doranchak, zydeco,
At that time I became utterly convinced that some transposition was done after homophonic substitution. I wrote a routine that as you can see in the pictures in this thread works pretty well when it is actual. For a 3×3 transposition the original swap mentioned came out really strong. I now think it’s a fluke that is brought on by the "+" symbol, which is the real culprit because of its abundancy.
I then tried to hill climb the swaps with my solver and found out that just by the degree of freedom, you are able to rearrange the cipher to a high scoring pile of rubbish. Quite embarrassing.
It’s not embarrassing, it’s progress. Every success is preceded by many failures, right? ![]()
I think the space of these kinds of manipulations is very much worth exploring. Z split the 408 into 3 parts, so I could see him slicing and dicing the 340 after authoring it, then transcribing it after performing his manipulations. His choice of which new symbols to add to the 340 was interesting, too, since some of them seem to suggest directional information or some other meaning besides an underlying plaintext letter:




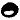

Can you give more details about how you make the measurements in "system 1" vs "system 2"? If you already described them in some other thread, maybe you could just point me there.
Also, I’m trying to visualize the diagonal shifting. Can you point me to an explanation of how you think the shifts are applied to the cipher once it is enciphered? If you shift along a diagonal, do the symbols that fall off the end of the selected region appear on the other end? I’m trying to think about how this operation could be included in a systematic search of the space of possible operations.

