
I am running Jarlve 5/3 shift 15% shift div 2 100 restarts at 10000 iterations, and will look over the output very carefully for evidence of a corrective skip and wildcard orbiting each other. Will let you know.

I am running Jarlve 5/3 shift 15% shift div 2 100 restarts at 10000 iterations, and will look over the output very carefully for evidence of a corrective skip and wildcard orbiting each other. Will let you know.
I understand what you mean now. The hill climber uses simulated annealing so it should not get trapped in such all to often. This means that the hill climbers starts out with making allot of random changes not much favoring one over the other and gradually shifts over into only favoring the better result.
Thanks for answering a lot of my questions.
What is the criteria for creating a new text file? I noticed that sometimes one position changes from one text file to the next, and sometimes two positions change from one text file to the next. Does the program only change one position per iteration, or more, or does it vary?
The output window, text file, shows the best score for the current hill climber restart. It is not a good representation of what it is doing internally. If you like I could build you a version that shows all the ups and downs.
The program changes only one position per iteration since with simulated annealing it is typically best to change as little as possible. Though I am planning to test some kind of depth search.
I am running Jarlve 5/3 shift 15% shift div 2 100 restarts at 10000 iterations, and will look over the output very carefully for evidence of a corrective skip and wildcard orbiting each other. Will let you know.
Yes, I am trying to figure out what is going on internally. A very simple format on one row would be nice. Score:XXXXX Nulls.XXX.XXX.XXX.XXX.XXX. Skips.XXX.XXX.XXX. No message. I could then break it up into three fields and search the fields for ".XXX." ( example ".21." for position 21, or ".217." for position 217 ).A manageable number of rows though, maybe around 5,000 for every 10,000 null skip hillclimber iterations. An option maybe instead of a version.
I got 2,284 output text files, which I combined and extracted the symbol positions from. Before combining, I sorted them by date and time so I could look at changes for each score increase each restart.
Of all, there were 269 with corrective skips and wildcards that were on top of each other ( in the same position ) or orbiting each other by only one position ( next to each other ), and 10 that had two. 269+10/2284=12.2% of the iterations shown in the output text files had this phenomenon happening.
But I also generated random number examples, picking 5 random positions for nulls, and 3 for skips, 2,284 times. I wanted to see how many situations there were where a null and skip were in the same position, or orbiting by one position. And it was almost exactly the same. A typical example was 269 on top of or orbiting by one position, and 12 with two nulls in the same positions as skips, or orbiting by one position.
But then I looked at the information and noticed that with the actual files, there were 159 files with the phenomenon and where the previous file had the same phenomenon and same positions. With the random example, there were only 56, and not with the same positions.
The only way to explain the same percentages but consecutive files with same positions compared to random numbers consecutive rows but not same positions would be that some positions are far more represented in the files as in the random example. And they are. X axis is position, Y axis is how many times the position is counted in the 2,284 files. Top chart is actual files, bottom chart is random numbers.
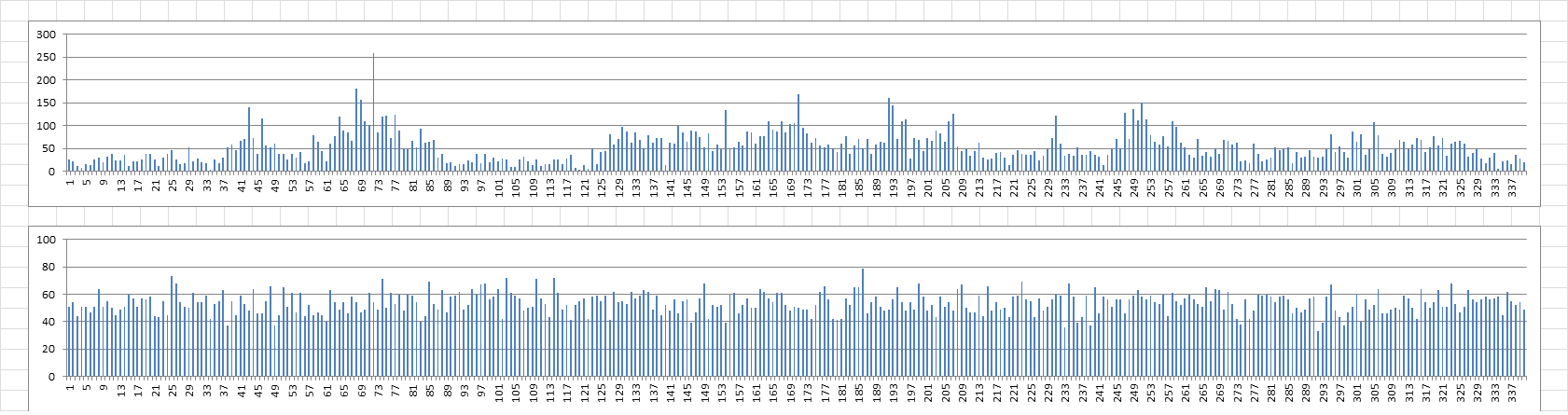
So the orbiting phenomenon, or whatever you want to call it is happening a little bit.
