Would that mean the command line executable has to be restarted for each new variation your main program summons? And thus ngrams have to be reloaded time upon time or can you keep it in memory somehow. Thanks for your ciphers.
For the first version, unfortunately yes. Later I will implement shared memory or named pipes so that the ngrams and the executable needs to be loaded only once. There are also some ways to call c++ directly from python but I have never tried that before. But the first version will support batch solving. I plan to pass most of the gui options via command line parameters. But at the moment I do not have not as much time as I want (had my last week of vacation now).

Would that mean the command line executable has to be restarted for each new variation your main program summons? And thus ngrams have to be reloaded time upon time or can you keep it in memory somehow. Thanks for your ciphers.
For the first version, unfortunately yes. Later I will implement shared memory or named pipes so that the ngrams and the executable needs to be loaded only once. There are also some ways to call c++ directly from python but I have never tried that before. But the first version will support batch solving. I plan to pass most of the gui options via command line parameters. But at the moment I do not have not as much time as I want (had my last week of vacation now).
It looks like you know allot more about programming than I do. How is it going?
At the moment I am working on a "proof of concept" for the solver. First I have tried to port the AZDecrypt code to C++. Unfortunately I have some problems at some points since the FreeBasic source I have is not complete. If you don’t mind I would ask you for your help at some time.
For the moment I have decided to develop an own solver. AZDecrypt is very powerful and incredibly fast (great work!). But it might be a good idea to have another solver with some different approaches too.
Current status of the project:
In the past few days I wrote some code to generate scored ngram corpora from arbitrary text books (e.g. "War And Peace" from Leo Tolstoy). Also I have tried different solving methods. To keep things simple my test case is just a monoalphabetic substitution cipher instead of a homophonic one. Genetic algorithms work well but they are a bit too slow. So I have tried a basic hillclimber which was ok. Next I will give simulated annealing a try. As soon as I get some stable and fast results I will keep my focus on the basic concept of the solver. That is:
What’s next?
I will implement the solver as a server. This means that you can send a cipher via TCP/IP to the solver and get back the score and plaintext. The server can run on local host or on any PC in the Network. This gives you the ability to distribute the workload to all your available hardware. If the solver listens on local host the data transfer should be faster than reading and writing files (I hope so!). It should also be possible to send a batch of ciphers at once.
This means that a user of the solver is not bound to a specific programming language. E.g. you can create test ciphers in FreeBasic, Python, C++ or whatever language you prefer. All you have to do is to send your ciphers via TCP/IP and listen for the results.
I am pretty sure that I can implement all that server stuff. But I also think that other people are much more experienced and skilled in the solver related things. So I think that I will share my project via github as soon as it is in alpha/beta state so that others can contribute.
The only problem is that I am very busy at the moment. So it will take some time…
At the moment I am working on a "proof of concept" for the solver. First I have tried to port the AZDecrypt code to C++. Unfortunately I have some problems at some points since the FreeBasic source I have is not complete. If you don’t mind I would ask you for your help at some time.
For the moment I have decided to develop an own solver. AZDecrypt is very powerful and incredibly fast (great work!). But it might be a good idea to have another solver with some different approaches too.
I’m glad to hear you decided to develop your own solver.
Something I like to think of with solvers is that there exists an intelligence spectrum. Adding more intelligence means that the solver will find the solution in less amount of iterations, but the iterations themself will take longer. I think that AZdecrypt is clearly not-intelligent and I focused heavily on simplicity and cost-effective intelligence mostly in the form of normalization. Is intelligence really intelligent? Or is it just the speed at which it can simulate?
I will implement the solver as a server. This means that you can send a cipher via TCP/IP to the solver and get back the score and plaintext. The server can run on local host or on any PC in the Network. This gives you the ability to distribute the workload to all your available hardware. If the solver listens on local host the data transfer should be faster than reading and writing files (I hope so!). It should also be possible to send a batch of ciphers at once.
This means that a user of the solver is not bound to a specific programming language. E.g. you can create test ciphers in FreeBasic, Python, C++ or whatever language you prefer. All you have to do is to send your ciphers via TCP/IP and listen for the results.
Sounds great!
