

onewhoknows, Subject: Ancient Alphabets Sat Dec 22, 2012 3:04 pm
I noticed similarities in ancient alphabets to alot of the symbols the Zodiac used.
Given his interest in Egyptian ancient history, I wonder if any of the cypher experts
ever explored the meaning of these ancient symbols he mixes in with modern letters?

patinky, Subject: Re: Ancient Alphabets Sat Dec 22, 2012 4:28 pm
I noticed similarities in ancient alphabets to alot of the symbols the Zodiac used.
Given his interest in Egyptian ancient history, I wonder if any of the cypher experts
ever explored the meaning of these ancient symbols he mixes in with modern letters?
I guess I missed the boat on this one. I’ve not seen anything that indicates Zodiac was interested in ancient Egyptian history. Could you give me a reference please. TIA

Quicktrader, Subject: Re: Ancient Alphabets Sat Dec 22, 2012 6:39 pm
I noticed similarities in ancient alphabets to alot of the symbols the Zodiac used.
Given his interest in Egyptian ancient history, I wonder if any of the cypher experts
ever explored the meaning of these ancient symbols he mixes in with modern letters?I guess I missed the boat on this one. I’ve not seen anything that indicates Zodiac was interested in ancient Egyptian history. Could you give me a reference please. TIA
It all looks quite Egyptian as soon as you try to solve it ![]()
Currently I figured out that a homophonic cipher substitution, Z used such for the 408, may lead to the assumption that if e.g. the letter ‘E’ is present 13% in the plaintext, an overall of 13 different symbols represent the letter ‘E’. In fact, Z had used ‘only’ 7 different symbols for the letter ‘E’.
What sounds and is sort of a general theory for homophonic ciphers, gets interesting with the 340-cipher: The symbol ‘+’ shows up about 7% in the cipher. Just because of the frequency of this particular symbol it therefore might be assumed that there are up to 3-4 other symbols representing the same letter behind the symbol ‘+’. This together with a look on statistics shows that the letter ‘E’ is the only letter that usually makes it above 10% in the plain text.
Let me give an example:
If the letter ‘D’ is present approx. 4% in the plaintext, the symbol ‘+’ presumably does not represent the letter ‘D’. It also would not represent the – rather frequent (7%) – letter ‘N’ as there would be, according to N’s frequency, some additional 3-4 symbols representing ‘N’ (which would not match the usual ‘N’ frequency as these homophones altogether would lead to a an estimated 10-11% frequency of the letter ‘N’ in the plaintext, rather unusual).
Now ‘N’ is not the rarest, but one of the most frequent letters in the English alphabet. So if we are looking in the plaintext for a letter with an overall frequency of approx. +10%, there actually remains only the letter ‘E’ (eventually ‘T’, ‘O’ or ‘A’ get close to it). This means that ‘+’ would for >98% somehow represent the letter ‘E’.
Therefore on position 289 (in the plaintext) words like ‘street’, ‘fleefrom’ etc. would match somehow better than e.g. ‘little’ or ‘riddle’ etc..
Nevertheless, for ‘+’ representing the letter ‘N’ I have found some approach. With ‘lips near the inner part’ it is possible to figure out a match of 11 (!) letters with the text ‘anxious on and I better’ which shows up somewhere else in the cipher.

‘N’ is quite sure the wrong approach…such an example with ‘E’ for the ‘+’ symbol would be much better..
In the 408-cipher, Z had used homophones mainly for letters and that occur more frequent than others:
ETAOINSR (also DFH, however only with two symbols)
However he was not consistent in doing that, e.g. for the letter ‘M’ he had only used one symbol – although it occurrs 17 times in the cipher – while using two symbols for the letter ‘H’, which only occurs 16 times. This shows that Z presumably had chosen the letters of which he wanted to use homophones for (therefore more than one symbol) rather according to his own impression than actually counting each of them (the cipher therefore is not an ‘optimum’ as this would require a number of homophones according to the statistical distribution of the letters present in the plaintext – as a professional cryptograph, Z actually would’ve been a looser).