Question: If you get 8 solves with 10,000 iterations and 100 restarts, isn’t that a little better than 15 solves with 20,000 iterations and 100 restarts. 8 solves per million iterations, basically, versus 7.5 solves per million iterations?
EDIT: Thanks a lot for the program.
Okay, try this:
https://drive.google.com/open?id=1Djc5- … fZVyGPyWfz
After the iterations of a restart are done it will create a file in the nulls & skips directory called "hcinfo.txt" with the restart number as suffix. I decided to include all results out of fairness. If you can manage 5000 you should be able to manage 10000. It is not an option, and it will be left on for the development versions.
How it looks:
T: 001 A: 1 Score: 19712 Nulls(0049,0241,0272) Skips(0012,0251) T: 007 A: 1 Score: 20033 Nulls(0241,0272,0308) Skips(0010,0251) T: 008 A: 0 Score: 19771 Nulls(0049,0240,0272) Skips(0010,0251) T: 006 A: 1 Score: 20203 Nulls(0049,0241,0272) Skips(0010,0034) T: 003 A: 0 Score: 19636 Nulls(0049,0241,0272) Skips(0010,0251) T: 004 A: 0 Score: 20121 Nulls(0049,0241,0272) Skips(0010,0224) T: 002 A: 0 Score: 19534 Nulls(0049,0163,0241) Skips(0010,0251) T: 005 A: 1 Score: 20232 Nulls(0116,0241,0272) Skips(0010,0251) T: 001 A: 1 Score: 20397 Nulls(0049,0169,0272) Skips(0012,0251) T: 003 A: 0 Score: 19928 Nulls(0049,0241,0272) Skips(0010,0253) T: 008 A: 0 Score: 20016 Nulls(0088,0241,0308) Skips(0010,0251) T: 007 A: 0 Score: 20348 Nulls(0272,0308,0329) Skips(0010,0251) ...
T: 001 = the thread number
A: 1 = the key is accepted (0 = not accepted)
When a new key is accepted, the threads that are running are not updated with the new key until they report back. That is by design.
Question: If you get 8 solves with 10,000 iterations and 100 restarts, isn’t that a little better than 15 solves with 20,000 iterations and 100 restarts. 8 solves per million iterations, basically, versus 7.5 solves per million iterations?
If these are the true averages then 10,000 * 100 is better.
Thank you very much! And yes, I am sure that I can work 10,000, especially with the formatting. I did Jarlve 5/3 Shift 15% Shift Divisor 2 100 restarts at 10k, 20k, and 30k iterations. I came up with 8, 15, and 12 solves, or 8 solves per million, 7.5 solves per million, and 4 solves per million iterations. It is on the spreadsheet. I am excited about looking into the internals.
I have my first restart on the spreadsheet. So, once a key is accepted, then all threads start making little changes to that key almost simultaneously, and score those keys and report back. Once all of the threads report back, and if one of them has a change that scores higher than the key ( or the highest if more than one ), then the new key is accepted and the threads all start working on making little changes to that new key. That is what you mean by simulated annealing? With my first restart, 354 new keys were accepted.
I sent you a text file of my 1st restart, Jarlve 5/3 Shift 15% Shift Div 2. There is some orbiting see iterations 1304 to 1591 and 6884 to 7453. The criteria was null was in exact same position as skip, or -1 or +1 position. But the program was able to break out of the orbiting though. Maybe make it so a key cannot be accepted if a null and skip are in the exact same position, since that is impossible. Maybe this will result in a small improvement. Your judgment but if I can find this on my first restart, then probably others as well. I think that is part of the problem with smokie 5/5, the more nulls and skips, and the more equal divisions, the more orbiting. A message with all nulls or all skips should have higher solve rates. If you are interested, I could make three messages, one with all nulls, one with half and half, and one with all skips. Not too many though because I wouldn’t want to take a week to find out. Same exact plaintext, same homophones, and same exact positions for each, but the half and half with alternating positions. Evenly spread about. Let me know or if you have any suggestions.
So, once a key is accepted, then all threads start making little changes to that key almost simultaneously, and score those keys and report back. Once all of the threads report back, and if one of them has a change that scores higher than the key ( or the highest if more than one ), then the new key is accepted and the threads all start working on making little changes to that new key. That is what you mean by simulated annealing? With my first restart, 354 new keys were accepted.
Once a key is accepted it becomes the new base key for all threads that start from then on. But the program does not wait for all threads to report back, that would slow it down allot. A key is accepted based on what is called the simulated annealing acceptance function that works with the temperature. If the temperature is high then it will be more likely to accept keys that are worse, resulting in more of a random walk in the search space. The temperature starts high and then declines with more iterations.
I sent you a text file of my 1st restart, Jarlve 5/3 Shift 15% Shift Div 2. There is some orbiting see iterations 1304 to 1591 and 6884 to 7453. The criteria was null was in exact same position as skip, or -1 or +1 position. But the program was able to break out of the orbiting though. Maybe make it so a key cannot be accepted if a null and skip are in the exact same position, since that is impossible. Maybe this will result in a small improvement. Your judgment but if I can find this on my first restart, then probably others as well. I think that is part of the problem with smokie 5/5, the more nulls and skips, and the more equal divisions, the more orbiting. A message with all nulls or all skips should have higher solve rates.
It should indeed not have a null and skip occupy the same position. I will test your proposed change.
If you are interested, I could make three messages, one with all nulls, one with half and half, and one with all skips. Not too many though because I wouldn’t want to take a week to find out. Same exact plaintext, same homophones, and same exact positions for each, but the half and half with alternating positions. Evenly spread about. Let me know or if you have any suggestions.
Good idea but I want to figure out a few other things first and it will take time. Will let you know.
O.k., that sounds fantastic. I am having a lot of fun by the way.
So, once a key is accepted, then all threads start making little changes to that key almost simultaneously, and score those keys and report back. Once all of the threads report back, and if one of them has a change that scores higher than the key ( or the highest if more than one ), then the new key is accepted and the threads all start working on making little changes to that new key. That is what you mean by simulated annealing? With my first restart, 354 new keys were accepted.
Once a key is accepted it becomes the new base key for all threads that start from then on. But the program does not wait for all threads to report back, that would slow it down allot. A key is accepted based on what is called the simulated annealing acceptance function that works with the temperature. If the temperature is high then it will be more likely to accept keys that are worse, resulting in more of a random walk in the search space. The temperature starts high and then declines with more iterations.
The program allows for some new iterations that score lower to be accepted, because if only higher scoring keys are accepted, the program will find more keys that are neither a solution nor which can be improved upon. So it is better to control the pace of hill climbing and try a lot of different variations of keys that gradually get closer and closer to a solution.
I am happy you are having fun. You should consider picking up a decent programming language again. You have good ideas to work with.
See this:
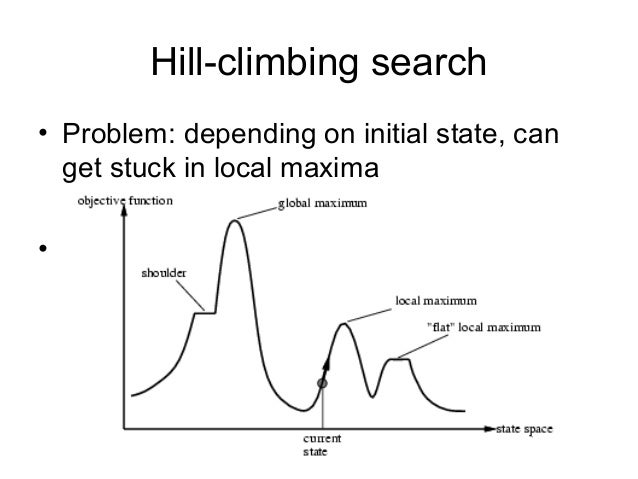
With simple hill climbing, it can, and most likely will get stuck in these local maxima, which can be numerous. But simulated annealing essentially allows the search to backtrack and get out of these. The global maximum is the correct solution to the problem.
