Shall I add yours to the list?
Thank you, that would be great. For the moment the repository is only accessable by invitation. In a few weeks I will make it public and send you the link.
For the 340, it shows spikes at period 19 and 57. And after mirroring or flipping period 15 and 260. Here’s my current implementation.
Thank you for sharing the source Jarlve!
I would like to explain my ambitions about sharing code in an open repository because I have a feeling that I had affronted some people. Maybe it’s the lack of my english, sometimes it is hard for me to explain everything in a language which is not my native language.
I defenitely don’t want to compete with this forum. It’s a great place to share ideas and results and I am glad that so many people are working together on the cipher. My goal just was to have all the implementations in one place. Imagine I wrote a test that rules out a specific transpositioning idea and David will add the test result to his encyclopedia of observations. What if I have a bug in my implementation? Maybe an idea is ruled out but could lead to a solution if the bug is fixed. Ok, this is a very hypothetical story but such things can be prevented by making code open source so that everyone can experiment with it.
I really like the way how people are sharing their ideas in this forum and I am glad to be a part of that community. Since I am working as a software developer (game developer for several years, now developing applications) I just wanted to share my experience with distributed versioning control systems like „git“. Didn’t meant to turn everything upside down or take control of all the code. For me it sounds good to have your tools, Davids tools, smokies tools, mine and all the others in a big repository. If something new is implemented one clicks the „push to repository“ button and the others click „pull“ to get all the new stuff.
I’ve learned so many things here so I would like to give something back. That is another reason why I share my whole source code.
No matter how we are working together….main thing is to get this cipher solved.
I will try to help where I can. I’m hoping to present everyone’s progress at this year’s crypto symposium (it’s in October). Even if there’s no solution yet, you have all found good clues in the cipher that I hope to expose to a wider codebreaking audience.
Can’t wait to see a new presentation from you. I really like the one from the 2015’s symposium which you have posted on youtube.
This year the „European Historical Ciphers Colloquium“ will take place in Bratislava, Slovakia (May 18-19). Last year this symposium was in Kassel, Germany and I was there and I will defenitely visit the event in Slovakia too. The organizer asked for presentations and I considered to participate. I don’t have problems to talk to the audience but I think I don’t have enough background in the topic yet. All I could do is to share the things that all the people in this forum have found out if no one minds. What do you think David? I could help by exposing a summary of all the clues to the european audience.
Link to the colloquium:
http://scienceblogs.de/klausis-krypto-kolumne/2016/12/08/historical-ciphers-colloquium-2017-save-the-date-an-hand-in-a-presentation/#more-11586

It’s an alternative to bigram repeats for gauging plaintext direction. It does not use repeats directly. I’ve called it symmetry shift but that may not be a good name. My idea was that in language you have bigrams like "IN" that are very common, but its reversed counterpart "NI" may be less common. The same with words, language information is not palindromic by default. So the algorithm basicly scans for each symbol in the cipher all symbols that come before it and all symbols that come after it and then finds the difference. A larger difference should then be more indicative of plaintext direction.
I am interested in this idea, and think that it should be tested more. It would be interesting to know if the most common bigrams appear at the beginning of words instead of at the end of words, in general. Or vice versa. If the most common bigrams appear at the beginning of words, then the list of symbols that follow them would be shorter than the list of symbols that precede them. Or vice versa.
Test plaintext without transposition or encoding, starting with the highest frequency bigram and work your way down the list. Locate each bigram, and make a list of the plaintext that appear immediately ( not sure exactly how many ) before and after the bigram. Some bigrams, like TH, appear at the beginning of high frequency words. So there should be more, different plaintext appearing before TH and less, different plaintext appearing after TH.
Find some way to tabulate, add up or compare all stats for all of the highest frequency bigrams so that the information can be used to determine plaintext direction. Then start homophonic encoding with more and more symbols to find out just how many symbols in a key it takes, how efficient of a key you need, to make detection of plaintext direction impossible.
Either that, or just use the algorithm that you already have. Have you tested it much?
Other experiment coming soon.

I would like to explain my ambitions about sharing code in an open repository because I have a feeling that I had affronted some people. Maybe it’s the lack of my english, sometimes it is hard for me to explain everything in a language which is not my native language.
I defenitely don’t want to compete with this forum. It’s a great place to share ideas and results and I am glad that so many people are working together on the cipher. My goal just was to have all the implementations in one place. Imagine I wrote a test that rules out a specific transpositioning idea and David will add the test result to his encyclopedia of observations. What if I have a bug in my implementation? Maybe an idea is ruled out but could lead to a solution if the bug is fixed. Ok, this is a very hypothetical story but such things can be prevented by making code open source so that everyone can experiment with it.
I really like the way how people are sharing their ideas in this forum and I am glad to be a part of that community. Since I am working as a software developer (game developer for several years, now developing applications) I just wanted to share my experience with distributed versioning control systems like „git“. Didn’t meant to turn everything upside down or take control of all the code. For me it sounds good to have your tools, Davids tools, smokies tools, mine and all the others in a big repository. If something new is implemented one clicks the „push to repository“ button and the others click „pull“ to get all the new stuff.
I’ve learned so many things here so I would like to give something back. That is another reason why I share my whole source code.
No matter how we are working together….main thing is to get this cipher solved.
Hey Largo,
You have not affronted me and your english is fine. I don’t get the impression you want to compete with the forum or whatever. The repository just doesn’t feel right for me. That said, I do want to help you with all your projects in any way I can manage. Thanks for your code but I feed on ideas mainly. And yes, the main thing here is to solve the 340.
Either that, or just use the algorithm that you already have. Have you tested it much?
Not really, I should invest some time in fine tuning it.
Then start homophonic encoding with more and more symbols to find out just how many symbols in a key it takes, how efficient of a key you need, to make detection of plaintext direction impossible.
In that regard I have observed two simple rules. The higher the multiplicity, the higher the chance of incorrect results from measurements. And the effectiveness of a measurement is proportional to the amount of information it can draw from.
Either that, or just use the algorithm that you already have. Have you tested it much?
Not really, I should invest some time in fine tuning it.
Then start homophonic encoding with more and more symbols to find out just how many symbols in a key it takes, how efficient of a key you need, to make detection of plaintext direction impossible.