http://www.zodiologists.com/z408_cipher_key.html
(homophonic structure of the cipher key)
In the 408 Z had indeed used various homophones (symbols) for the letter ‘E’ in a sequential order (‘homophonic sequence’). At least in the beginning of the cipher, he did not simply ‘shuffle’ the symbols each time to replace the letter ‘E’ with any symbol representing ‘E’, he rather had chosen the homophones wisely – one after another – in the following sequence (each number represents one of the seven symbols he had used for the letter ‘E’ – and this is NEW information:
0123456, 0123456, 6, 0123456, 0123456, 5, 0123456, 01233206, 4 03246246
(‘homophonic sequence substition’, scientifically described here:
http://www.isiweb.ee.ethz.ch/papers/arc … 1990-1.pdf
http://www2.ee.ufpe.br/codec/Homophonic_sequence.PDF )
Z consequently had used the homophones in this sequential order replacing the letter ‘E’ – until the word ‘slavE’ – he then changed the sequence of homophones, accidentially or not. However he still continued to count down the single ‘interruption’ homophones from 6 to 4…
If you calculate down the size of the two ciphers (340 is 83% of the 408) and follow the idea that Z had used homophones mainly for the most frequent letters only, the number of homophones in the 340 should approximately be:
E=6 (instead of 7 in the 408 cipher)
T=3 (instead of 4 in the 408 cipher)
A=3 (etc.)
O=3 (…)
I=3
N=3
S=3
R=2
while all other letters probably would be substituted by one symbol only. But: A sequence as in the 408-cipher is not easy to be found with the ‘+’ symbol, as between start of the cipher and the first ‘+’ AND the first ‘+’ and the second ‘+’ there is NO symbol represented twice. Therefore the boundaries of the sequence must lay somewhere else.
Overall, in the first lines of the cipher there is no ‘E’ with a 5 or 6 symbol long homophone sequence recognizable at all. Why? Because it would require much more homophones repeating between e.g. the first and the second ‘+’ symbol. With another symbol representing ‘E’, such sequence might eventually still be found (currently looking for it).
So what is the conclusion of this pseudostatistic analysis? Yes, ‘+’ is definitely a member of the ETAOINSHR ‘family’ (frequency>7%). And no, ‘+’ is not a member of the INSHR group either (frequency ~7% BUT still to be considered that 2-3 other homophones additionally represent the letter, which would unexpectingly increase the frequency to at least 8% – which is not to be assumed acc. to statistical data http://scottbryce.com/cryptograms/stats.htm ).
The only possibility representing a minimum of 7% of the cipher, not being the letter ‘E’ (due to lack of symbol sequence), is to have one or two additional homophones (symbols) leading to a total letter frequency of minimum 8-9%. This is possible only for three letters: ‘T’, ‘A’ and ‘O’.
So if someone wants to follow this approach, you may want to set ‘+’ to either ‘T’, ‘A’ or ‘O’ as all other letters seem to occur either more (‘E’, no sequence) or less (‘Z’ to ‘I’) frequent. And there is another point: More than half of the words end with ‘E’, ‘T’, ‘D’ or ‘S’, it might therefore be assumed that the ‘+’ symbol (as the last letter of the cipher) might represent the letter ‘T’. This is also supported by the idea that the overall frequency is at least 8-9%, which would eliminate ‘D’ and ‘S’ as being the final letter with at least 50% odds, too.
QT
patinky, Subject: Re: Ancient Alphabets Sat Dec 22, 2012 7:08 pm
QT, I thought it was Greek not Egyptian so that’s my problem. :lol!:
Seriously, I do not have the skill set or mind set to work with cryptography. I’m not even good at American math. ![]()
What you have deciphered looks promising though, especially the "anxious on and i better" sequence. I enjoy reading everyone’s work on the codes but I must remain a Lurker when it comes to helping with them. I can compile and analyze statistics but the numbers stop there!
glurk, Subject: Re: Ancient Alphabets Sun Dec 23, 2012 3:53 am
Some random comments…
Given his interest in Egyptian ancient history
Where is this from? I’ve never read anything anywhere that said Z had an interest in ancient Egyptian history. And as far as the symbols in the ciphers, I personally think he just made them up!
Quicktrader-
Your analysis is interesting, but flawed, I think. Firstly, the consensus (my consensus, anyway) is that the 340 is not just a homophonic cipher like the 408. If it were, I believe it would have been solved by now.
But even if it were, saying that the "+" symbol MUST equal certain letters is an opinion I cannot agree with. When looking at the frequency of letters in English, well, those frequencies have been taken from LARGE
selections of English text. That doesn’t mean they apply to everything ever written. Consider if the "+" represented the letter "Z"
Example: "Whilst everyone is abuzz about my dazzling puzzle, I shall just razz them and go get a pizza"
I’m not saying that phrase appears in the 340 (it does not) but since we DON’T KNOW what it says, I believe it a mistake to rule out letters based on normal frequencies. They don’t really apply to short messages.
The "+" symbol could also be a ‘wildcard’ which can represent ANY letter, or the 340 could even be a lipogrammatic message. Look at "Gadsby" – a ~50000 word novel written without ever using the letter "E"
http://en.wikipedia.org/wiki/Gadsby_%28novel%29
Here is the first part:
If youth, throughout all history, had had a champion to stand up for it; to show a doubting world that a child can think; and, possibly, do it practically; you wouldn’t constantly run across folks today who claim that “a child don’t know anything.”A child’s brain starts functioning at birth; and has, amongst its many infant convolutions, thousands of dormant atoms, into which God has put a mystic possibility for noticing an adult’s act, and figuring out its purport.