Can you give more details about how you make the measurements in "system 1" vs "system 2"? If you already described them in some other thread, maybe you could just point me there.
Also, I’m trying to visualize the diagonal shifting. Can you point me to an explanation of how you think the shifts are applied to the cipher once it is enciphered? If you shift along a diagonal, do the symbols that fall off the end of the selected region appear on the other end? I’m trying to think about how this operation could be included in a systematic search of the space of possible operations.
Since the thread "My work" I have decided to redo everything, retrace my steps. Making progress as you say. I’m currently working on a write-up that starts to explain a few of these things more thoroughly. I’m hoping to have it done by the weekend and then we can go from there, if you like. Thanks. It was meant a possible diagonal shift of information.
Looking forward to it. Thanks!!
I finished the write-up: A counting method for differentiating between cyclic and random symbol assignment and direction of encoding in homophonic substitution ciphers.
Do you agree that the "findings" in the document add to the notion of the 340 being a cyclic homophonic substitution cipher and its legitimacy?
And do you think that by looking at the line chart for the 340 maybe something may be going on? Very high peak at 17, only the rayn cipher comes close. Looks very different from the 408.
Speculation: at first I thought the "+" symbol was not part of the encoding/cipher, which still very well may be (maybe partially so). But after removing it a very big difference is noted between direction 1 and 2 which does not seem to be happening in the other ciphers.
I’m considering if my counting method could serve different purposes. An idea I came up with is to combine them with your brute force search for homophone sequences by removing the associated symbols of a sequence from the cipher and recalculating the sum of the counts of my method. But then we need to come up with a good normalisation that takes into account the number of characters, the numbers of symbols and the distribution of symbol frequencies. If after removing the associated symbols the sum is lower then this could be considered a better match for a homophone sequence. Do you think there is merit in my reasoning? If so would you like to try it?
Yes, the 340 does appear to be cyclic homophonic substitution, but with enough "interruptions" to suggest some other steps being applied during encipherment. My feeling is that some restoration of the original layout might possibly increase the number of ngrams, repeated fragments, and cycles. But as you’ve already noticed, certain transformations that yield favorable measurements are false positives, since they do not yield a solution.
I did notice that your measurement of non-repeats might miss "good" cycles, since the cycles could be interrupted by other repeats. So if you did the sequence removal as you suggested, you would get a more direct measurement of cycles. But doing this makes the computation a bit more complicated, since you have to consider all unique sets of L symbols, where L is the length of the sequence you are trying to detect. Also, in my brute force search, I attempted to normalize by calculating an estimated probability for the sequence to occur naturally, as a way to compare it to other sequences. As the values of L increase for the 408, the number of true positives (real homophone cycles) at the top of the list (sorted by probability) goes up considerably. There is more detail on how I estimate the probabilities here: http://www.zodiackillerfacts.com/forum/ … 906#p22906
Another way to measure the "regularity" of a sequence is to count the totals of all possible substrings of length L within the sequence. Then maybe you can pluck out the one that has the highest count.
Another powerful measurement is cosine similarity, which measures how closely two symbols act like each other. Two symbols may have similar "contexts". That is, the kinds of symbols they tend to follow or precede are very similar. When such similar symbol contexts are found, it indicates the symbols might represent the same plaintext letter. So the cosine similarity explicitly measures this by using a vector of counts. Then the euclidian distance between the vectors is calculated.
To see this calculation in action, go to http://zodiackillerciphers.com/webtoy/stats.html , select the 408 cipher, and click the "Letter contacts" button. The cosine similarity calculations appear under the grid of letter contacts. You can see that some of the symbols pairs with high cosine similarity are true positives and others are false positives. If you combine the measurement with the brute force approach, it can help include/exclude symbol groupings.
So, now I am very curious to know if the same combination of measurements can help to judge candidate manipulations of the 340 ciphertext, in that they would maximize both the improbability of strong sequences occurring, and the cosine similarity of the pairs of symbols within the sequence.
Yes, the 340 does appear to be cyclic homophonic substitution, but with enough "interruptions" to suggest some other steps being applied during encipherment. My feeling is that some restoration of the original layout might possibly increase the number of ngrams, repeated fragments, and cycles. But as you’ve already noticed, certain transformations that yield favorable measurements are false positives, since they do not yield a solution.
Yes, I have been looking at the problem in the same way. A list of possible interruptions I have thought of:
– Nulls. But would this affect ngrams so much?
– Subtle transposition applied during encoding.
– Transposition applied to the cipher in a 20×17 grid and then converted to 17×20. A little bit far fetched perhaps.
– Polyalphabetism? I have not looked at this, have you?
– Columnar transposition after encoding or some sort of transposition after encoding that would mainly be horizontal.
An interesting find was made when putting the 340 in a 20×17 configuration and summing the non repeats.
(Left-to-right, top-to-bottom), (right-to-left, top-to-bottom).
340: 4462, 4638.
340noplus: 4855, 4236.
408: 4692, 3901.
Tonyb2: 4700, 4734. (cyclic cipher from catalog that came closest to the 340)
The best results from my tests with AZdecrypt have been from horizontal transposition schemes (row mirroring in 17×20 and 20×17, random columnar transposition runs. As you know I’m redoing these and the results will slowly become available. This is not just from the amount of combinations generated by those but also from the higher average results. It seems to be that on average the 340 likes to sit just where it is!!!
I have been thinking this may be in favor of my word search theory (not the graysmith) because there would still be some information to be found horizontally. And the "+" symbols and possibly others being the unfilled squares causing the interruption. Would also explain the directional bigram findings by Kevin Knight and the pivots. In my mind, the word search is the best fitting theory for all but maybe I’m suffering from confirmation bias. ![]()
I did notice that your measurement of non-repeats might miss "good" cycles, since the cycles could be interrupted by other repeats. So if you did the sequence removal as you suggested, you would get a more direct measurement of cycles. But doing this makes the computation a bit more complicated, since you have to consider all unique sets of L symbols, where L is the length of the sequence you are trying to detect. Also, in my brute force search, I attempted to normalize by calculating an estimated probability for the sequence to occur naturally, as a way to compare it to other sequences. As the values of L increase for the 408, the number of true positives (real homophone cycles) at the top of the list (sorted by probability) goes up considerably. There is more detail on how I estimate the probabilities here: http://www.zodiackillerfacts.com/forum/ … 906#p22906
Thank you for the information.
Another way to measure the "regularity" of a sequence is to count the totals of all possible substrings of length L within the sequence. Then maybe you can pluck out the one that has the highest count.
Excellent idea! I’ll get on it right away. ![]()
By the way, do you or anyone have some homophonic substitution ciphers that are at least 340 size to expand my catalog? I’m not looking for many ciphers generated by just one algorithm for that matter.
Thanks
Another powerful measurement is cosine similarity, which measures how closely two symbols act like each other. Two symbols may have similar "contexts". That is, the kinds of symbols they tend to follow or precede are very similar. When such similar symbol contexts are found, it indicates the symbols might represent the same plaintext letter. So the cosine similarity explicitly measures this by using a vector of counts. Then the euclidian distance between the vectors is calculated.
I’ve looked at the difference between what symbols tend to follow or preceed and found that the difference here is lower for the 340 (more random) than for any other cipher or that my calculations are flawed. Probably both. ![]()
To see this calculation in action, go to http://zodiackillerciphers.com/webtoy/stats.html , select the 408 cipher, and click the "Letter contacts" button. The cosine similarity calculations appear under the grid of letter contacts. You can see that some of the symbols pairs with high cosine similarity are true positives and others are false positives. If you combine the measurement with the brute force approach, it can help include/exclude symbol groupings.
Okay, an idea. Is it possible, when combining these 2 systems to generate some (multiple variations) best fit homophone sequence to single letter transcriptions? (automaticly, permutating the better results) I mean reduce the cipher to 26 letters from these measurements somehow. If so, we could do this for the 408 and check them in AZdecrypt if it’s possible to come up with a translation (test) and then do the same for 340 and see what variations score the best. If you would be up for this I could run them through AZdecrypt. I would be willing ro run a million variations or so. Just a thought!
So, now I am very curious to know if the same combination of measurements can help to judge candidate manipulations of the 340 ciphertext, in that they would maximize both the improbability of strong sequences occurring, and the cosine similarity of the pairs of symbols within the sequence.
In the context that manipulation/transposition was done after or during encoding?
– Nulls. But would this affect ngrams so much?
– Subtle transposition applied during encoding.
– Transposition applied to the cipher in a 20×17 grid and then converted to 17×20. A little bit far fetched perhaps.
– Polyalphabetism? I have not looked at this, have you?
– Columnar transposition after encoding or some sort of transposition after encoding that would mainly be horizontal.
I think removal of nulls could cause more ngrams or repeated fragments to appear, since they could be changing the lengths of the ngrams when they appear within them.
I haven’t looked at polyalphabetism yet – still plenty of work left to confidently rule out monoalphabetism.
An interesting find was made when putting the 340 in a 20×17 configuration and summing the non repeats.
(Left-to-right, top-to-bottom), (right-to-left, top-to-bottom).
340: 4462, 4638.
340noplus: 4855, 4236.
408: 4692, 3901.
Tonyb2: 4700, 4734. (cyclic cipher from catalog that came closest to the 340)
That’s interesting. I wonder if other measurements also increase under the same rearrangement.
The best results from my tests with AZdecrypt have been from horizontal transposition schemes (row mirroring in 17×20 and 20×17, random columnar transposition runs. As you know I’m redoing these and the results will slowly become available. This is not just from the amount of combinations generated by those but also from the higher average results. It seems to be that on average the 340 likes to sit just where it is!!!
I have been thinking this may be in favor of my word search theory (not the graysmith) because there would still be some information to be found horizontally. And the "+" symbols and possibly others being the unfilled squares causing the interruption. Would also explain the directional bigram findings by Kevin Knight and the pivots. In my mind, the word search is the best fitting theory for all but maybe I’m suffering from confirmation bias.