In that regard I have observed two simple rules. The higher the multiplicity, the higher the chance of incorrect results from measurements. And the effectiveness of a measurement is proportional to the amount of information it can draw from.
K the experiment is underway. I really like the above symmetry around symbols idea.
Jarlve, in the thread http://zodiackillersite.com/viewtopic.php?f=81&t=3206&start=40 you posted two chunk based ciphers. One with size 7 which I had solved brute force and one yet unsolved.
This could be fun, can anyone find the chunksize I used?
…
I was just wondering if anyone could figure out the chunksize somehow. I suggest not trying to solve it.
I tried to solve those ciphers without brute force by using genetic algorithms. For the fitness function I used a weighted score for bigrams and trigrams. „Weighted“ means that I did not only counted the ngrams but weighted their occurence. A bigram which repeats 6 times in a ciphertext is much more worth that 5 bigrams which only repeats twice each. Two repeated trigrams are more worth than 5 bigrams and so on. I think one of you had talked about such weighted score in a different thread too. First I measured the solved „chunk size 7“ chipher. It scored 188.0 points in my system.
Unfortunately this is not the highest score that can be reached by shuffeling the chunks. It is possible to get a score > 220.0. So my approach did not work since random shuffles can score very high.
After this flop I tried another thing. Maybe a flop too, but looks promising to me:
I ran some period 1 to period 30 tests on various ciphers but I did not count the pure repeated bigram count. Instead I used my weighted ngram score. z340 still showed peaks at period 19 and flipped period 15. Next I compared cyclic versus non cyclic ciphers (ABCABCABC vs BACCBBACA). To me it was a bit surprising that some of the non cyclic ciphers scored higher at period 1 than the ones with perfect cycles.
Most of the texts that I had tested („I LIKE KILLING…“ and some other ones) showed a linear decrease of the score when applying period 1, 2 and 3 and an increase at period 5 and 9.
After these tests I ran some tests with a cipher which contained only names. Guess what? Period 1 peak vanishes and the curves are similiar to z340. So maybe period 19/15 is not the result of a transposition (as you mentioned earlier too). Maybe it is a phenomenon which is caused by the type of the plaintext. On the other hand the period 19 / 15 peaks in z340 are still way too high. But imagine some sort of symmetry like „KILLEDXYZ – ME:2 – SFPD:0 KILLEDABCD – ME:3 – SFPD:0“. Some letters that correlate at specific positions may be a reason for the period 19/15 spikes.
z340 flipped left to right, containing names and places….is it that easy? (I know…names and places had been discussed before)
Here is a .pdf which contains my results. I hope its self-explaining:
https://www.dropbox.com/s/amdawndv7qyqf1b/period_n_observations.pdf?dl=0
(second page of the pdf: z340 was flipped left to right before measuring)
Oh…and by the way. Here are two of the ciphers from my test which contains only names. I think you had solved such a cipher before. But unfortunately I can get no solve with AZDecrypt, even when I adjust the solver values. Maybe I am not familiar enough with finetuning AZDecrypt.
55 Symbols:
XwQbZKDEIXVxnmfsx
dlh3oCLqHZwFgvMzT
JSEeYaiNOaDcmIhjo
jpkbVRrqGwFXnSxDC
AIEtHvdgGVhkUyeMz
FBnJSfZPaiYcW1jrO
EplnwsmLNDtAdoqC3
BrHRXPMYIgVU1kWCH
bv3zwMaJFSeyf3lAY
LuiCZdO3BxjmRupHX
goGDsEbjeIVNiMcKF
wYjpCqtSbankvNzEF
xDHMcSIrVa3waJUae
jADOdcmEZYoF3Pxjq
uIgNvSzki4VnJyrOE
C1fmpHMbNNenoYqXi
jsLhRwCajdDhcAgpH
jbMZxkvzaJdgeYICH
nOFMijmXhYjVCZwHp
okubdgeDaU3IMqXWv
62 Symbols:
XwQbZKDEIXVxnmfsx
dlh0oCLqHZ2FgvMzT
JSEeYaiNOawc3Dhjm
jpk4IRroGVFXnSx25
AwEtCq9dGDhgUybHv
FBnzSfZPaeMcW+jrJ
Ei7nIsO8NVtAk3mY0
lr5LXBCH29wRUdPMY
po0qD5avFS4yf0WAC
+ubHZgz07xjJ8ueMX
kOGIsEijpV2N4YcKF
w5jbC3tSean9mNoEF
xDHMcSIrVa02aqLai
jAwvdczEZYJF0lxjO
uDgN3Smkp1InoyrqE
5Rfv4CHbNNenzMJXi
jsUh+VYaj92hcAdp5
j4CZxgO3amk9bHwMY
noF5ejqXhCjDHZIMi
vdupgk4Va802YzXBJ
Jarlve, in the thread http://zodiackillersite.com/viewtopic.php?f=81&t=3206&start=40 you posted two chunk based ciphers. One with size 7 which I had solved brute force and one yet unsolved.
I tried to solve those ciphers without brute force by using genetic algorithms. For the fitness function I used a weighted score for bigrams and trigrams. „Weighted“ means that I did not only counted the ngrams but weighted their occurence. A bigram which repeats 6 times in a ciphertext is much more worth that 5 bigrams which only repeats twice each. Two repeated trigrams are more worth than 5 bigrams and so on. I think one of you had talked about such weighted score in a different thread too.
I think it is called bigram ioc, or BIC. If a bigram repeats 7 times then it would score 42, unique_bigram_repeat*(unique_bigram_repeat-1). It can then be normalized in various ways but the raw value should do.
First I measured the solved „chunk size 7“ chipher. It scored 188.0 points in my system. Unfortunately this is not the highest score that can be reached by shuffeling the chunks. It is possible to get a score > 220.0. So my approach did not work since random shuffles can score very high."
It still may allow you to weed out a good percentage of the combinations that need to be tested.
I ran some period 1 to period 30 tests on various ciphers but I did not count the pure repeated bigram count. Instead I used my weighted ngram score. z340 still showed peaks at period 19 and flipped period 15. Next I compared cyclic versus non cyclic ciphers (ABCABCABC vs BACCBBACA). To me it was a bit surprising that some of the non cyclic ciphers scored higher at period 1 than the ones with perfect cycles.
