
This may take me a little time. I am tired and working on other non 340 related projects. But I have been chipping away at it.
I separated your message into two parts, three parts, and all the way to six. But have only looked at two parts.
When I separated into two parts, part 1 and part 2, I compared part 1 versus several randomizations of part 1. And I compared part 2 to several randomizations of part 2.
It looks like there may be an odd number of parts. There is always much more cycling in the original part 1 as compared to a randomized part 1. But on the other hand, there is either roughly equal to or less cycling in the original part 2 as compared to a randomized part 2.
I have not looked at the 340 or one of the test messages that I know has only one key.
Still making adaptations.
Still working on it, Jarlve. But I had another idea that I have to write down while I am thinking about it. You have been discussing columnar transposition in the past, and I remember daikon talking about the numerous possible column rearrangements.
What about hill-climbing the column rearrangements to maximize cycle scores. Switch two columns and check the overall cycle stats. If the score is higher, keep the switch. If not, make another switch. And keep doing that to see if there is a possible rearrangement of columns that gets much more perfect cycles.
That’s it for now, back to the cycling of keys work.

Me and daikon have tried hill-climbing columnar transposition regularly. But since the solution is very spikey you get only a very small reduction from the hill-climbing process.
You can increase overall cycle scores with columnar transposition, certainly when considering 17 elements. Also daikon and I have come to the conclussion that it seems somewhat unlikely for columnar transposition to be actual after encoding, and your work has suggested that too. And if it was done prior to encoding, it would have not have any effects on the cycles (encoding).
If the 340 remains uncracked at some point I’d like to consider brute forcing all 17! permutations. But we’ll need to come up with a way to crack 11.278.774 ciphers per second for one year long. So it seems better to somehow cheat/reduce the problem by at least a factor of 100.000.
I’ve been thinking of coupling row annagram scores + solver. Certainly worth trying at some point.

If the 340 remains uncracked at some point I’d like to consider brute forcing all 17! permutations. But we’ll need to come up with a way to crack 11.278.774 ciphers per second for one year long. So it seems better to somehow cheat/reduce the problem by at least a factor of 100.000.
That’s what I keep coming back to, that he just rearranged the columns in some specific order that made sense to him. You don’t actually need to attempt to crack all 17! permutations. You can filter out all permutations with bigram counts below certain threshold. Or just order them by bigram repeats in descending order, and start from the top. You can even skip a lot of the candidates at the top, as you’ll end up with 3+ same symbol repeats in a row. The problem is, even if you end up filtering out 99% of the candidates, even 1% of 17! is a HUGE number. I might eventually bite the bullet and implement a GPU based solver, to speed things up quite a bit. I need to upgrade my gaming computer to a modern graphics card anyway. 🙂
But one thing that keeps bothering me is that Z340 has a very distinct difference in bigrams repeats both between top and bottom half (thanks again for noticing that!) and between even and odd symbols. I can’t quite consolidate these 2 facts. Just a coincidence? Or did Z use 2 different transpositions on the top and bottom halves? Or did he do something to the cipher that worked on both rows and columns? That somehow ended up separating the top and bottom halves in distinctly different arrangements?
I’ve been thinking of coupling row annagram scores + solver. Certainly worth trying at some point.
Can you elaborate a bit on this idea? I’m not entirely sure what you mean?
Can you elaborate a bit on this idea? I’m not entirely sure what you mean?
With columnar transposition the information on the rows is still the same, just in a different order. So it might work if you come up with an anagram algorithm that scores each row and hill climb to the total score of the rows.
m5p1
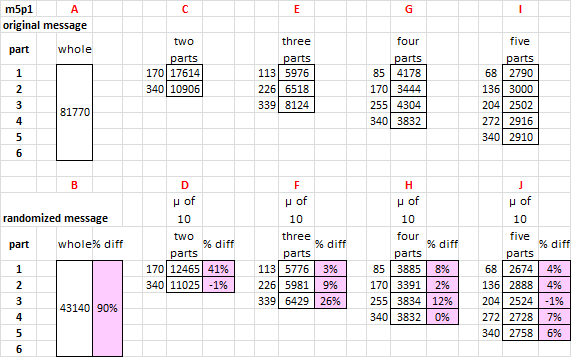
I broke m5p1 into two parts, three parts, four parts and five parts.
1. Compare A and B. A is the total cycle score for the whole message. B is the mean of ten randomizations. m5p1 is cyclic.
2. Compare C and D. C is the total cycle score for the message in two parts (odds and evens). Part 1 scores much higher than Part 2. When compared to a mean of ten randomizations, shown under D, I find the same thing. You may have made the message into two parts, and cycled odds and totally randomized evens.
3. Compare E and F. Broken down into three parts, Part 3 is more cyclic than Part 1 and Part 2. I don’t know what to think of that.
4. Compare G and H. Broken down into four parts, this shows Part 1 in a two key message is broken down into two Parts 1 and 3, which score higher than Parts 2 and 4.
5. Compare I and J. Numbers all over the place and low.
What did you do? Did you make a message in two parts, and make one cyclic and one random? Or did you make the message in three parts and make one cyclic and two random? Or, four parts?