Just a short project update:
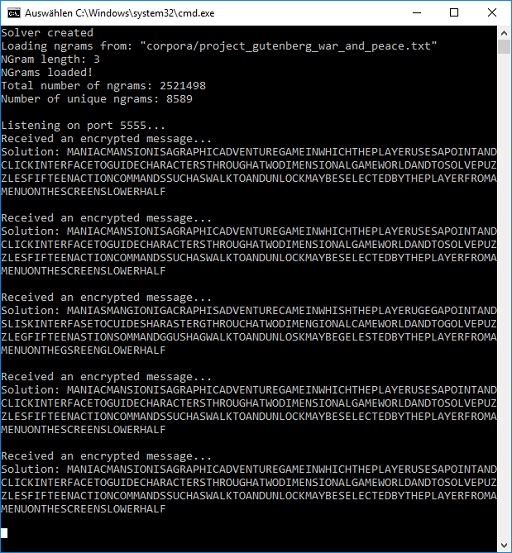
I have implemented the basic functionality of my solver system. The main part is a C++ command line tool which listens on a specific network port for incoming text messages. If a message is received it tries to solve it by simulated annealing. As mentioned before I have implemented only a solver for monoalphabetic substitutions for now. When the text is decrypted the solver sends back the plaintext and the calculated score.
For the ngrams I use a corpus based on "war and peace" from project Gutenberg. Any corpus can be used as long as it contains only letters from A to Z. Numbers are not supported at the moment. The ngrams are generated on the fly when the tool is started. The ngram generation is quite fast (creating 6grams from a 2.5 MB text corpus takes less than 0.5 seconds). Of course this has only be done once.
You can run as many solvers (even on different computers) as you want. All you have to do is to setup some threading mechanism in your client which puts the cipher texts in a queue.
My solver uses the following library: http://zeromq.org
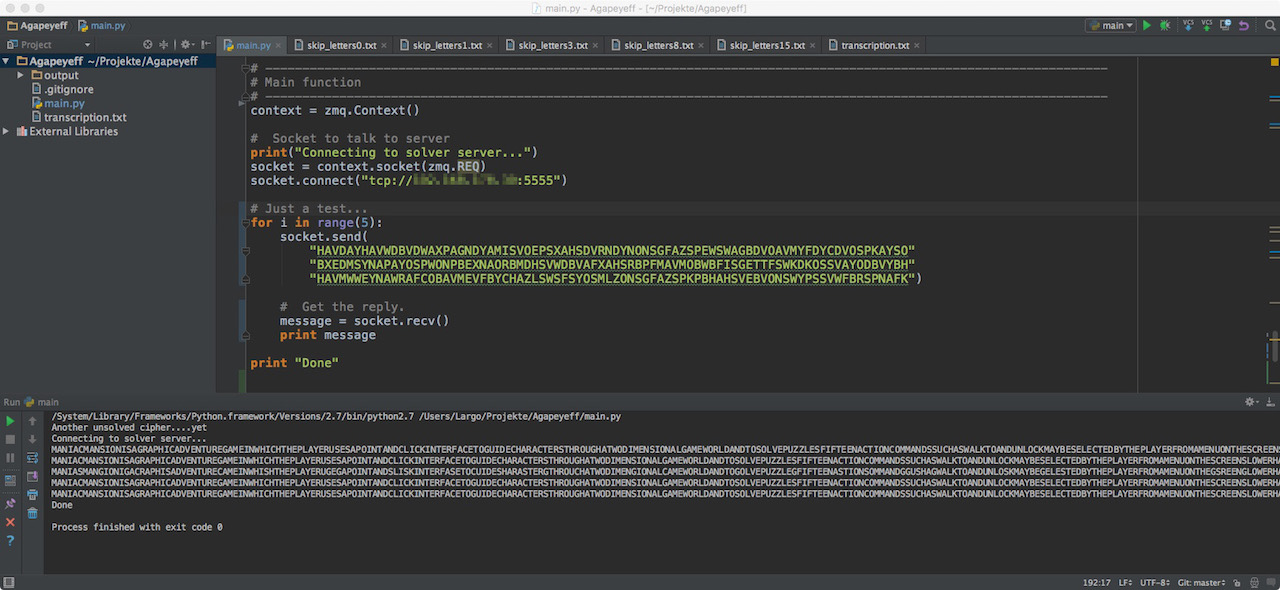
This means that it does not matter which programming language you prefer. Just use the bindings provided from zeromq, send your cipher and receive the result. I have implemented clients in python and c++. If I find the time I will create a FreeBasic sample as well if you are interested Jarlve.
