
Hey all,
I’ve been away from the ciphers for a while…
This weekend I started work on a 340 symbol placement map. I carefully extracted the x and y position as well as the x and y size for each symbol with an imaging program. I then wrote the values into a program to play around with. I treated the erroneous symbol K as the K that was scratched out and ignored the smaller flipped K above it.
I found some things which may have been mentioned before, but not to my knowledge. In the following image I ignored symbol size and just placed circles from the center of each symbol.
https://www.dropbox.com/s/0nbk77mik0ywp … 6.png?dl=0
Notice the extra spacing between row 12 and 13. It is also observeable on the cipher itself if you are looking for it. This is pretty much the main thing I have found and I’m not sure what it could mean. It is not the fold line.
Another thing, which is more vague and uncertain is that the symbols seem to appear in groups of two here and there.
what do you think?

Very good observation and analysis, Jarlve.
Lines 11, 12, and 13 each have no repeated symbols. Similarly, lines 1, 2, and 3 each have no repeated symbols. Dan Olson from the FBI believed the cipher should be split and recombined into a single region of high randomness. Could the observed gap in the lines be an indication of the cipher author setting up this kind of step?
Also, above and below the gap are the intersecting trigrams:

Could there also be a relation between the gap and those intersections?
It is interesting that 8 rows occur after the gap, since the first cipher was split into three parts, each containing 8 rows.
Jarlve, can you post the raw (x, y) data you collected?
Hey doranchak,
https://www.dropbox.com/s/y9d0b5nd33bzs … a.txt?dl=0
Explanation of the data is in the file.
I’ll get back to your comments after I get some rest.

Very good observation and analysis, Jarlve.
Lines 11, 12, and 13 each have no repeated symbols. Similarly, lines 1, 2, and 3 each have no repeated symbols. Dan Olson from the FBI believed the cipher should be split and recombined into a single region of high randomness. Could the observed gap in the lines be an indication of the cipher author setting up this kind of step?
Also, above and below the gap are the intersecting trigrams:
Could there also be a relation between the gap and those intersections?
I may be reading it incorrectly, but dont lines 11, 12 and 13 have a filled circle repeating in them?
I may be reading it incorrectly, but dont lines 11, 12 and 13 have a filled circle repeating in them?
That’s correct. But the repetitions occur on different lines. The lines themselves have no repetitions within them.
Lines 11, 12, and 13 each have no repeated symbols. Similarly, lines 1, 2, and 3 each have no repeated symbols. Dan Olson from the FBI believed the cipher should be split and recombined into a single region of high randomness. Could the observed gap in the lines be an indication of the cipher author setting up this kind of step?
This could be seen as significant since there are only 9 individual rows which have no repeats. Though I’m not sure because with 63 symbols and well flattened frequencies you don’t see many repeats.
The following images showing the repeats per row for the 340 and the 408 redone with 63 symbols.
https://www.dropbox.com/s/ndiv9fkv33fvb … e.jpg?dl=0
https://www.dropbox.com/s/fbf67n4w72gbm … e.jpg?dl=0
I am also still considering the possibility that the gap between 12 and 13 somehow occured by chance. The brain seems to works in such a way that it tunes in and enunciates the most dominant patterns. But looking at the image I generated I do feel something is going on, and the gap might just be a small part of it. For instance, there also seems to be more space between 6 and 7, 18 and 19, which is an interval of 6. In general grouping of symbols in rectangluar shapes?
I superimposed the symbols over the circles image, but I visually adjusted the scale and alignment so it should not be perfect but it can serve to compare.
https://www.dropbox.com/s/ju863ob703u2i … y.png?dl=0
Do you have more on the intersecting trigrams?
Thanks for the dataset. I plotted each rectangle and overlaid this copy of the 340. Here’s the result:
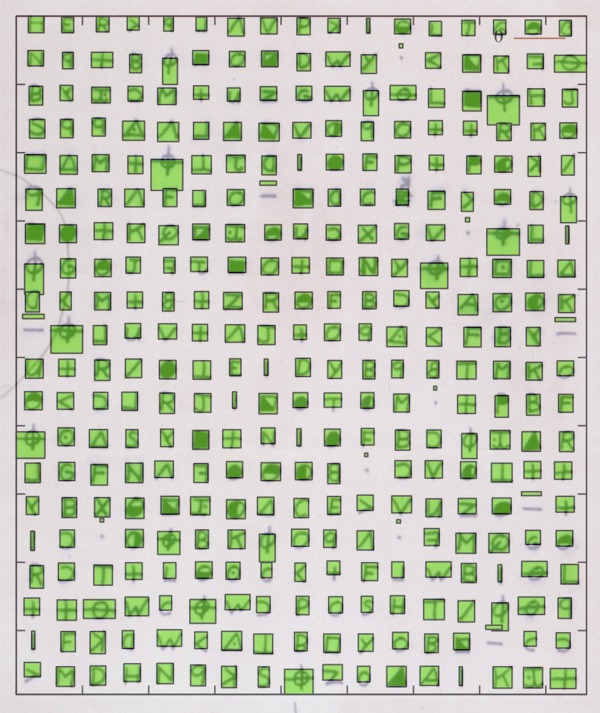
(Ignore the zero followed by the horizontal red line)
Looks accurate except for the crossed circles, dots, and horizontal lines. Which image of the 340 did you use as the basis of your analysis?
Also, I calculated the distances from the bottom of each symbol to the bottom of the symbol right below it. Then I calculated the median distance for each row. Here is the result:
1084 12 13
1031 2 3
1022 14 15
1021 6 7
1010 5 6
1009 10 11
1009 1 2
1008 18 19
1007 8 9
1006 3 4
1006 17 18
985 19 20
984 7 8
984 4 5
982 15 16
969 11 12
960 9 10
944 16 17
932 13 14
First number is the median distance. Second and third numbers indicate which two rows are compared. For example, "1084 12 13" means that there is a median distance of 1084 between rows 12 and 13. I used median distance to try to avoid outliers affecting the estimate of gap distances.
The results are shown in descending order. They confirm the biggest gap is between rows 12 and 13. Interestingly, the smallest gap is between rows 13 and 14, which is right after the biggest gap!
One explanation for this could be the cipher author wrote out the cipher as a 34×10 block but then cut it up into 17-column chunks of rows to rearrange them into a 17×20 block. The resulting chunks may have preserved the gap distance of the rows they originally belonged to. But there’s no cutting and pasting evident in the cipher, so he would have had to re-write it, perfectly preserving the placements of symbols in the result.
Do you have more on the intersecting trigrams?
A few years ago I tried to estimate the odds of two intersecting trigrams appearing completely by chance when enciphering a plaintext in the normal way (left to right, up to down, using homophonic substitution).
The full analysis is here: http://zodiackillerciphers.com/wiki/index.php?title=Pivots
If you randomly shuffle the 340 like a deck of cards, two pairs of intersecting trigrams will naturally occur in about one in a million shuffles.
Looking at random samples of plaintext only, two pairs of intersecting trigrams (pointing in the same direction) occur in about 1 sample per 70.
If you then encipher the plaintext, chances are the intersecting trigrams in the plaintext will be destroyed. But in my article I came up with a rough estimate that if you pick plaintext samples at random, and perform homophonic substitution without regard for preserving the trigrams, then there’s about a 1 in 280,000 chance the trigrams will remain preserved in the enciphered message.
So, the pattern might be difficult to arise from chance alone, and might be some fundamental feature of the encipherment scheme.
Or, the encipherment scheme being used somehow causes such patterns to appear more frequently by chance alone.
Hard to say without knowing the scheme! ![]()
The other thing that interests me is the "corner marks" feature:

Notice how they are separated by 4 columns, just as the pair of intersecting trigrams are. Probably just the "pattern matching" part of my brain going into overdrive. ![]()
Do you have more on the intersecting trigrams?
A few years ago I tried to estimate the odds of two intersecting trigrams appearing completely by chance when enciphering a plaintext in the normal way (left to right, up to down, using homophonic substitution).
The full analysis is here: http://zodiackillerciphers.com/wiki/index.php?title=Pivots
If you randomly shuffle the 340 like a deck of cards, two pairs of intersecting trigrams will naturally occur in about one in a million shuffles.
Looking at random samples of plaintext only, two pairs of intersecting trigrams (pointing in the same direction) occur in about 1 sample per 70.
If you then encipher the plaintext, chances are the intersecting trigrams in the plaintext will be destroyed. But in my article I came up with a rough estimate that if you pick plaintext samples at random, and perform homophonic substitution without regard for preserving the trigrams, then there’s about a 1 in 280,000 chance the trigrams will remain preserved in the enciphered message.
So, the pattern might be difficult to arise from chance alone, and might be some fundamental feature of the encipherment scheme.
Or, the encipherment scheme being used somehow causes such patterns to appear more frequently by chance alone.
Hard to say without knowing the scheme!

The other thing that interests me is the "corner marks" feature:
Notice how they are separated by 4 columns, just as the pair of intersecting trigrams are. Probably just the "pattern matching" part of my brain going into overdrive.
What about where the 3 "+" marks make a right angle as well in two areas? One starts on line 4 and the other on line 14.
Does that make sense?
This is what I mean….I outlined in red from your pic. Also odd that these started on the lines they did being that prior to them there were no repeating symbols on the lines.

Those are interesting, too, but since there are many "+" symbols in the cipher, such clusters are more likely to occur by chance.
This is all relative, of course, because the box corner patterns could also be occurring by chance. And we always have to keep in mind that rearrangements of the cipher text may produce other kinds of patterns by chance. The chances of a specific pattern occurring might be low, but the the chances of any interesting pattern occurring are high.
Oh, and the box corners intersect with a repeating 3-symbol fragment:

It is underlined in yellow.

{kind=link}
{kind=link}
{kind=link}
{kind=link}