I have started to look at the 340. Parts 1 and 2 of a two key message are almost exactly the same.
I guess it doesn’t matter what the stats show with the 340. Have you broken down the 340 into parts, and expanded the symbols in the parts that are not mutually exclusive of the other parts? I could do that if you want me to and post them. Say, break down the message into Part 1 and Part 2 (odds and evens). Then find the symbols that they share, and expand them for the part that has the lowest count of shared symbols, to minimize multiplicity. Then three parts, etc. Or have you done that and with no results? Has anyone ever done this before?
I’ll line up your numbers versus mine for m5p1:
C, two parts:
Part 1: 17614 / 2783
Part 2: 10906 / 1645
E, three parts:
Part 1: 5976 / 1143
Part 2: 6518 / 1089
Part 3: 8124 / 1883
D, four parts:
Part 1: 4178 / 877
Part 2: 3444 / 675
Part 3: 4304 / 972
Part 4: 3832 / 828
I think our numbers, 2 different ways of measuring cycles/randomness, line up pretty well and it seems that m5p1 is quite hard. It’s 4 parts with the 2nd part randomized. This shows up in both our numbers but the part 1 versus 2 difference is much, much stronger.
Before randomization: m5p1_stage1
Two parts m5p1_stage1:
Part 1: 2783
Part 2: 2189
So this shows there was already a 27% difference which then got bumped up to 60% because the 2nd of 4 parts accounts for 50% of the 2nd of 2 parts.
I have started to look at the 340. Parts 1 and 2 of a two key message are almost exactly the same.
Two parts 340:
Part 1: 2129
Part 2: 1706
For my numbers there is a 24% difference, almost the same as m5p1_stage1. Maybe this is a thing with homophonic substitution? If so, very interesting.
I guess it doesn’t matter what the stats show with the 340. Have you broken down the 340 into parts, and expanded the symbols in the parts that are not mutually exclusive of the other parts? I could do that if you want me to and post them. Say, break down the message into Part 1 and Part 2 (odds and evens). Then find the symbols that they share, and expand them for the part that has the lowest count of shared symbols, to minimize multiplicity. Then three parts, etc. Or have you done that and with no results? Has anyone ever done this before?
Ah yes, I should indeed only expand symbols that are not mutually exclusive. I have done some experiments in that manner but nothing thorough. I think it will be interesting if we line up our numbers for the 340 and from there perhaps create some more test ciphers and see if we can break them. If so, try the same with the 340?
O.k., Jarlve, I will work on the 340 stats and post them. Our stats do line up pretty well in general, and it is very interesting how the stats change when breaking down into different parts. With two parts it is easy, but with three parts, half of the two parts odds are in the third part, and half of the two parts evens are in the third part. I like, however, that I was able to guess that maybe you randomized at least one of the parts, even if it was the wrong one.
O.k., I would like to continue with this experiment if you want to. Keep it limited to four parts or less, though, o.k.? I think that the more parts, the more expanded symbols maybe. With four parts, we may be expanding too many. Maybe even with three parts there will be too many expanded symbols.
Also I need to mention something else about this method. There are at least two different ways to encode with multiple keys. One method, which I used for smokie6 because it was easy for me to do on a spreadsheet and I didn’t think about it enough first, is to make two whole messages and splice them together. That deletes half of the symbols for each message that are encoded in perfect cycle order. However, I think that Zodiac could have more easily cycled his use of keys when making symbol selections (which is what I thought I was doing when making smokie6). With that method, breaking down into different parts will reveal perfect cycles. With two different methods, you will get different results. The symbols in the final message will be slightly different at first I think, and become more and more different the farther into the message we go… ?
Do you want to make the next message, or do you want me to make the next message? Let’s keep it fairly simple. If I make the next message, it won’t be I like killing. But either way, we can trade off the work steps if you want.
Here are my 340 stats, which I feel very confident in. My spreadsheet has all two symbol combinations that rearranges with any new or changed message. Each is scored according to how many consecutive alternations there are, and then I total everything up.
My Part 1 and Part 2 are nearly identical. Actually that sort of tells me that whatever Zodiac did, maybe it was uniform throughout. Or maybe there are three keys, with Part 1 being a bit more cyclic than the others. I am not sure and this is a very difficult subject. The more parts, the fewer symbols to work with, and maybe not enough to determine anything.
On the other hand, your Four Part stats lined up pretty well with mine. When I randomized Part 4 ten times and calculated the mean, it showed that Part 4 was not cyclic, and you say that it was.
Did you splice four whole messages together or alternate keys when encoding?
By the way, score for the first half of the 340 is 14892, and for the second half 13054. The first half is more cyclic. So if you compare to Part 1 and Part 2, which have nearly the same score, it would seem to show that randomization is more in the second half, but uniform with odds and evens.