This may be due to that your non cyclic ciphers have random symbol selection and thus produce a unigram frequency table that is less flat. The repeat potential of a cipher is heavily related to its index of coincidence. I usually use the raw value to get a feeling. It’s 2236 for the 340.
So maybe period 19/15 is not the result of a transposition (as you mentioned earlier too). Maybe it is a phenomenon which is caused by the type of the plaintext. On the other hand the period 19 / 15 peaks in z340 are still way too high. But imagine some sort of symmetry like „KILLEDXYZ – ME:2 – SFPD:0 KILLEDABCD – ME:3 – SFPD:0“. Some letters that correlate at specific positions may be a reason for the period 19/15 spikes.
I would say the chances are very small, trying to come up with such a plaintext will undoubtely create many bigram repeats at period 1 because of all the repeating words. I don’t think there’s a single sensible 340 length plaintext in the world which has more repeats at period 19 than period 1.
z340 flipped left to right, containing names and places….is it that easy? (I know…names and places had been discussed before)
Seems not:
HRAEHOSEANBARTEEL ANDIGERTOMASNELRA DLESHANTAMOLINSTE RDELLARDNITABERRI NEALLAROSHAMELICK NORTRESHITAARBETR SHEENANNORAMCDLOS CHULERAKLASANDRAN DAKITNERREMLDLIGH TTERGERALDBLNOAET ADIEDREROSEMONELO RELLEIAEOISDEANGR ETANNEROSALSTICKE LLMANNEDARONBARAA LTOMONTESCASIONET RACINEBRANDEEDENS HASETARLGSKOHLENE RANNELIAANTESTALL NSTIEARKEMEGTHERS LADSITAMEIERALOIT
Nice .pdf and graphs. I knew about the peak at 5 in the 408.
Here is the solution to your names cipher. I was also unable to solve it with any of the regular ngrams so I created special ones: https://drive.google.com/open?id=0B5r0r … 0RQZTljR28 that work with the latest AZdecrypt. Click on file and then load ngrams.
Spoiler alert: DAVIDFARADAYBETTY LOUJENSENDARLENEM ERRINMIKEMAGEAUCE CILIASHEPARDBRYAN HARTNELLPAULSTINE ROBERTDOMINGOSCHE RIOBATESKATHLEENJ OHNSDONNALASSLONN IEJEANMERRITTJOHN SWINDLEJOYCESWIND LEPATRICIAAKINGFR ANCINETRIMBLEKERR YANNGRAHAMJAMESMI CHAELGERDNERJOYCE WALKERELISABETHER NSTEINNIKKIBENEDI CTSUSANMCLAUGHLIN CINDYLEEMELLINANN BERNICEDUNCANDANI ELWILLIAMSJANEDOE
So maybe period 19/15 is not the result of a transposition (as you mentioned earlier too). Maybe it is a phenomenon which is caused by the type of the plaintext. On the other hand the period 19 / 15 peaks in z340 are still way too high. But imagine some sort of symmetry like „KILLEDXYZ – ME:2 – SFPD:0 KILLEDABCD – ME:3 – SFPD:0“. Some letters that correlate at specific positions may be a reason for the period 19/15 spikes.
The period 15 / 19 repeats could be caused by a route transposition, but probably not a keyed columnar transposition. With route transposition, the plaintext is inscribed into a geometric shape, then read off in some direction and inscribed into another geometric shape. The message sender and receiver know what the inscription and transcription shapes are, and the inscription, reading and transcription directions are.
Keyed columnar transposition is similar in that the plaintext is inscribed into a complete or incomplete rectangle, and then read off in columns while transcribing into the final message format. Usually in groups of 5 plaintext because that works better when sending messages via flag or some other type of signal device during a battle. But keyed columnar transposition rearranges the columns before reading them off, and unless there is some type of pattern to the rearrangement, which is possible I suppose, the period 1 bigrams are all mixed up and difficult to detect.
With route transposition, the columns or rows are not rearranged, and the period 1 bigrams become separated at the width or height of the inscription shape, depending on the reading direction.
So far, the 340 could be a route transposition, a keyed columnar transposition with a pattern like key, or a bifid. It is important to note the correspondingly low count of period 1 repeats as compared to the period 15 / 19 repeats. A straightforward homophonic cipher that does not diffuse the plaintext efficiently should show higher counts of period 1 repeats and lower counts of period 15 / 19 repeats. What we see is the exact opposite.
It is possible to make a homophonic cryptogram not transposed with low count of period 1 repeats and high count of period 19 repeats, but you would have to start with a plaintext message with a high count of period 19 repeats without any transposition. Then find the letters that are more predominate in the period 1 repeats and diffuse them more than the letters that are more predominate in the period 19 repeats. It is unlikely that he did that, considering that if he did, then the message would have already been solved.
Largo, if you can find another classical cipher that creates a detectable period, definitely let us know. Trifid could do it.

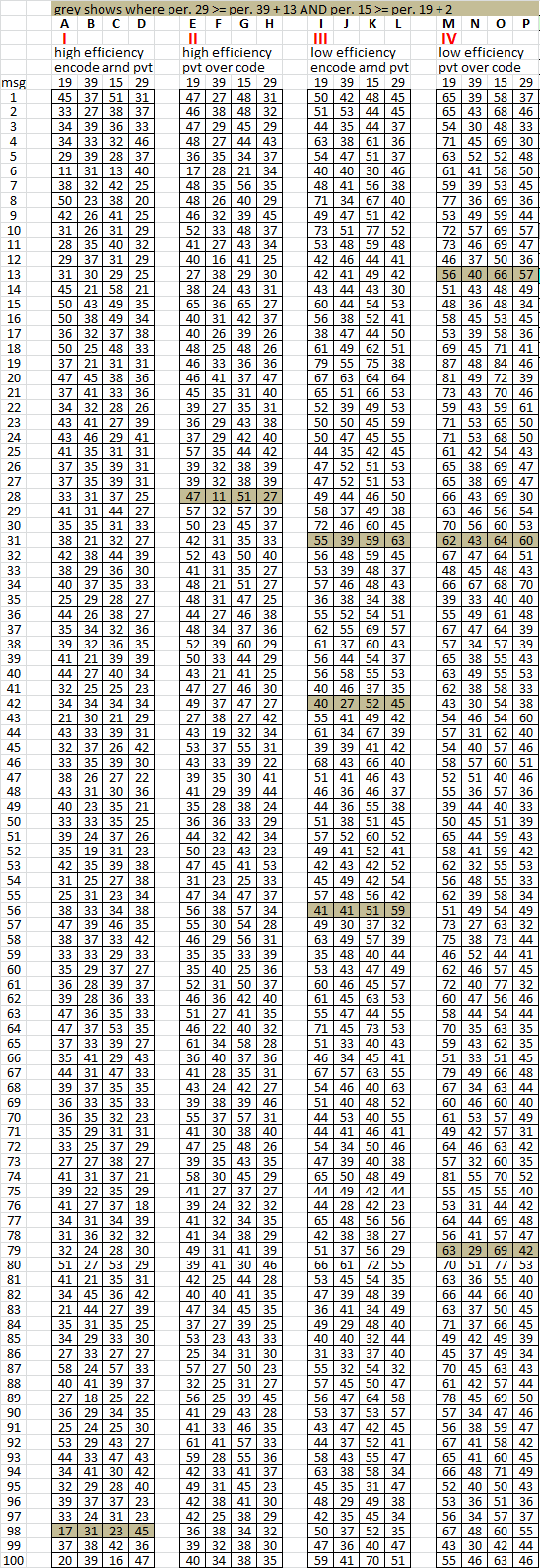
I went down a side track and did a study of the effect of periodic bigrams on pivots:
It shows that simply having more bigrams at period 39 will cause pivot pairs to appear more often, but they are still quite rare.
Now I have that off my plate so I can try to catch up with this thread! ![]()
8. Experiment: Feasibility of pivot verticals as nulls; key efficiency relationship to period 15 / 19 bigram repeats; effect of reading a mirrored message
I made 400 cryptograms in an experiment to figure out if I could make a message with 340 bigram repeat stats, but add the vertical pivot symbols during transcription or encoding, which would make a big distortion area around the pivots. The experiment also explores the relationship between the count of period 19 repeats and key efficiency, and spike effects caused by reading a message in the wrong direction.
1. The messages are all period 19, with an incomplete 18 x 19 inscription rectangle and 340 plaintext. The inscription rectangles are all 17 x 20. During transcription or encoding, vertical pivot symbols are added in columns 5 and 10. Then transcription or encoding continues around the vertical pivot symbols which are basically nulls creating distortion areas and misalignments in an untransposed message. See the Visual Clue Pivot Hypothesis: viewtopic.php?f=81&t=3196&start=30. Scroll down to see it all.
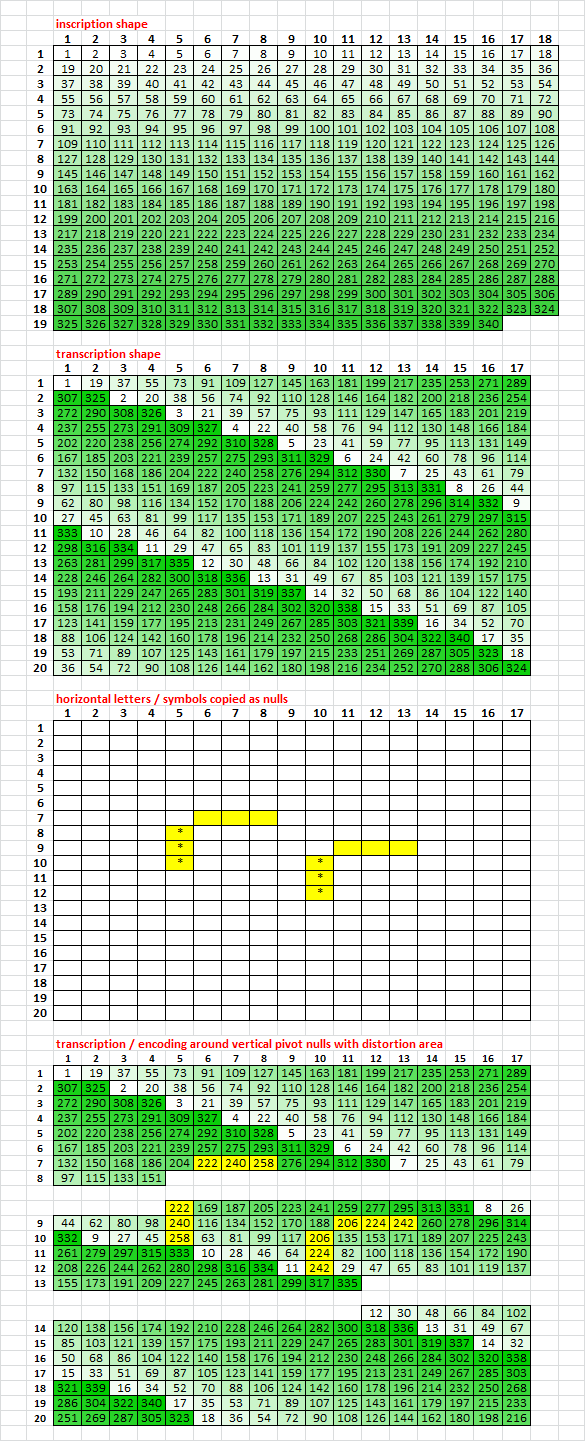
2. For other messages, the vertical pivot symbols are drafted over the transcribed and encoded symbols, replacing them. There is no distortion area or misalignments in an untransposed message. Scroll down to see it all.
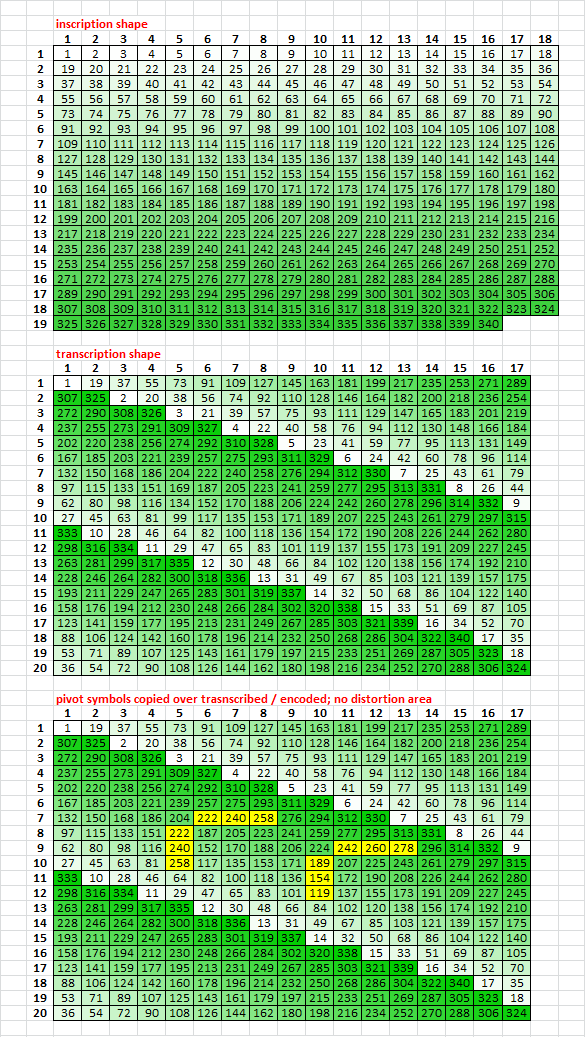
The idea is to try to figure out if the pivots are nulls causing a distortion, is it possible to make a message with 340 period 19 repeat stats.
3. I also used two different types of keys. Example of efficient key left, which diffuses high frequency plaintext more and low frequency plaintext less. Example of inefficient key right, which diffuses high frequency plaintext less and low frequency plaintext more.
4. I used all perfect cycles for four groups of 100 messages. One of each of Jarlve’s plaintext library, in four different ways:
Group I: Transcription / encoding around pivot verticals, with efficient key.
Group II: Pivot verticals drafted over transcription / encoding with efficient key.
Group III: Transcription / encoding around pivot verticals, with inefficient key.
Group IV: Pivot verticals drafted over transcription / encoding with inefficient key.
I also made one symbol map to three plaintext to simulate the + for count, cycling, and representation in period 19 bigram repeats.
I didn’t use random symbol selection, although I could have, so that I could make straight comparisons.
5. I rotated all messages 180 degrees to put the pivots exactly where they are in the 340, counted the period 19 and 39 repeats, and mirrored the messages and counted the period 15 and 29 repeats.
6. My spreadsheet counts all "repeats" AB AB AB as three instead of two as is usual for others, but that is just the way it works. 340 stats:
67 period 19
49 period 39
69 mirrored period 15
62 mirrored period 29 ( a big spike when reading the message right left top bottom instead of left right top bottom )
Thank you for checking my idea and for your answers Jarlve and smokie!
I tried to find some more explanations for period_n spikes. Two nulls after each 17th letter obviously leads to a p19 spike if the nulls are substituted properly. But at the moment my head is spinning because of excessively working on the cipher for a too long time. For now I’ll take a period 7 days off ![]()
Largo, if you can find another classical cipher that creates a detectable period, definitely let us know. Trifid could do it.
I’ll give it a try soon after taking a short break. This book contains some nice ideas for transpositioning schemes (I have the german version):
https://www.amazon.de/Codes-Ciphers-Secrets-Cryptic-Communication/dp/1579124852
Then transcription or encoding continues around the vertical pivot symbols which are basically nulls creating distortion areas and misalignments in an untransposed message
I like this idea!
This may be due to that your non cyclic ciphers have random symbol selection and thus produce a unigram frequency table that is less flat. The repeat potential of a cipher is heavily related to its index of coincidence. I usually use the raw value to get a feeling. It’s 2236 for the 340.
You’re right! Now I understand the "phenomenon"
Here is the solution to your names cipher. I was also unable to solve it with any of the regular ngrams so I created special ones: https://drive.google.com/open?id=0B5r0r … 0RQZTljR28 that work with the latest AZdecrypt. Click on file and then load ngrams.
Your solution is correct, great work!
I had created an ngram file for AZDecrypt 1.0 too, but mine had not worked. As source for the corpus I used this: http://www2.census.gov/topics/genealogy/1990surnames/
Maybe I have a bug in my ngram creator. I’ll check that later.
7. O.k., this is going to be a little bit tedious, so I tried to make it as easy as possible to quickly digest with shaded cells. Group I and II used efficient keys and none of those messages had 67 period 19 repeats. Groups III and IV used inefficient keys, and there were a lot of messages with 67 or more period 19 repeats.
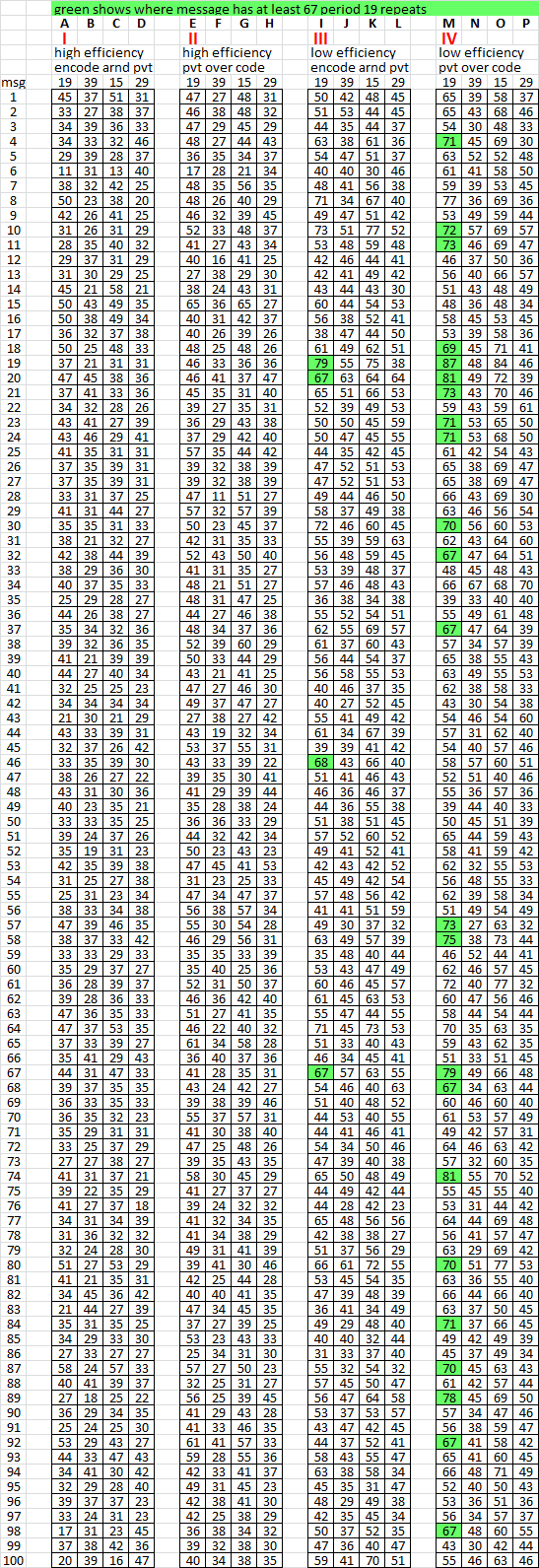
This shows that using an efficient key does not create as many period 19 repeats as an inefficient key and it is likely that Zodiac used an inefficient key.
8. This compares the period 19 repeats for groups I and III ( pivot verticals as distortion nulls ) with groups II and IV ( pivot verticals drafted over encoded messages ).
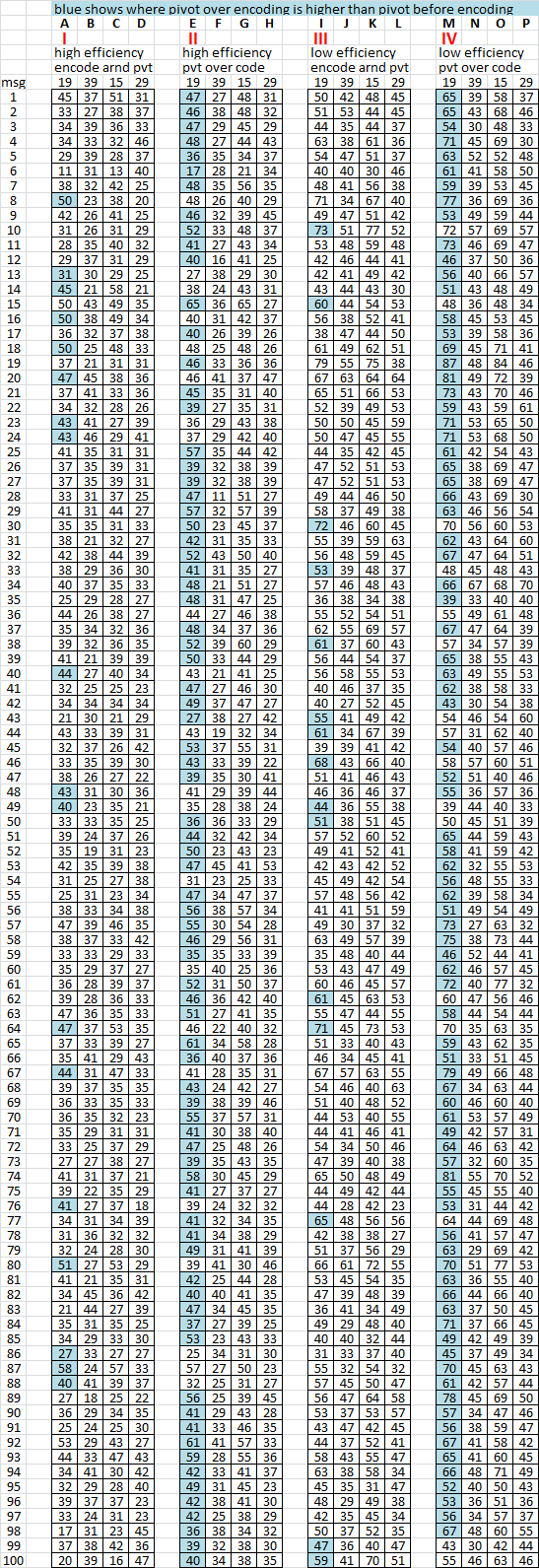
This shows that in most messages with pivot verticals as distortion nulls, the period 19 repeat count was lower. And with messages where the pivot symbols were drafted over encoded symbols, and without any distortion areas, the period 19 repeat counts were higher. The distortion area is big, and makes a big difference in period 19 repeat counts. Therefore, it is unlikely that Zodiac transcribed or encoded around the pivot symbols.
9. Here I mirrored all of the messages and counted the period 15 repeats. Look at group IV on the right. There were 35 messages that had more mirrored period 15 repeats than period 19 repeats. Example marked blue: Message 1 had 65 period 19 repeats and only 58 mirrored period 15 repeats. But message 2 had 65 period 19 repeats and 68 mirrored period 15 repeats.
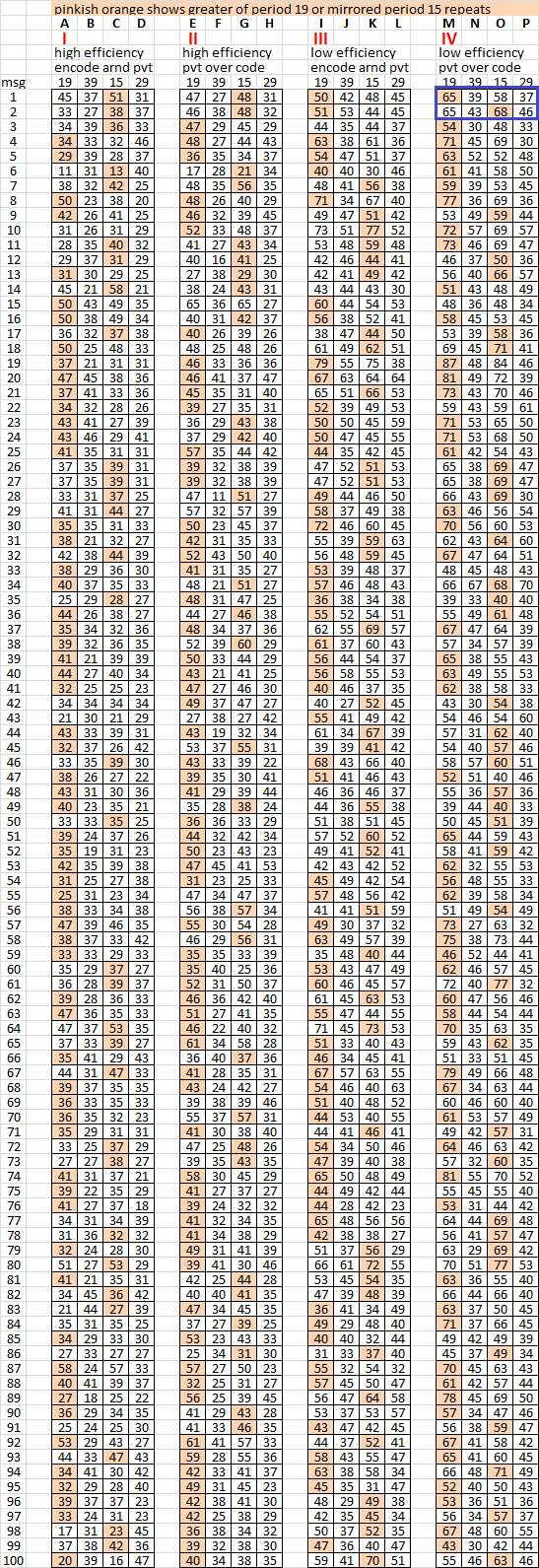
This shows that reading a message in different directions changes the count of bigram repeats. The correct way to read the messages here is left right top bottom, but when read in the wrong direction, right left top bottom, about 1/3 of the time you will get more period 15 repeats than period 19 repeats.
10. This one shows a comparison of period 39 repeats and mirrored period 29 repeats. In group IV, 50 of the messages had more mirrored period 29 repeats than period 39 repeats, even though the message is correctly read left right top bottom. That is because period 5 bigrams that occupy the rightmost and left most columns in a 17 x 20 rectangle, become period 29 bigrams when the rectangle is mirrored.
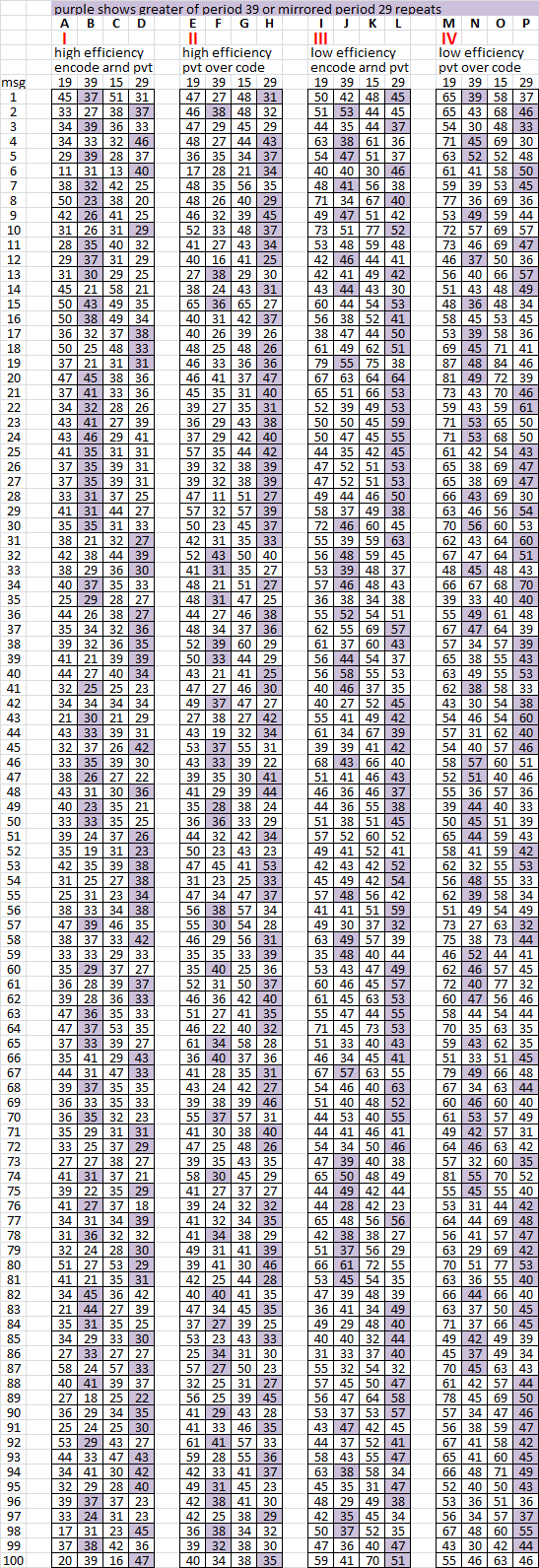
11. But what about such a massive spike? There are 49 period 39 repeats, but 62 mirrored period 29 repeats in the 340. Below shows the messages where the difference is at least 13. Seven messages in group 4 have a spike comparable to the 340.