Yes, the wordsearch idea is still interesting. I wonder if solvers can be modified to solve such layouts, or if the many directions of text would make it infeasible.
By the way, do you or anyone have some homophonic substitution ciphers that are at least 340 size to expand my catalog? I’m not looking for many ciphers generated by just one algorithm for that matter.
In the preparation for my talk I will be generating many test ciphers using an algorithm that maximizes the appearance of 340-like qualities within them. I’ll let you know when they are all ready.
Okay, an idea. Is it possible, when combining these 2 systems to generate some (multiple variations) best fit homophone sequence to single letter transcriptions? (automaticly, permutating the better results) I mean reduce the cipher to 26 letters from these measurements somehow. If so, we could do this for the 408 and check them in AZdecrypt if it’s possible to come up with a translation (test) and then do the same for 340 and see what variations score the best. If you would be up for this I could run them through AZdecrypt. I would be willing ro run a million variations or so. Just a thought!
I have thought about this before as well. I ran a brute force search of "symbol merges" based on the idea but I think the search always fell for false positives, because it wasn’t very sophisticated. I think the Copiale cipher was solved using such a scheme, so the 408 should still be solvable using something like this. But I think we’d still need to figure out what’s going on with the 340 before we can measure how good the candidate merges are. But if we’ve figured out what’s going on with the 340, then it’ll probably already be directly solvable by unfolding the manipulations and feeding the result into the solvers!
So, now I am very curious to know if the same combination of measurements can help to judge candidate manipulations of the 340 ciphertext, in that they would maximize both the improbability of strong sequences occurring, and the cosine similarity of the pairs of symbols within the sequence.
In the context that manipulation/transposition was done after or during encoding?
At the moment, I’m assuming that manipulations were done after the symbols were assigned to the plaintext message. I wonder if we’d still see the same low ngram and homoephone cycle counts if the manipulations had been done before the symbols were assigned.
Speaking of polyalphabetism, smoke treat’s "wildcard" idea here is interesting:
Now I’m wondering if we can identify the best selection of symbols that, when interpreted as wildcards, yields the highest scoring homophone sequences.
EDIT: Oh, I see you already replied there. Very interesting ideas!
[ Yes, the wordsearch idea is still interesting. I wonder if solvers can be modified to solve such layouts, or if the many directions of text would make it infeasible.
I am working on a new version of AZdecrypt that will include different solving modules. The regular speed solving module, a refinement module that can take the output from the speed solver and rescore it with up to 6-grams (much slower) and an "ultra" module that specialises in just solving one cipher (aiming at higher multiplicity and IoC outliers) with visual feedback. That’s the idea, if I can get this to work the way it needs to I’m planning a module for polyaphabetic and word search.
To answer your question. I think it’s possible but it has to be a dense word search.
Right now I’m working on a module with up to 6-grams and it does produce better quality output and bumps the multiplicity slighty. The problem with high multiplicity ciphers now is that my solver can’t find the maximum. For instance I know the plaintext scores almost 5000 but the solver only outputs 4300.