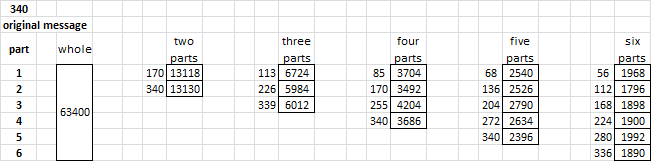
340 line up (smokies in bold):
Two parts:
Part 1: 13118 / 2129
Part 2: 13130 / 1706
Three parts:
Part 1: 6724 / 1266
Part 2: 5984 / 1075
Part 3: 6012 / 1090
Four parts:
Part 1: 3704 / 738
Part 2: 3492 / 562
Part 3: 4202 / 946
Part 4: 3686 / 747
I don’t think it is very reliable to go beyond 4, as you’ve said so yourself as well. The stats line up well for everything except the two parts.
Did you splice four whole messages together or alternate keys when encoding?
I just encoded the plaintext normally and then randomized the 2nd part of 4. The randomization keeps the original symbols but just moves them around for a large number of iterations.
340 halves line up:
Part 1: 14892 / 2084
Part 2: 13054 / 2273
Doesn’t line up. It’s because there are a higher number of interruption symbols in the 1st half (your original wildcards) and my measurement is more heavily affected by those. I believe that’s what causing some of the discrepancies. I may need to come up with a real cycle measurement of myself.
It is interesting that there appears to be more cycle randomization in the 2nd part, but I also wonder if it could be somewhat related to cutting the message in halves. Are perfectly cycling halves equal for your system?
You make the next message and I’ll see what I can come up with and after that I’ll make the next one and so forth (if you are okay with that). I agree to not use more than 4 parts.
It is interesting that there appears to be more cycle randomization in the 2nd part, but I also wonder if it could be somewhat related to cutting the message in halves. Are perfectly cycling halves equal for your system?
You make the next message and I’ll see what I can come up with and after that I’ll make the next one and so forth (if you are okay with that). I agree to not use more than 4 parts.
I did cut the message in half, and am sure that has something to do with lower scores for the second half. Not sure how much though. It cut a lot of the cycles like a knife.
I will make a message, with the plaintext original something you have never seen before. Use multiple keys, up to 63 symbols and cycle the keys as I encode. I’ll get started on it tonight; maybe finish tonight.
I have made a new measurement for the cycles:
Edit: updated the table.
Full 340: 227
Full 340 mirrored: 202
Full 340 even rows flipped: 212
Full 340 uneven rows flipped: 214
340 uneven rows only: 144
340 even rows only: 109
Two parts:
Part 1: 13118 / 142
Part 2: 13130 / 167
Three parts:
Part 1: 6724 / 137
Part 2: 5984 / 148
Part 3: 6012 / 123
Four parts:
Part 1: 3704 / 100
Part 2: 3492 / 82
Part 3: 4202 / 129
Part 4: 3686 / 116
340 halves:
Part 1: 14892 / 189
Part 2: 13054 / 146
O.k., try this. There are multiple keys. You will have to expand some of the symbols that are not mutually exclusive of one part, and I hope that you will be able to solve it. If you cannot, then I will make another one at your request.
smokie7
3 6 32 11 16 18 9 21 25 12 28 19 36 52 42 38 10
61 5 29 47 16 6 23 14 17 20 20 31 48 12 14 38 4
13 43 21 15 44 13 12 46 43 32 15 33 21 21 37 26 26
1 24 28 39 34 33 34 52 52 10 33 45 44 44 42 38 18
39 27 58 29 40 43 62 15 23 49 17 10 47 52 9 40 41
22 27 35 45 24 15 28 48 18 37 15 19 40 11 16 53 43
9 46 53 28 20 18 45 54 36 29 47 41 45 35 44 43 31
30 46 36 45 49 12 25 47 38 59 42 56 34 26 21 12 33
41 13 2 48 56 48 29 35 34 55 54 37 32 11 13 30 50
5 33 55 8 10 60 24 22 20 44 26 46 25 50 52 53 11
53 31 31 59 41 51 32 4 39 54 35 52 13 50 29 61 11
35 12 20 32 42 6 30 47 9 24 31 40 34 43 6 11 54
32 33 51 15 42 19 27 44 11 52 30 49 28 34 33 19 26
55 33 45 23 47 36 21 3 14 48 3 56 34 1 54 28 42
17 60 8 31 38 29 24 18 44 38 22 9 46 16 38 58 50
5 40 22 7 20 45 21 37 39 30 12 48 34 16 12 2 49
57 18 53 27 29 43 44 49 55 26 50 13 37 52 32 58 27
50 29 46 39 51 24 9 13 12 19 17 16 14 63 23 41 62
39 18 58 28 16 14 29 20 30 40 43 61 17 47 57 11 25
25 5 17 20 28 32 49 35 11 31 40 9 37 22 52 19 10
It is interesting that there appears to be more cycle randomization in the 2nd part, but I also wonder if it could be somewhat related to cutting the message in halves. Are perfectly cycling halves equal for your system?
I did cut the message in half, and am sure that has something to do with lower scores for the second half. Not sure how much though. It cut a lot of the cycles like a knife.
iv been working on the two halves for ages, I have got one line but it led me nowhere. i will dig it out. when having a go at the second half try it without the last line in case filler jams up the process.. best of luck..
Ok smokie, give me some time my new cycle measurement needs some additional work.
Edit: updated the 340 line up table a couple of posts above.