277 for the Z340, which is a deviation of only 1.7% from our expectation.
Thus, in a range of <3%, the encoded message of Z340 represents English (or similar language) cleartext. Therefore, with a probability of with 98.3%, the Z340 is not a hoax either, by the way.
QT
*ZODIACHRONOLOGY*

Here’s what my word break guesser does with it:
THE REVENSE EAR THIS SHARE A E SEVEN THE ES EH STERN AT ONESS RESTS SE THERE EE US ANTAE HIS ENRRE POLE SHS REPULSES RPENT EITE TOO REST SEE A FS POSTS
The strings appear in a row but are from different areas of the cipher (see May 31st, 2019, posting), fwiw.
QT
*ZODIACHRONOLOGY*

I have worked with many manufacturing computer systems, but you guys are way over my head. I don’t write code. I was the guy that worked with IT to figure things out to get the information that the end user needed. I know you guys have to figure out how the code was compiled first and it is probably in English. This may not be the thread to post this question, but what if the 340 is in a foreign language? Can a program be written to look at that possibility as you go along or do your programs already look for that? Has it been attempted before? Is it even worth it?
This may not be the thread to post this question, but what if the 340 is in a foreign language? Can a program be written to look at that possibility as you go along or do your programs already look for that? Has it been attempted before? Is it even worth it?
I tested many languages in early 2017: viewtopic.php?f=81&t=3242
Quicktrader,
The IOC of the 408 is 0.0184 and the IOC of the 340 is 0.0193. What now?
Feel free to use AZdecrypt Lite @ http://jarlve.vdm-service.be/ to determine the IOC by putting a cipher in the left hand window and then clicking Statistics, Overall:
Length: 408 Symbols: 54 Dimensions: 17 by 24 Multiplicity: 0.1323529411764706 Entropy: 5.659921738167404 Index of coincidence: - Raw: 3070 - Normalized: 0.01848773907597437 <--------------- IOC - Flatness: 0.8712269272529858
I will, thanks…IoC might depend on if you use 23 (in use), 24, 26 letters for its calculation. Just entered it into the online tool (previous link). Both values show it’d be better multiplicated with the average amount of homophones per letter, to get English language value. Which is logical as well, imo, as the encrypted ‘alphabet’ of homophones has more ‘letters’.
IoC value of 0.0193, based on English language, implied somehow 3.42 homophones per letter (average), I’d say (0.066 divided by 0.0193). Just show how way more difficult the Z340 is compared to the Z408..
But as I said, not very much into IoC stats..
QT
*ZODIACHRONOLOGY*
It’s getting interesting…
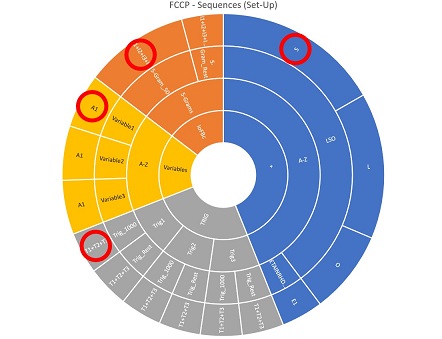
For the 100th time or so, the setting of the FCCP program has been changed. After finding way too many partial solutions with 10, 11 or 12 words, I went back to find rather one longer string instead of multiple short ones.
This time the focus is on line 16 to 18, filling all up with trigrams, bigrams, IoFBc, plus symbols etc. to get a string of 27 letters.
Still, way too many results. So I had to reduce the amount of data:
As soon as the program now finds any word, not only in the first, but also in the second and third string, I told my PC to skip the printing of all of its variations. As a result, I do receive only the initial partial cleartext variations from the first string. However only those, which are at least backed up with at least one result in (currently) two other strings / areas of the cipher (line 13 and line 1).
This step might be smart as we now get an overview of all potential solutions for line 16 to line 18 (4th row of interest only):
As you can see, there still is a long way to go. The first rows of the diagram are acually supporting to understand how much has already been computed.
Nevertheless, we already get some nice cleartext candidates for this area of the cipher, e.g. A SEEMS I BROWSE NORTH IS SHOOK OE or A SEEMS I EXCUSE FOR THIS SHOCK OE (not shown in the diagram).
Of course this is not the correct solution, but it shows that the program can now go very much ‘lingual’, with meanwhile considering all relevant cipher structures: Repeating bigrams/trigrams; homophones occurring on specific locations of the strings analyzed etc.. We are now finding text.
We will see, how fast the program is doing on that one, which is obviously crucial. So far, the program does not print 99% of all variations, but it still computes them. Therefore, the next goal will be to only compute until in all strings words are found – but skip the rest of the computing (as we are only interested in string #1..).
This could actually safe a tremendous amount of computation time, I’d say like 99.999% or even more. The solving process itself would therefore be performed like this:
– Set variables (e.g. IoFBc or the + symbol)
– Complete strings #1,…with eg. trigrams or alphabet letters
– Search string #1 for minimum 4 words of length >4 (one solution)
– Search string #2 for minimum 1 word of length >4 (one solution)
– Search string #3, #4, #5,… " "
– If any solution is found: Stop computation, print words of string #1 (and any of the first solution found for the other strings)
– Print string#1 and rest of data
– Find logical content in string#1 results
– Compute rest of the cipher based on logical result found on string #1
Thus, the program hopefully will start with the longer string #1, then verifies its correctness on various other strings of the cipher, finally goes back to string #1 to print (without computing all the other variations).
The advantage of this forward-back-forward method is obvious:
We only receive a list of ‘successful’ strings of length 27 letters. The length of this list can then be reduced more and more by adding additional strings in which at least one word shall be found. And those remaining partial solutions can be looked at.
If there is one string with LOGICAL content, it might be our cleartext candidate (without computing the rest of the cipher at all). Based on this specific string, all other partial solutions can be discarded. Then finally completing the rest of the cipher by computation, all based on the logical string #1 that might then have been found.
Z being crackproof? Surely not.
QT
*ZODIACHRONOLOGY*