I have been thinking this may be in favor of my word search theory (not the graysmith) because there would still be some information to be found horizontally. And the "+" symbols and possibly others being the unfilled squares causing the interruption. Would also explain the directional bigram findings by Kevin Knight and the pivots. In my mind, the word search is the best fitting theory for all but maybe I’m suffering from confirmation bias. 🙂
I know I’m a bit late to the party, but I’m sure I’m not the only one who might be confused by the reference :), so I thought I’ll ask here instead of sending a private message. I know what you are referring to by "pivots", but what about "bigram findings by Kevin Knight" reference? Are you referring to a particular paper of his? I searched the whole forum and I couldn’t find anything specific enough to point me in the right direction. I’m actually researching some bigram stats in Z340 and comparing them with other ciphers and found a couple of minor oddities, which I’m not sure how to interpret, so this reference piqued my interest quite a bit.

Is it this?
http://ftp.isi.edu/natural-language/peo … iac-11.pdf

“I don’t know Chief, he’s very smart or very dumb.“
Knight gave a talk that mentioned his observations about the bigrams in Z408 and Z340:
http://www.zodiackillerciphers.com/?p=448
The quote of interest is:
He also talked about the unsolved Zodiac 340, and how it has no obvious reading order bias based on analyzing bigrams in several directions: