
Randomization results for unigram and bigram repeats 340 versus 408. It is interesting to see just how low 18 unigram repeats is for the 340, out of more than 1 million randomizations the lowest value was 23. You can see that the 340 shows a slightly higher potential for repeats than an equal part of the 408. It shows that the (raw) ioc is a good indicator for repeat potential of a cipher.
340, unigrams, 1040400 randomized samples: -------------------------------------------------- - Summed: 48041919 - Average: 46.17639273356402 - Lowest: 23 - Highest: 72 340, bigrams, 1040400 randomized samples: -------------------------------------------------- - Summed: 20576958 - Average: 19.77792964244521 - Lowest: 4 - Highest: 42 408, 17 by 20, bigrams, 1040400 randomized samples: -------------------------------------------------- - Summed: 19201209 - Average: 18.45560265282584 - Lowest: 3 - Highest: 39 408, 17 by 20, unigrams, 1040400 randomized samples: -------------------------------------------------- - Summed: 47340361 - Average: 45.50207708573625 - Lowest: 22 - Highest: 71
Hi jarlve..I spent an hour trying your new program after work on Friday and love it.. Nice to see results delivered up as you go.. Interestingly I ran the 340 and a three word sentence in the last line popped out. "City will pay". Interesting because I have seen that before..not sure if it’s of any further work..

Hey smokie, I have briefly glanced over the thread before. Can you summarize?
Basically there is a big coincidence count spike at period 78, or a lot of period 78 unigram repeats. The strange thing is that many of them are made up of other bigram repeats at other periods. There are some period 26 bigram repeats, on a period of 78. And there are some period 39 bigram repeats on a period of 78. And 26 and 39 are divisors of 78. However, I checked I think 100 messages in doranchak’s message library, and there were about a half dozen with period n bigram repeats on a period of m.
Here they are. The symbol at position 17 is exactly the same as the position at position 95, etc.
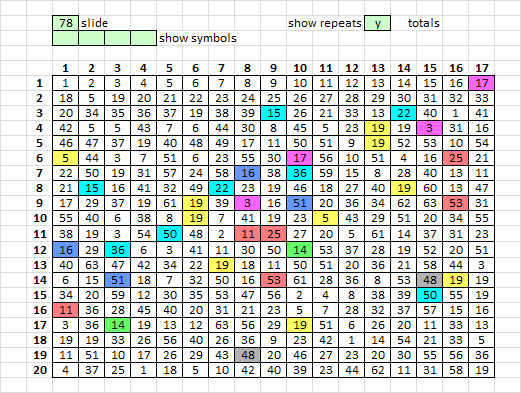
I would call this a period 10 unigram repeat.
If you open the 340 in AZdecrypt and click on stats -> sequential you will see a statistic called midpoint shift. The measures how much symbols have shifted away from the midpoint of the cipher, which is about position 170.
Midpoint shift: - Raw: 7703 - Normalized: 0.2665397923875433At 0.266 it is quite low for the 340 and I believe this softly rules out non-trivial polyalphabetism at the encoding level and also regional bias of cycles.
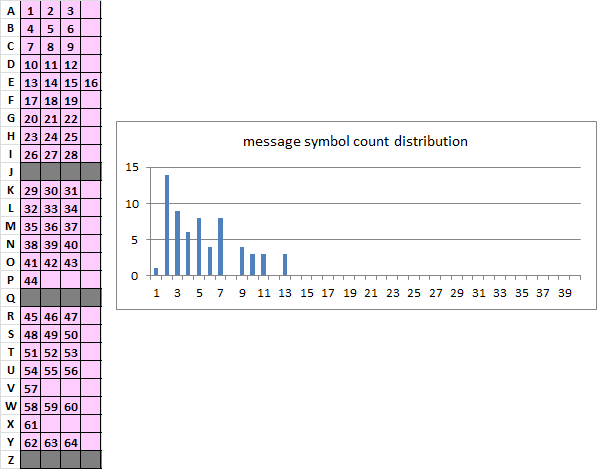
My hypothesis for the encoding is that Zodiac mainly tried not to repeat symbols in a certain view window and that it is from left-to-right, top-to-bottom. There are a couple of measurements that are suggestive of this. There are only 18 unigram repeats. The 408 in a 17 by 20 grid has 21.
We would expect the 408 to be lower in unigrams repeats than the 340 because the raw index of coincidence score is a good indication for the potential of repeats. The raw ioc for the 408 is 2108 and for the 340 it’s 2236. So the question then is, why does the 340 @ 63 symbols has more potential for repeats than an equal part of the 408 @ 54 symbols?
The answer simply is that the 340’s key (unigram symbol frequencies) is less flat and the flatness measurement is available in AZdecrypt under stats -> unigrams.
I remember you discussing something like this before, regarding encoding and Zodiac making an effort at not repeating the same symbol in each row. Not sure if I understand the midpoint shift stat. You are looking at the overall distribution of the symbols, and saying that they are generally distributed about evenly on each side of the middle of the message? That if he changed his key at halfway through the message, then the distribution would be less even? Some symbols would appear more in the first half, and some more in the second half?
Not sure if we are on the same page, but here are all of the unigram repeats. X axis = period, y axis = count of repeats at period x. It does seem that the values on the far left side of the chart are low compared to the other areas of the chart. On the right it is more spiky.
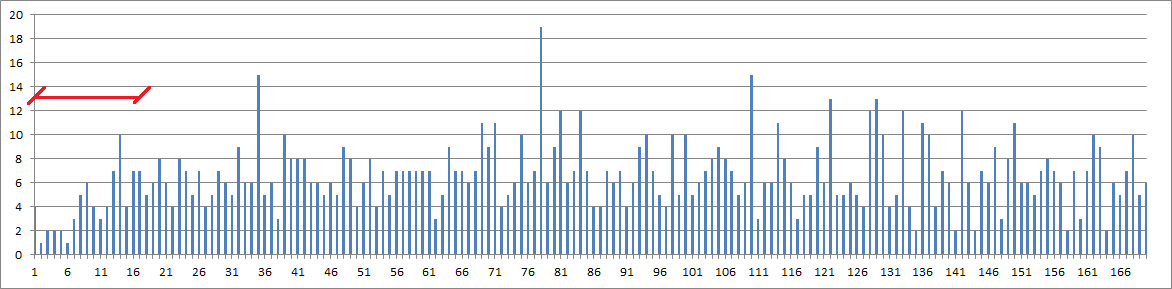
Simply the 340 is less cyclic because he was trying more to not repeat symbols in rows or some similar window, instead of keeping with the cycles. ?
The answer simply is that the 340’s key (unigram symbol frequencies) is less flat and the flatness measurement is available in AZdecrypt under stats -> unigrams.
CODE: SELECT ALL
408, 17 by 20, flatness: 0.854241338112306
340, 17 by 20, flatness: 0.6685691569412501Ok, but then why is the key of the 340 less flat than the 408? The high occurance of the "+" symbol plays part in that but in general the key of 340 just has a lower flatness. Given the low midpoint shift and no real other strong indications of polyalphabetism (to my knowledge) one could assume that the selection of symbols was just more random (no extensive cycling). Which follows the logic of the hypothesis and observation.
When I think of key flatness, I think of efficiency. This to me would be an example of a key that is not very flat, but diffuses the plaintext very efficiently, the objective of homophonic substitution:
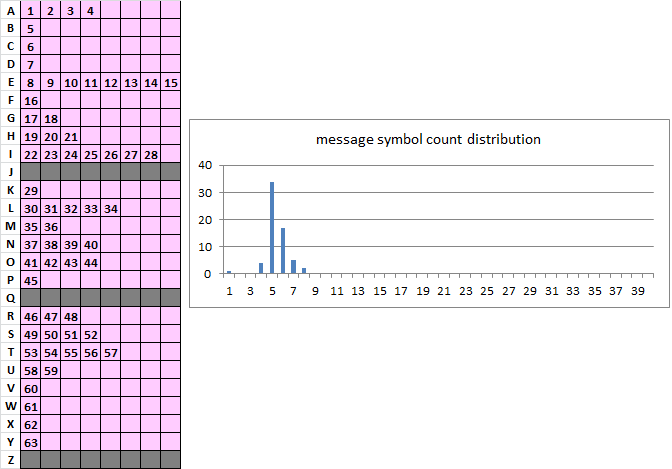
This key to me is flat, because it looks flat and does not diffuse the high frequency plaintext, such as the letter "e" very efficiently. I find it much easier to make homophonic messages with high period 1 bigram counts using an inefficient key. Or, if the plaintext is transposed at period n, to make homophonic messages with high period n bigram counts using an inefficient key.