Up to about its primary school days a child thinks, naturally, only of play. But many a form of play contains disciplinary factors. “You can’t do this,” or “that puts you out,” shows a child that it must think, practically or fail. Now, if, throughout childhood, a brain has no opposition, it is plain that it will attain a position of “status quo,” as with our ordinary animals. Man knows not why a cow, dog or lion was not born with a brain on a par with ours; why such animals cannot add, subtract, or obtain from books and schooling, that paramount position which Man holds today.
I don’t really think the 340 is a lipogrammatic message, but it COULD BE. But I keep my mind open to such ideas, nonetheless. We just don’t know!
-glurk
Quicktrader, Subject: Re: Ancient Alphabets Sun Dec 23, 2012 5:36 am
Some random comments…
Given his interest in Egyptian ancient history
Where is this from? I’ve never read anything anywhere that said Z had an interest in ancient Egyptian history. And as far as the symbols in the ciphers, I personally think he just made them up!
Quicktrader-
Your analysis is interesting, but flawed, I think. Firstly, the consensus (my consensus, anyway) is that the 340 is not just a homophonic cipher like the 408. If it were, I believe it would have been solved by now.
But even if it were, saying that the "+" symbol MUST equal certain letters is an opinion I cannot agree with. When looking at the frequency of letters in English, well, those frequencies have been taken from LARGE
selections of English text. That doesn’t mean they apply to everything ever written. Consider if the "+" represented the letter "Z"Example: "Whilst everyone is abuzz about my dazzling puzzle, I shall just razz them and go get a pizza"
I’m not saying that phrase appears in the 340 (it does not) but since we DON’T KNOW what it says, I believe it a mistake to rule out letters based on normal frequencies. They don’t really apply to short messages.
The "+" symbol could also be a ‘wildcard’ which can represent ANY letter, or the 340 could even be a lipogrammatic message. Look at "Gadsby" – a ~50000 word novel written without ever using the letter "E"http://en.wikipedia.org/wiki/Gadsby_%28novel%29
Here is the first part:
If youth, throughout all history, had had a champion to stand up for it; to show a doubting world that a child can think; and, possibly, do it practically; you wouldn’t constantly run across folks today who claim that “a child don’t know anything.”A child’s brain starts functioning at birth; and has, amongst its many infant convolutions, thousands of dormant atoms, into which God has put a mystic possibility for noticing an adult’s act, and figuring out its purport.
Up to about its primary school days a child thinks, naturally, only of play. But many a form of play contains disciplinary factors. “You can’t do this,” or “that puts you out,” shows a child that it must think, practically or fail. Now, if, throughout childhood, a brain has no opposition, it is plain that it will attain a position of “status quo,” as with our ordinary animals. Man knows not why a cow, dog or lion was not born with a brain on a par with ours; why such animals cannot add, subtract, or obtain from books and schooling, that paramount position which Man holds today.
I don’t really think the 340 is a lipogrammatic message, but it COULD BE. But I keep my mind open to such ideas, nonetheless. We just don’t know!
-glurk
True what you say, the letter frequencies should become better and better with the length of the cipher. In your ‘pizza’ text, the letter ‘Z’ is represented approximately 13%. Seen in a complete 340 cipher text, such a text would increase the frequency of ‘Z’ from about 0.09% to ~3.00%, quite an extreme example (outlier).
What is essential is that the described is not necessarily influenced by such a single shift of frequency! This would only be the case if the symbol ‘+’ would represent exactly this letter ‘Z’.
If ‘+’ represents e.g. the letter ‘E’ instead, the above-average frequent letter ‘Z’ wouldn’t influence the frequency of the letter ‘E’ that much…only as it ‘occupies’ more letter of the cipher than ‘Z’ usually would occupy..therefore e.g. -10% of ‘E’s possible in the cipher (overall 12% instead of 13%, therefore still identifiable as the letter ‘E’).
In your example is the frequency of the letter ‘E’ indeed less than 13%, in fact only 8%. BUT: Assuming an overall text length of 340 (instead of 74) leads us to
74 x 8% + 266 x 13% = 40.5 ‘E’ letters in the overall cipher, which equals – although the ‘pizza’ phrase might be a part of the cipher – still approximately 12%! Identification of this letter therefore still being possible.
Overall it might be agreed that a sample of 340 letters leads to sort of a viable frequency distribution, at least it is much better than 10-50 (scientists usually start with 3,000 to get solid-rock data).
The homophonic sequence actually interests me most: Such structure certainly appeared in the 408, also had led to 80-90% of the errors in the 408 cipher (precisely: the filled-out triangle symbol).
If we could find such a structure for the letter ‘E’ in the 340, we could even try to replace the ‘+’ with any other letter to receive approximately 20% of the cipher (trial and error with 26 letters for ‘+’ is possible, crucial is the sequence of ‘E’s).
And not to forget about the triple dump-n-grams which could represent phrases like ‘the’ or ‘ing’ (as it was in the 408 the case). With ‘+’ = ‘T’ and ‘FBc’ = ‘ING’ (plaintext) someone might ‘easy’ figure out that only few words may match certain positions of the cipher, such as the word ‘stuttering’ beginning from position 138 ..well, I’ll try on.
QT

traveller1st, Subject: Re: Ancient Alphabets Sun Dec 23, 2012 8:36 am
Given his interest in Egyptian ancient history
I think OWK means because of Z’s whole afterlife/slaves deal which has an ancient Egyptian practices and beliefs ring to it.
Quicktrader, Subject: Homophonic sequences Sun Dec 23, 2012 12:51 pm
Wow, just figured out that there somehow are homophone sequences in the 340-cipher…great work, Doranchak:
https://www.evernote.com/shard/s1/sh/7b … 891c30f43e
However I am still looking for a sequence of at least 5, if not 6 letters (repeating at least twice) could representing the letter ‘E’..overall there is not yet such a clear homophone sequence structure found like in the 408..
QT
doranchak, Subject: Re: Ancient Alphabets Sun Dec 23, 2012 3:16 pm
All candidate homophone sequences are listed out here:
http://zodiackillerciphers.com/wiki/index.php?title=Brute_force_search_for_homophone_sequences
You are right — the sequences detected in the 340 are definitely weaker than those in the 408. He either abandoned the cycling strategy he used to assign symbols, or the cycling was performed in an unexpected direction or as part of some additional transformation of the cipher text.
Also, I think I only tested for the traditional cycle pattern: ABC ABC ABC etc. But other patterns exist, such as ABCBABCBABCBA, ABC BCD CDE ABC BCD CDE, etc. I don’t know if anyone has tested for those possibilities yet.
By the way, there are a few 5-symbol sequences that repeat at least twice. But they are a little bit "sloppy". Examples:
[P|YMZ] M| [P|YMZ] |YM|M|Z|M| [P|YMZ] |
>ppOpppO [/pOC>] OOp [/pOC>] OpCCO [/pOC>] pO
GD [G7tD;] G [G7tD;] Gt [G7tD;]
LD [L7tD;] L [L7tD;] tL [L7tD;]
D [f7tD;] [f7tD;] ft [f7tD;]

AK Wilks, Subject: Re: Ancient Alphabets Mon Dec 24, 2012 12:52 pm
I noticed similarities in ancient alphabets to alot of the symbols the Zodiac used.
Given his interest in Egyptian ancient history, I wonder if any of the cypher experts
ever explored the meaning of these ancient symbols he mixes in with modern letters?
ThebigZ pointed out that in Meroitic Script, used in the Ancient Egyptian times, the symbol for "K" looks very much like the signature symbol on the bottom of the Bates letters.
Very interesting!

Bates signature vs. Meroitic K.


There have been a hundred different theories on what the Bates signature is – 2, 3, Z, etc. – but this makes as much sense as any of them. And is the best match I have seen. So was Zodiac and/or the Bates killer, giving us a clue of "K" ?
ALSO – in the 340 I think the + is L. Consider the number of words Zodiac used with two "L" ‘s. Such as KILL, KILLING, THRILL, THRILLING, SHALL and others. Also, when you translate the + as L, it starts to create word formations like THOSE FOOLS SHALL SEE and several others. So far I have failed to convince most of the code world of this theory however!
Quicktrader, Subject: Re: Ancient Alphabets Tue Dec 25, 2012 11:03 am
All candidate homophone sequences are listed out here:
http://zodiackillerciphers.com/wiki/index.php?title=Brute_force_search_for_homophone_sequences
You are right — the sequences detected in the 340 are definitely weaker than those in the 408. He either abandoned the cycling strategy he used to assign symbols, or the cycling was performed in an unexpected direction or as part of some additional transformation of the cipher text.
Also, I think I only tested for the traditional cycle pattern: ABC ABC ABC etc. But other patterns exist, such as ABCBABCBABCBA, ABC BCD CDE ABC BCD CDE, etc. I don’t know if anyone has tested for those possibilities yet.
By the way, there are a few 5-symbol sequences that repeat at least twice. But they are a little bit "sloppy". Examples:
[P|YMZ] M| [P|YMZ] |YM|M|Z|M| [P|YMZ] |
>ppOpppO [/pOC>] OOp [/pOC>] OpCCO [/pOC>] pO
GD [G7tD;] G [G7tD;] Gt [G7tD;]
LD [L7tD;] L [L7tD;] tL [L7tD;]
D [f7tD;] [f7tD;] ft [f7tD;]
Interesting..especially if someone wants to focus on sequences that do start at the beginning, as it might be assumed that Z wouldn’t start in the middle of the sequence (no need for it, as it doesn’t make any difference if he starts with homophone1 or homophone3 to replace e.g. the letter ‘E’…like in the 408, the sequence therefore would start with setting up the cipher step by step.
Therefore the ‘matches’ (see site for details) should be preferred when starting with a secquence….this is symbolized with ‘[‘ and ‘]’). Those which repeat similar to the 408 like
‘sequence’ ‘sequence’ ‘no.’ ‘sequence’ ‘sequence’ ‘no.’ etc.
might be of hightest interest for the letter ‘E’, especially if the frequency (%) is +/- 12-13%….
Some of the sequences had caught my eye:
Length=5
[RDYR4] [RDYR4] [RDYR4] R444RYD – 6.47%
[RDY<R] [RDY<R] < [RDY<R] RR<<YD – 6.47%
[RD<R4] [RD<R4] < [RD<R4] R444R<<D – 7.06%
[RY<R4] [RY<R4] < [RY<R4] R444R<<Y – 7.06%
which could represent e.g. an TAOINSHR letter…rather nothing else, at least not without adding another symbol to the sequence (as ‘E’ is probaby > 12% and other letters might have a lower frequency).
The bold ones, btw, have an identical homophone sequence structure as it was used in the 408 (!). This could be a strong indicator of being a valid group of homophones.
One or two ‘errors’ (symbol not representing the target letter) might be present in a sequence. Or the previously mentioned sequences simply are ‘not long enough’ for the true length of the sequence, which is why ~4 variations do occur…so seen at the 408 (multiple variations at L=4, finally a solid ZpW+6NE sequence L=7).
Therefore we may want to look at
Length=6
[RDY<R4] [RDY<R4] < [RDY<R4] R444R<<YD – 8.24%
and here we go, getting a hot candidate for a letter of the ETAOIN group…(figuring out all groups would equal 6!=720 trial & error runs to solve the cipher)…rather nothing else as OIN already have a frequency of less than 8.0%..the letter ‘S’ e.g. with a frequency of 6.5% would be quite far away from being represented by such a 8.24%-sequence..).
And we find another group of sequence variations, indicating that there might be even a L=7 sequence:
[Pd%cJj] d [Pd%cJj] dcJcJcccccPdc – 7.65%
[P%cJ_9] [P%cJ_9] cJcJ9cc9cccP_c – 7.65%
[Pd%cjd] [Pd%cjd] cccccccPdc – 6.47%
[>%cJ_9] [>%cJ_9] cJcJ9cc9>ccc_c> – 7.94%
Someone might want to search the ‘full raw data’ section for the value ‘] [‘ to figure out at least two sequences in a row, implicating some sort of sequential structure of homophones.
Then the work starts: If there is another sequence recognizable, e.g. following these two sequences (even if sort of ‘interrupted’ by one single symbol), this would be hothothot..especially if it had a 12-13% overall frequency (the letter ‘E’ is not such a bad start to solve the cipher..).
One more thing:
In some cases it is difficult to transfer the ASCII symbols (e.g. the figure ‘4’) that have been used in this analysis to the real cipher symbols – is there sort of an ascii text that had been used as a basis for the analysis? Where somone might be able to look up which symbol e.g. ‘5’ is representing?
Hard enough to figure out that the ‘4’ is acutally representing the half-filled (left) circle..
Anybody able to look up the ‘E’ sequence? Be brave.. :tongue:
QT
doranchak, Subject: Re: Ancient Alphabets Wed Dec 26, 2012 2:07 pm
The bold ones, btw, have an identical homophone sequence structure as it was used in the 408 (!). This could be a strong indicator of being a valid group of homophones.
I’m not seeing how your example matches to the 408. Can you show me?
Also, here is a general comment about these sequences: We have to be careful about making conclusions from the appearance of patterns in the cycle candidates. For example, [RDY<R4] [RDY<R4] < [RDY<R4] R444R<<YD looks strong, but if you look at L=6 for the 408, you’ll see false positives such as: [OHKI5(] [OHKI5(] I [OHKI5(] HOI5HI5KHI5(OIO5KH5OIIHI. OHKI5 decodes to NTSTTN, instead of a single letter.
The big problem I had with the search for cycles was figuring out how to separate true positives from false positives. The only way I could think of was to try to estimate the odds of the sequences occurring, then arranging the sequences from "hardest to generate randomly" to "easiest to generate randomly." There’s no clear line, however, between the true positives and false positives.
The math behind the odds computation is here: http://www.zodiackillerfacts.com/forum/viewtopic.php?f=50&t=1329&p=22906#p22906. Warning: it is likely to put you to sleep. ![]() But the basic idea is to count how often the "interesting-looking" strings appear among every possible string that can be made. This gives you an relative estimate of how hard it is for the interesting strings to occur by chance alone.
But the basic idea is to count how often the "interesting-looking" strings appear among every possible string that can be made. This gives you an relative estimate of how hard it is for the interesting strings to occur by chance alone.
I do think it’s interesting that patterns seem to form at the beginning of the cipher, and fall apart later on. Even if the patterns are false positive, they seem to be pretty good signs that some kind of (possibly bastardized) homophonic substitution is going on.
One more thing:
In some cases it is difficult to transfer the ASCII symbols (e.g. the figure ‘4’) that have been used in this analysis to the real cipher symbols – is there sort of an ascii text that had been used as a basis for the analysis? Where somone might be able to look up which symbol e.g. ‘5’ is representing?Hard enough to figure out that the ‘4’ is acutally representing the half-filled (left) circle..
Yes; use the Zodiac Typewriter.
http://zodiackillerciphers.com/typewriter
Simply paste your ASCII in the box. You can then click "show bbcode" to generate the stuff you can paste in the forum to make the symbols appear.
Pd%cJj d Pd%cJj dcJcJcccccPdc
becomes
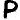
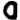

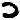
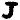
![]()
![]()
![]()
Quicktrader, Subject: Re: Ancient Alphabets Wed Dec 26, 2012 7:41 pm
Thanks for your comments,
Z had used this sequence of homophones for the letter ‘E’ in the 408 cipher:
0123456………..0123456……..6….0123456………..0123456………5….0123456………..01233206………4….03246246

Z had used seven different symbols for the letter ‘E’, starting with the first symbol (Z) and ending with the last one (E). While setting up the cipher, he first had repeated this (sequence) twice, then entered sort of an interruptor by using the last symbol twice. Then again two sequences, another interruption by using the last but one symbol of the sequence again. Then another sequence..then chaos, however still continuing to count down with the interruptor to symbol no. 4..
It should be mentioned that Z’s symbol cipher could also be a cipher of numbers by replacing each symbol with a number. It somehow reminds me the vigenere structure of the CIA krypto cipher and have I read somewhere about such (asymmetric?) ciphers that use such a sequence structure, however this structure gets more and more diluted the longer the cipher is.
No question, Z had used the letter ‘E’ homophones in a sequence.
BTW, Z had used even more symbols in the 340 than in the 408. In the 408 he had used 54 different homophones for an alphabet with 26 letters (ratio 2.08), while in the 340 he had used 63 different homophones (ratio 2.625). With the 340 being shorter than the 408, this makes solving even more difficult (might be the reason why it didn’t work with the excellent tool yet). This may also lead to the conclusion that in the 340 at least the same number of homophones exist for e.g. the ETAION letters as there had been in the 408.
Originally I had thought that the 340 might have less homophones than the 408…the opposite is true! And the raw data of Doranchak shows (if sthg) that there might exist at least one single group of 7 homophones (Pd%cJj..), one of 6 homophones (RDY<R4) and quite a number of 5, 4, 3 homophones, however more of those in the 340 than in the 408.
QT
onewhoknows, Subject: Re: Ancient Alphabets Wed Dec 26, 2012 11:32 pm
I see similar symbols in the Phoenician Alphabet including the Zodiac Symbol and the weird symbol
Zodiac used as his return address see below letters Y and T





Ok, some sort of new information with regard to the 340 cipher. All who have followed my weird description above should be 100% convinced ![]() that
that
the 340-cipher
– is a homophone substitution cipher
(homophones represent one letter of cleartext, e.g. two or more different symbols representing the letter ‘E’)
– is basically structured in sequences of various homophones
(like in the 340 the letter ‘E’ was represented by Zp+WOE… repeating again and again…see above )
– is of higher complexity than the 408
(as there are more symbols/homophones for a shorter text)
– has shorter sequences as there is no obvious longer sequence repitition
Now…this leads us to select all sequences of homophones we can find (thx Doranchak).
Of course we start with the longest available, L=7, therefore seven homophones for one cleartext letter. And there we go – about 2.150 different sequences of homophones which start to repeat again from the beginning, all length seven, such as:
[R>.fZR4] [R>,fZR4] RR4,Rf4,44>Z,,fR>Z
Actually there exist even more, but as I had mentioned above there is no need to start a sequence of homophones ‘in the middle’. This might happen but should be rather unusual as – during encryption process – it doesn’t matter if you chose Z or + or W or whatever symbol for the letter ‘E’…you simply start taking one and, after having used e.g. seven different symbols, might continue by repeating the sequence again.
Not to forget, Zodiac had broken such homophone sequence structures..each letter had sort of a different sequence structure and the longer the text, the less was this sequence structure valid – to make it even harder.
Buuuut…we do have those sequences again in the 340. From the 408 we have learned that if you have two slightly different, similar sequences e.g. of length 4, those could show up in the analys of length 5 as one solid sequence.
What we do have is ~2,150 sequences of seven homophones – starting from the beginning – which do repeat at least twice:
[OzJO_z4] [OzJO_z4] zJOOJ4z444zOzO_OzO
[PO%cJO_] [PO%cJO_] cJOOcJcccOccPO_OcO
[PO%cO_9] [PO%cO_9] cOOc9cc9cOccPO_OcO
[PO,zJOz] [PO,zJOz] zJOOJ,z,,zO,zPOOzO
[POD,zOz] [POD,zOz] zODO,z,,zO,zPOODzO
[R%,<ZR4] [R%,<ZR4] <R<R4,R4,44Z,,R<<Z
….
We do see that in Length=7 there is NO sequence repeating three times or more. So let’s calculate:
340 letters x approximately 12.5% the letter ‘E’ is about 42.5 times the letter ‘E’ should show up in the 340-cipher. 42 times is a lot…now we put two thoughts together:
42 letters and the sequence repeating no more often than twice (at least with L=7) – tadaaa:
It is possible, that the letter ‘E’ is represented by a sequence of up to 21 homophones, e.g. repeating twice!
It is simple:
If you look at the 408, L=4 or L=5 you see many sequences and won’t get a clear picture. If you look at L=7 however, you get some sequences such as the Zp+WOE…
What I do believe is that the sequences in the 340 cipher are shorter but – in average – the number of homophones representing one letter must be higher! You want the proof? It’s easy…the alphabet has 26 letters. In the 408 those were represented by 54 homophones ‘only’.
In the 340 those 26 letters are represented by 63 homophones!
Doranchak, we need an extension of your excellent analysis. This should contain also Length=8, Length=9, Length=10 etc. To see, if there is any homophone sequence of higher grade, still reapeating twice..an example:
[PO%cJO_] [PO%cJO_] cJOOcJcccOccPO_OcO (9.41%)
[PO%cO_9] [PO%cO_9] cOOc9cc9cOccPO_OcO (9.41%)
is an example of L=7 repeating twice. However, the symbol ‘9’ follows striclty the symbol ‘_’, it therefore is also a sequence of Length=8:
[PO%cJO_9] [PO%cJO_9] …
We do know that this seqence of lengh = 8 does exist, but we don’t know the % it represents in the overall cipher. It could be the letter ‘E’, the letter ‘T’ but rather not the letter ‘Q’. An analysis of higher grade sequences (L=8+) would therefore help to
a. ) reduce the number of twice-repeating sequences of homophones
b.) show the % of those sequences
If we are lucky, we might get only one twice-repeating sequence of homophones with length e.g. L=9 and a frequency of approx. 13%. The 340 has only about 3,300 L=7 sequences, 408 had over 10,000…so it might be a way to at least select a group of potential ‘E’ homophones..still tough.
UPDATE:
Let us think about how Z has made his cipher:
1.) write 64 symbols on a piece of paper (cipher sheet, cipher alphabet)
2.) write an alphabet ABCDEFGHIJKLMNOPQRSTUVWXYZ
3.) accidentially choose one symbol, cross this symbol out of the cipher sheet and write it under one of the letters of the alphabet
4.) continue as you like, sometimes repeating symbols sequences in an order you prefer (e.g. sequence of seven symbols under the letter ‘E’)
5.) usually using as many symbols as the letter frequency tells you to do (not so hard as it would become sort of unsolvable, so e.g. 10 symbols for the letter ‘E’)
That means that Z did not use any symbol twice in a partial sequence (e.g. ‘Zp+WOE’). Like in the 408, there wouldn’t be – basically – any symbol twice in the ‘Zp+WOE’ section. No Z twice, no W twice etc…because it is already crossed out on the cipher sheet. Z HAD to cross it out, because otherwise it could have been chosen again for another letter, e.g. the ‘T’ (which would make the cipher finally unsolvable).