The advantage of such a solver is that you can use it programmatically instead of using a gui. This gives you the ability to use it as a part of a genetic algorithm or whatever algorithm you prefer. If you need some computing power for brute force just start as much solvers on as many machines as possible ![]()
Here are some screenshots from my "Agapeyeff"-Project – (which is another yet unsolved cipher):
Solver (Server-Part, C++) running on my PC:
Solver (Client-Part, Python) running on my Mac:

Really nice work, Largo – thanks so much for sharing this! I really like the idea of having all these different solvers available to us. It’d be nice to run them in parallel to attack ciphers, especially if one of them can find a solution that the others can’t.
Looks very nice Largo. You are very well organized.
My solver uses the following library: [
The advantage of such a solver is that you can use it programmatically instead of using a gui. This gives you the ability to use it as a part of a genetic algorithm or whatever algorithm you prefer.
This sounds great and just like what I am looking for. Is the initial code up on github?
This sounds great and just like what I am looking for. Is the initial code up on github?
Unfortunately not. A couple of weeks ago I stopped working on z340 and at the moment I don’t have time to refactor my source code. If I find some time I can pick the most important (server/client) part and post it. But atm I can’t promise.
Here is a link to a github repository that I’ve used as a starting point:
https://github.com/leejacobson/SimulatedAnnealingTSP
The corresponding article (very informative and well written):
http://www.theprojectspot.com/tutorial- … eginners/6
You should be able to adapt the source code so that it can solve a monoalphabetic substitution. That’s how I started.
Here is some code to create NGrams from a plaintext file (plaintext should consinst only of letters A-Z in upper case, otherwise use a regex when reading the file)
// --------------------------------------------------------------------------------------
struct NGramInfo
{
int count;
double logValue;
NGramInfo(int count, float logValue)
{
this->count = count;
this->logValue = logValue;
}
};
typedef unordered_map<string, NGramInfo> NGramMapDescription;
typedef NGramMapDescription::iterator NGramMapIterator;
NGramMapDescription m_NGramMap;
// --------------------------------------------------------------------------------------
void Solver::createNGramMapFromFile(string filename, int nGramLength)
{
cout << "Loading ngrams from: "" << filename << """ << endl;
cout << "NGram length: " << nGramLength << endl;
m_nGramLength = nGramLength;
m_totalNGramCount = 0;
m_uniqueNGramCount = 0;
FILE *fileptr;
char *buffer;
long filelen;
// Funky Funky Oldschool =)
fileptr = fopen(filename.c_str(), "rb"); // We don't use fopen_s because the code must be platform independent
fseek(fileptr, 0, SEEK_END);
filelen = ftell(fileptr);
rewind(fileptr);
// Read the entire file into a buffer
buffer = (char *)malloc((filelen + 1) * sizeof(char));
fread(buffer, filelen, 1, fileptr);
fclose(fileptr);
int nGramCount = filelen / nGramLength;
int nGramEntryLength = sizeof(int) + nGramLength;
char *pTemp = new char[nGramLength];
NGramMapIterator it;
// Create a map which contains all unique ngrams and their counts
for (int i = 0; i < filelen - nGramLength; i++)
{
m_totalNGramCount++; // TODO: this is +1 in original python code. Check!
memcpy(pTemp, buffer + i, nGramLength);
it = m_NGramMap.find(pTemp);
if (it != m_NGramMap.end())
{
it->second.count++;
}
else
{
m_NGramMap.insert(make_pair(pTemp, NGramInfo(1, 0)));
m_uniqueNGramCount++;
}
}
// Calculate the logarithm of each ngram frequency in the corpus.
it = m_NGramMap.begin();
while (it != m_NGramMap.end())
{
it->second.logValue = log((double)it->second.count / m_totalNGramCount);
it++;
}
// Calculate a default value for any ngram that does not appear in the corpus
m_minLogFrequency = log(0.01 / m_totalNGramCount);
cout << "NGrams loaded!" << endl;
cout << "Total number of ngrams: " << m_totalNGramCount << endl;
cout << "Number of unique ngrams: " << m_uniqueNGramCount << endl;
}
I hope this helps a bit
Thank you!