I think that you are describing the relationship between key efficiency and the count of unigram repeats at low periods. I will think it over.
This is a pretty tough problem.
We have explored a lot of different ideas, and sometimes raced into whatever direction when doing so. I like to mull things over for a while before I start working on a project. Think about different projects and choose them selectively when I am feeling it. I have an unknown number of spreadsheets now. Sometimes, unfortunately, I start working on a concept and vaguely remember doing it before. Then I go back to look at my work and I discover that I did. I am trying to stay open minded, and starting to look at our past work for new ideas or revisions of those ideas.
I honestly have no idea what he did, but I have some ideas about what he probably did not do.
The pivots, out of all of the strange things about the 340, probably bother me the most.
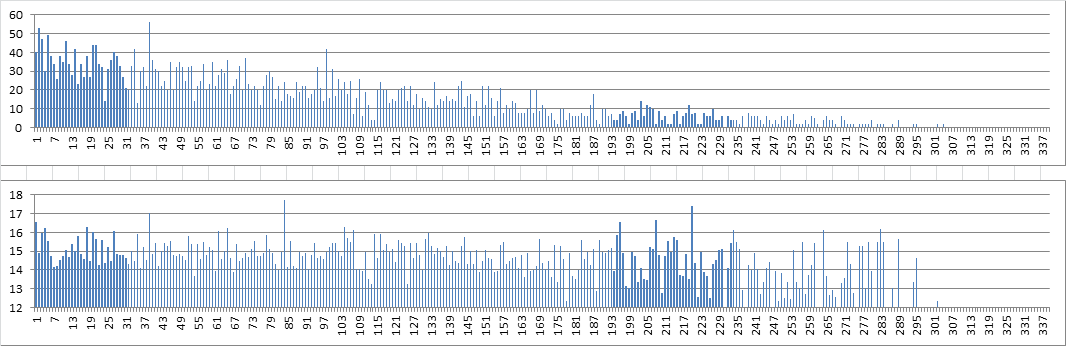
340 reading top bottom right left OR bottom top left right, bigram repeats counts at top and mean probability scores at bottom.
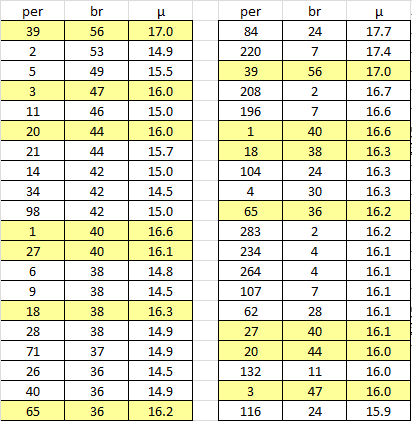
Period 39 is what looks like period 15, 19 and 41 with the other directions. And there is the predicted spike on the mean probability score chart lining up with period 39. The mean probability score chart also has spikes at periods 84, 196, 208, and 220. Note that there was a spike at period 220 with reading the 340 top bottom right left.

The comparison is a bit surprising. There are a lot of periods that are in the top twenty for both bigram repeat count and mean probability score. Does this suggest a way to detect the direction of plaintext transcription?

Is there a way to detect transcription direction for a route cipher message?
1. Let’s say we have a 17 x 20 inscription rectangle, left, and a 17 x 20 transcription rectangle on the right.
2. And we inscribe left right top bottom and transcribe top bottom left right.
3. And then we encode cyclic homophonic.
Is there a way to detect that?
Basically there is a big coincidence count spike at period 78, or a lot of period 78 unigram repeats. The strange thing is that many of them are made up of other bigram repeats at other periods. There are some period 26 bigram repeats, on a period of 78. And there are some period 39 bigram repeats on a period of 78. And 26 and 39 are divisors of 78. However, I checked I think 100 messages in doranchak’s message library, and there were about a half dozen with period n bigram repeats on a period of m.