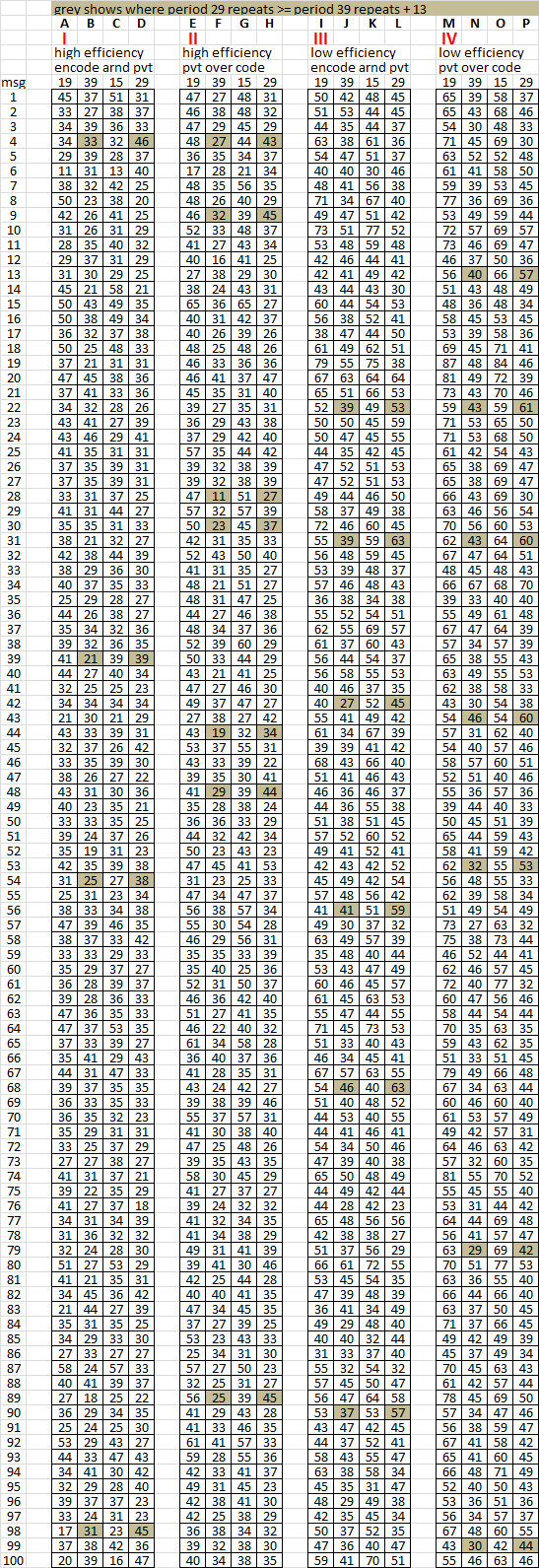
This shows that only one spike when reading the message right left top bottom is not necessarily an indicator of plaintext transcription direction.
12. And finally, the messages where there was an increase in both mirrored period 15 AND period 29 repeat counts when reading right left top bottom. There were much fewer of these, but it is possible.
Here is smokie2017.1. It is message #31 from Jarlve’s plaintext library, group IV, which has period 15 / 19 and period 39 / 29 repeat stats similar to the 340 regarding differences when reading left right top bottom or right left top bottom.
40 39 42 25 3 13 24 2 41 12 52 26 51 57 54 49 12
7 53 12 21 15 9 55 54 32 63 50 14 37 13 45 12 14
31 1 30 52 40 53 12 39 36 38 5 48 13 6 3 8 25
47 62 2 4 41 12 49 24 51 29 12 14 37 13 36 40 55
39 38 41 35 56 50 37 58 11 61 1 54 48 36 26 53 12
47 25 49 23 34 32 52 14 22 46 38 10 48 3 44 2 9
57 7 43 31 42 6 20 24 12 37 8 26 1 13 12 33 55
36 12 44 51 50 28 14 13 38 17 59 12 14 37 7 47 36
49 13 40 35 34 38 25 40 56 54 24 12 11 8 53 21 12
39 41 40 52 14 30 39 23 23 3 45 32 51 22 37 50 2
7 21 31 6 16 27 12 14 8 25 55 5 24 1 58 54 3
13 33 12 43 40 23 14 7 12 15 13 53 47 52 38 37 10
36 51 22 12 12 2 6 19 18 1 21 14 30 8 26 3 57
39 13 25 9 55 22 7 48 38 24 47 30 63 49 54 2 37
36 1 12 53 50 38 17 12 26 20 12 21 3 4 11 14 13
12 41 62 10 55 2 54 56 40 14 42 39 23 22 32 64 37
61 9 60 25 41 36 24 13 6 40 53 59 39 12 55 54 38
31 1 11 12 26 53 37 3 10 48 12 47 52 25 8 41 35
24 40 14 29 30 51 32 2 28 50 1 7 16 19 39 18 52
21 31 30 9 49 6 48 36 51 34 50 13 47 12 15 27 33
Here are the repeats, looking very similar to the 340:

Here is the tracing map and it should easily solve with this EDIT: rotate the message 180 degrees before applying tracing map:
1 19 37 55 73 91 109 127 145 163 181 199 217 235 253 271 289
307 325 2 20 38 56 74 92 110 128 146 164 182 200 218 236 254
272 290 308 326 3 21 39 57 75 93 111 129 147 165 183 201 219
237 255 273 291 309 327 4 22 40 58 76 94 112 130 148 166 184
202 220 238 256 274 292 310 328 5 23 41 59 77 95 113 131 149
167 185 203 221 239 257 275 293 311 329 6 24 42 60 78 96 114
132 150 168 186 204 222 240 258 276 294 312 330 7 25 43 61 79
97 115 133 151 169 187 205 223 241 259 277 295 313 331 8 26 44
62 80 98 116 134 152 170 188 206 224 242 260 278 296 314 332 9
27 45 63 81 99 117 135 153 171 189 207 225 243 261 279 297 315
333 10 28 46 64 82 100 118 136 154 172 190 208 226 244 262 280
298 316 334 11 29 47 65 83 101 119 137 155 173 191 209 227 245
263 281 299 317 335 12 30 48 66 84 102 120 138 156 174 192 210
228 246 264 282 300 318 336 13 31 49 67 85 103 121 139 157 175
193 211 229 247 265 283 301 319 337 14 32 50 68 86 104 122 140
158 176 194 212 230 248 266 284 302 320 338 15 33 51 69 87 105
123 141 159 177 195 213 231 249 267 285 303 321 339 16 34 52 70
88 106 124 142 160 178 196 214 232 250 268 286 304 322 340 17 35
53 71 89 107 125 143 161 179 197 215 233 251 269 287 305 323 18
36 54 72 90 108 126 144 162 180 198 216 234 252 270 288 306 324
Takeaways: Using inefficient keys that diffuse high frequency plaintext less create a lot more period 19 repeats, and using efficient keys does not create 340 period 19 stats; the pivot verticals are probably not nulls drafted into the message during transcription or encoding because they create a distortion area that lowers the count of period 19 repeats, and reading a message in the wrong direction can result in an increase in period x bigrams, including a spike similar to the period 29 spike in the 340.