So there should be no longer partial sequence with any repeating symbol. It is rather presumable that some symbols occur twice if they belong to another sequence, which is shorter than the ones analyzed. Therefore, the ~2,150 sequences of L=7 (which actually start with a sequence and not with a single letter or part of the sequence) may be reduced to those having only different homophones inside.
Done so, I end up with 92 different sequences instead of ~2,150. Those sequences actually are ‘groups of symbols’ or ‘groups of homophones’, representing each one alphabetical letter. However, some of those groups still have to be reduced by analysing if they belong together: Three similar groups of homophones actually may represent one sequence of L=9 instead of three sequences of L=7:
All different L=7 sequences…eventually belonging to one L=9 or even L=10 sequence?
[%.f_94/] [%.f_94/]
[%.f_94-] [%.f_94-]
[%.J_94-] [%.J_94-]
[%UJ_94-] [%UJ_94-]
…
All those 92 sequences start with only 5 different homophones (%, >, D, H, P). So when Z had started setting up one of his (longer) sequences, first he did was to choose one of those five symbols. If one of the ETAOIN or rather ETA letters is represented by a L=7 (or higher) sequence, one of those five homophones must represent it.
UPDATE 2:
Now I have selected the possibilities of a partial sequence being longer than L=7 and actually found only 8 of such partial sequences:
>%.f_94/ 9.41%
>%.f_94- 10.00%
>D.f_94- 10.59%
>D.f_94/ 10.00%
>%UJ_94/ 9.12%
>%UJ_94- 9.71%
>DUJ_94- 10.29%
>DUJ_94/ 9.71%
In my opinion there is no partial sequence with L=9 or higher, repeating twice without other interruptions etc. Therefore it might be assumed that one of those sequences above is a correct group of homophones representing a letter with the frequency of 9.12% to 10.59%. Luckily they are all about at the same frequency level.
10.0% is about the frequency of the letter ‘T’, which is why I think that one of the following L=8 sequences does represent the letter ‘T’
[>%.f_94/] [>%.f_94/] 9.41%
[>%.f_94-] [>%.f_94-] 10.00%
[>D.f_94-] [>D.f_94-] 10.59%
[>D.f_94/] [>D.f_94/] 10.00%
[>%UJ_94/] [>%UJ_94/] 9.12%
[>%UJ_94-] [>%UJ_94-] 9.71%
[>DUJ_94-] [>DUJ_94-] 10.29%
[>DUJ_94/] [>DUJ_94/] 9.71%
Next step could be to use trial and error with those 8 sequences (=T) in combination with ‘+’ (=E). If this won’t work, Z had not used any solid sequences as in the 408 cipher – which imho would make the 340-cipher completely unsolvable unless somebody finds a different but solid sequential structure in the cipher.
Not to forget: 10.0 could match the letter ‘A’ as well (if over-frequent), so could ‘+’ match the following letters as well:
A 8.04
O 7.60
I 7.26
N 7.09
S 6.54
R 6.12
H 5.49
L 4.14
leading to approximately 8x2x8 = 128 different possibilites to start solving the 340 with about 17% covered by two preferred (first: T/A second: ETAOINSRHL letters. Sounds tough but seems to be much better than just guessing 1,000,000,000,000 different possibilities..
Sequential cipher analysis leading to one of a maximum of ~150 cipher masks to start with (here assuming T being represented by the first of eight possible L=8 sequences in combination with L being above average present (‘+’ = 7% instead of ~4%):

QT
*ZODIACHRONOLOGY*

I’ve added finding sequences with L>7 to my todo list. I’ll let you know when I get around to working on it.
And I still wonder if some re-arrangement of the cipher text will produce improved sequences of homophones.
Thanks…inbetween I think I figured out already – the eight possibilities above seem to be the only L=8 sequences…have not found anything else and don’t believe any modifications of the cipher should be necessary (hard enough anyhow). ‘+’ could be a single homophone for ‘N’ or ‘O’ as it occurs as a double letter with a frequency of approximately 7.50%.
Most L=7 sequences contain symbols present in the L=8 sequences mentioned above. Only two sequences (starting, repeating twice, without any interrupting symbol) are completely different
[H^VOKMz] [H^VOKMz] (14.41%)
[HlVOKMz] [HlVOKMz] (14.71%)
which potentially represent the letter ‘E’. Best try could be to take all homophones present in all sequences:
‘HVOKMz’ = E
‘>_94’ = T
‘+’ = N or O
Problem is that if the sequence of L=7 is actually a L=6, one letter would occur although acutally not being present..using above leads to a potentially negative result, so we still got to change something..
QT
QT
*ZODIACHRONOLOGY*