It’s interesting. In the 408 unigrams repeats peak at period 49 and coincidence count at offset 49, so there must be some relation here. But in the 340 unigrams repeats peak at period 26 and coincidence count at offset 78 and 262. smokie1 cipher (purple haze message) unigram repeats peak at period 40 and coincidence count at offset 120 and 220. Coincidence counts in homophonic substitution ciphers seem to peak at factors of the unigram repeat period peak. And these peaks seems to occur naturally, as an opposition of the low unigram repeats at period 1.
I think we are on the same page about unigram repeats peak but I count from 1 to 17, 2 to 18, 3 to 19,… I believe this continuous method is more thorough.
I remember you discussing something like this before, regarding encoding and Zodiac making an effort at not repeating the same symbol in each row. Not sure if I understand the midpoint shift stat. You are looking at the overall distribution of the symbols, and saying that they are generally distributed about evenly on each side of the middle of the message? That if he changed his key at halfway through the message, then the distribution would be less even? Some symbols would appear more in the first half, and some more in the second half?
Yes, you understand correctly and that is what I have emperically observed.
Simply the 340 is less cyclic because he was trying more to not repeat symbols in rows or some similar window, instead of keeping with the cycles. ?
Yes, I think he did not attempt cycling at all. He just tried not to repeat symbols per row or view window. This achieves everything we know about the encoding.
– Low unigrams
– No extensive cycling
– High unique sequence peak (26 repeats @ length 17)
– Lower flatness of the key (because if he did not cycle, symbol selection becomes more randomly)
Smokie, I will reply to your other posts later on. Interesting stuff.
When I think of key flatness, I think of efficiency. This to me would be an example of a key that is not very flat, but diffuses the plaintext very efficiently, the objective of homophonic substitution:
I’m sorry, I used key flatness but meant symbol flatness. Say, we have a cipher 25 characters long that are 5 symbols each having a frequency of 5. The distribution is perfectly flat and frequency analysis is not possible. In that way, the 340 is less flat than the 408.
This key to me is flat, because it looks flat and does not diffuse the high frequency plaintext, such as the letter "e" very efficiently. I find it much easier to make homophonic messages with high period 1 bigram counts using an inefficient key. Or, if the plaintext is transposed at period n, to make homophonic messages with high period n bigram counts using an inefficient key.
Yes, because an inefficient key raises the raw ioc, which is a good indicator of repeat potential (higher = more). Be it unigrams or bigrams. You can calculate the raw ioc by multiplicating the frequency of each symbol by its own frequency minus one.
1-gram frequencies > 0: -------------------------------------------------- +: 24 * (24-1) = 552 B: 12 * (12-1) = 132 p: 11 * (11-1) = 110 |: 10 * (10-1) = 90 O: 10 * (10-1) = 90 ... Sums up to 2236 for the 340.
This is a pretty tough problem.
We have explored a lot of different ideas, and sometimes raced into whatever direction when doing so. I like to mull things over for a while before I start working on a project. Think about different projects and choose them selectively when I am feeling it. I have an unknown number of spreadsheets now. Sometimes, unfortunately, I start working on a concept and vaguely remember doing it before. Then I go back to look at my work and I discover that I did. I am trying to stay open minded, and starting to look at our past work for new ideas or revisions of those ideas.
I honestly have no idea what he did, but I have some ideas about what he probably did not do.
The pivots, out of all of the strange things about the 340, probably bother me the most.
Yeah, it is a hard problem. What you do with spreadsheets is amazing.
340 reading top bottom right left OR bottom top left right, bigram repeats counts at top and mean probability scores at bottom.
The comparison is a bit surprising. There are a lot of periods that are in the top twenty for both bigram repeat count and mean probability score. Does this suggest a way to detect the direction of plaintext transcription?
I double checked your bigram results and also get the peak @ 39 for top-to-bottom, right-to-left. In AZdecrypt this translates to Columnar 2 -> untranspose. I don’t understand fully what you mean with the comparison, don’t bigrams on their own indicate plaintext direction? And what are these mean probability scores? Thanks
Is there a way to detect transcription direction for a route cipher message?
1. Let’s say we have a 17 x 20 inscription rectangle, left, and a 17 x 20 transcription rectangle on the right.
2. And we inscribe left right top bottom and transcribe top bottom left right.
3. And then we encode cyclic homophonic.
Is there a way to detect that?
With step 2, I assume you mean taking the plaintext in the normal reading direction as input and then output it in columns starting in the upper-right corner (which in AZdecrypt is columnar 2 -> transpose).
p7.txt:
ithasbeeninterest ingovertheyearsto workwithdifferent gamedevelopersand developmentteamsa syoucanprobablyte llbymanyofthegame siveworkedonimmor eathomewithindepe ndentdevelopersba ckinthedaysofwork ingwithidsoftware therewouldbeadeci siontobemadeandit wouldbemadeverysh ortlyaftertheneed foradecisionmorer ecentlyinworkingw ithbradcarneyonwr ackidsuggestsomet
Now apply your example transposition:
nrsauiwsvoiteotoi wkiflsaoemveaphvt riotdirfleelmedeh anneboewowwlsrira cgmrentopiobasfts kwotmthretrysafhb iirhaoekrhkmyneee dteedbrisieaodrye shrneeenbndnudeen ubeevmwgadoycenai grceeaowcenoavtrn gaedrduikpifnegst ednfyeltiemtplate sctosadhnnmhromor talrhnbitdoeopewe sryaodedhergbmdos onidriaseneaaeert menettdodtambnvki eywclwefadteltewn tooiyoctyehsytlig
Now instead of moving on to step 3 let’s take a look at bigram repeats with stats -> plaintext direction 1a:
AZdecrypt plaintext direction 1a stats for: p7.txt -------------------------------------------------- Attempts to recover the plaintext direction from the source. Normal: 135 Mirror: 132 Flip: 132 Reverse: 135 ------------------------------- Columnar 1 (transposed): 135 Columnar 2 (transposed): 132 Columnar 3 (transposed): 132 Columnar 4 (transposed): 135 ------------------------------- Diagonal 1 (transposed): 134 Diagonal 2 (transposed): 138 Diagonal 3 (transposed): 138 Diagonal 4 (transposed): 137 Diagonal 5 (transposed): 137 Diagonal 6 (transposed): 138 Diagonal 7 (transposed): 138 Diagonal 8 (transposed): 134 ------------------------------- Columnar 1 (untransposed): 190 Columnar 2 (untransposed): 197 <--- Columnar 3 (untransposed): 197 <--- Columnar 4 (untransposed): 190 ------------------------------- Diagonal 1 (untransposed): 126 Diagonal 2 (untransposed): 127 Diagonal 3 (untransposed): 129 Diagonal 4 (untransposed): 131 Diagonal 5 (untransposed): 131 Diagonal 6 (untransposed): 129 Diagonal 7 (untransposed): 127 Diagonal 8 (untransposed): 126
See that columnar 2 and 3 (untransposed) are highest, columnar 3 is the reverse string of columnar 2.
Now apply encoding while trying to match the raw ioc of the 340, in this example it is less though:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 11 20 21 3 4 22 23 24 25 26 27 28 29 30 12 2 6 10 15 31 11 2 32 33 34 13 21 24 23 35 36 29 37 38 39 40 41 14 26 7 16 42 43 21 3 44 17 2 45 46 47 24 48 34 1 12 22 49 50 10 51 4 8 52 15 3 53 18 14 12 24 12 29 44 13 15 2 54 8 27 20 29 41 55 6 48 29 37 22 23 19 44 29 53 24 54 38 36 40 26 31 12 34 13 56 51 2 11 8 17 13 45 10 35 48 54 23 3 29 44 39 34 13 23 39 41 39 35 39 57 31 36 40 1 58 51 13 23 59 24 43 60 4 31 14 54 61 40 38 27 50 62 2 46 13 23 37 16 18 61 36 39 22 45 9 15 2 38 47 4 40 31 48 56 5 55 19 63 11 32 39 26 60 8 12 34 56 1 32 54 13 21 15 17 23 24 12 63 33 27 15 36 3 46 12 10 8 37 35 29 38 38 24 29 44 14 24 16 2 12 37 33 48 29 39 41 50 15 31 22 40 16 63 36 7 40 3 48 54 45 22 56 26 35 29 34 44 62 51 24 31 10 8 14 1 55 35 2 6 4 8 13 38 34 27 37 13 23 48 12 24 36 38 40 15 15 31 16 56 12 4 24 41 39 25 53 11 40 54 42 61 21 43 26 52 27 35 15 34 33 12 40 18 1 15 22 10 17 54 14 46 12 54 26 29 3 54 15 21 50 47
And output stats -> plaintext direction 1a via AZdecrypt again:
AZdecrypt plaintext direction 1a stats for: p7.txt -------------------------------------------------- Attempts to recover the plaintext direction from the source. Normal: 29 Mirror: 27 Flip: 27 Reverse: 29 ------------------------------- Columnar 1 (transposed): 16 Columnar 2 (transposed): 16 Columnar 3 (transposed): 16 Columnar 4 (transposed): 16 ------------------------------- Diagonal 1 (transposed): 15 Diagonal 2 (transposed): 20 Diagonal 3 (transposed): 21 Diagonal 4 (transposed): 16 Diagonal 5 (transposed): 16 Diagonal 6 (transposed): 21 Diagonal 7 (transposed): 20 Diagonal 8 (transposed): 15 ------------------------------- Columnar 1 (untransposed): 34 Columnar 2 (untransposed): 37 <--- Columnar 3 (untransposed): 37 <--- Columnar 4 (untransposed): 34 ------------------------------- Diagonal 1 (untransposed): 21 Diagonal 2 (untransposed): 22 Diagonal 3 (untransposed): 19 Diagonal 4 (untransposed): 17 Diagonal 5 (untransposed): 17 Diagonal 6 (untransposed): 19 Diagonal 7 (untransposed): 22 Diagonal 8 (untransposed): 21
Columnar 2 and 3 (untransposed) still peak. Plaintext direction correctly identified.
Something that I wonder about.
There are 37 bigrams at period 19 for the 340. But after mirroring or flipping the 340 there are 41 at period 15. Usually the direction with more bigrams is the correct one so I wonder what could have happened, here a few hypotheses.
– Mirroring or flipping the plaintext in a 17 by 20 grid was the last step in the transposition process.
– The plaintext was transcribed in a 17 by 20 grid from right-to-left, top-to-bottom or left-to-right, bottom-to-top.
– The plaintext was inscribed in a 17 by 20 grid from right-to-left, top-to-bottom or left-to-right, bottom-to-top.
Simply the 340 is less cyclic because he was trying more to not repeat symbols in rows or some similar window, instead of keeping with the cycles. ?
Yes, I think he did not attempt cycling at all. He just tried not to repeat symbols per row or view window. This achieves everything we know about the encoding.
The question is: why would he do that and if he did, whey then did he still make three of these ++?
The first part I can understand. Let’s say he wanted to make the encoding process faster and easier. So he encoded one row ( or whatever window ) at a time, one plaintext at a time. Say he wanted to encode the letter A in row 1. He encoded all of the letter As in row 1 at the same time. Then he encoded all of the letter Bs in row 1 a the same time. And so on with D, E, F etc. if they were in row 1. This process instead of switching letters with every position 339 times. It would be faster, and mean possibly starting over a lot with each cycle group, or some variation of that. Maybe you would get some cycling, but definitely not perfect.
I agree that he probably transcribed right left top bottom or right left bottom top because of the higher count of repeats reading the message in those directions. However, there are at least two different configurations of each period.
For example, period 1, if cut by the edge of the message, when mirrored, becomes period 33.
Period 5 when cut by the edge of the message, when mirrored, becomes period 29. There are several period 5 bigrams in the normal orientation, that when mirrored create period 29 repeats. There are a lot of period 5 bigram repeats in the normal orientation to begin with. Is that caused by the cipher and then do they make the spike at mirrored period 29?
Or, if what you say is correct and he transcribed right left top bottom or right left bottom top, then what creates the period 29 repeat spike? Your experiment above showed that you can start with 197 repeats at period 1 and after transposition and diffusion there are only 37 repeats. So what period was period 29 before transposition? Even periods 2 or 3 would be diffused so much that they would be unlikely to be detectable.
Of course the pivots are mirrored period 29. So it is very baffling.
So I am thinking about not giving as much weight to any bigram repeat that has symbols cut by any edge of the message and looking at the probability scores of the bigrams that do not cross over any edge of the message. I am thinking about probability of the bigram repeats like this one, which makes me think that the last line is not gibberish and that he may have transcribed left right bottom top. I believe that there may be some details, when taken together, give us some more clues.

I am adding to my to do list on the first post. Today I will be adding "digraph at a distance" and "delete the pivots".
A playfair cipher encodes period 1 bigrams, but one variation could be to encode period n bigrams. Why couldn’t you inscribe the plaintext into a 15 x 22 rectangle, then encode vertically? Then re-draft into 17 columns. Could that create what we are looking at?
Or a handful of gibberish symbols in the body of the message could be creating misalignments in the untransposed message. What about the pivots? What if he put the pivots there first as a clue that it was a transposition cipher because they point horizontally and vertically. And he put two of them in there to make sure they were noticed. And then he inscribed the transposed message around them?
But I don’t want to change the subject too much.

Here are the period 5 repeats, that when the message is read right left top bottom or left right bottom top become period 29 repeats. That’s part of the spike, and the pivots are the other part of the spike.
I will have to find the symbols that cause the period 15 repeat count to increase over the period 19 repeat count when the message is read mirrored.
The question is: why would he do that and if he did, whey then did he still make three of these ++?
The first part I can understand. Let’s say he wanted to make the encoding process faster and easier. So he encoded one row ( or whatever window ) at a time, one plaintext at a time. Say he wanted to encode the letter A in row 1. He encoded all of the letter As in row 1 at the same time. Then he encoded all of the letter Bs in row 1 a the same time. And so on with D, E, F etc. if they were in row 1. This process instead of switching letters with every position 339 times. It would be faster, and mean possibly starting over a lot with each cycle group, or some variation of that. Maybe you would get some cycling, but definitely not perfect.
I suppose he made the key before applying the encoding with the "+" symbol being a 1:1 substitute. I like your variation of cycling per row or window, worth exploring.
I agree that he probably transcribed right left top bottom or right left bottom top because of the higher count of repeats reading the message in those directions. However, there are at least two different configurations of each period.
For example, period 1, if cut by the edge of the message, when mirrored, becomes period 33.
I don’t understand what you mean by "if cut by the edge of the message" and "two different configurations of each period". Do you mean left-to-right versus right-to-left? I don’t see how that translates period 1 into 33.
Or, if what you say is correct and he transcribed right left top bottom or right left bottom top, then what creates the period 29 repeat spike? Your experiment above showed that you can start with 197 repeats at period 1 and after transposition and diffusion there are only 37 repeats. So what period was period 29 before transposition? Even periods 2 or 3 would be diffused so much that they would be unlikely to be detectable.
Of course the pivots are mirrored period 29. So it is very baffling.
With the 340’s potential for repeats I would say that on average periods 2 and 3 would still be detectable. Though there would probably be other periods that would randomly be higher that have no correlation with the plaintext direction. It is you who showed that period 2 repeats after transposition and misalignment can shift away. Not all the repeats shift away, just a handful of them and that does the trick.
So I am thinking about not giving as much weight to any bigram repeat that has symbols cut by any edge of the message and looking at the probability scores of the bigrams that do not cross over any edge of the message. I am thinking about probability of the bigram repeats like this one, which makes me think that the last line is not gibberish and that he may have transcribed left right bottom top. I believe that there may be some details, when taken together, give us some more clues.
I still don’t get what you mean by "cut by any edge". Perhaps you will find something?
A playfair cipher encodes period 1 bigrams, but one variation could be to encode period n bigrams. Why couldn’t you inscribe the plaintext into a 15 x 22 rectangle, then encode vertically? Then re-draft into 17 columns. Could that create what we are looking at?
Feel free to create one of these I’ll surely take a look at it and give my thoughts. I think that in general 15 by 23 or 23 by 15 is very interesting because this is period 15.
Or a handful of gibberish symbols in the body of the message could be creating misalignments in the untransposed message. What about the pivots? What if he put the pivots there first as a clue that it was a transposition cipher because they point horizontally and vertically. And he put two of them in there to make sure they were noticed. And then he inscribed the transposed message around them?
I think that the pivots may be connected to the misalignment and I have some new results that point in this direction. Will try to share soon. I do like your idea of the pivots being a visual clue.