At the moment I am reading myself a little deeper into the subject. So if I repeat something that has already been mentioned, I’m sorry. I can’t contribute much yet, but I used the opportunity to use my statistics tool and cipher generator in practice. I have used Project Gutenberg’s "Dracula" as source and created lots of encryptions. I filtered all results that have at least a raw ioc of 2200 and a distance score of at least 15034. Here are the results (don’t rely on them … my tool is still in beta phase) :
Ciphers analyzed: 1937 (each from period 1 to 170) 0% Randomization (Perfect Cyles): 27 ciphers matched or exceeded target score 10% Randomization: 11 ciphers matched or exceeded target score 20% Randomization: 2 ciphers matched or exceeded target score Used key: dDiZ94bekBHax3y+0PfgIEJF2phcC5mj:uU;Aq7RX=YOnGVto1zKMLw8sNrvSQl-TW AAAABBCCDDDEEEEEEEEEFGGHHHIIIIJKLLLMNNNNOOPQRRRRSSSSSTTTTTUUUVWXYZ
I couldn’t find any encryption where a high distance score and a high raw ioc occurred on period higher than 1. That is not surprising. If the high distance score in z340 is not a phantom then this could be another evidence that z340 was not transposed >after< homophonic substitution (which is almost ruled out anyway).
The less cyclic the encryption is, the less frequently high distance scores occur. This is also no surprise. But here z340 stands out…again. Its not perfect cyclic but has a high distance score.
Another thing: It is curious that AZDecrypt takes longer than usual for many of the found encryptions. I don’t have enough analysis material to rule out coincidence. I just noticed it.
Here are some examples (if you like to have more I can generate them):
Raw ioc: 2289, Distance 15224
Fax;YLTQ3hAol2cbp YCqyIXnF5;m=27ld1 wXEhQ+pcz9:=XkDKF 0CM82P;=GfTXrRJiA BosV=qENpZ7;gFatx dnL2vGwX=j;TpDRHi AklVSqJ58FZtBh71c u3Rey4rsAXlT=vdn+ 20GPTXSDVf;=tgEX= HNpiqrzXUk=nTXv7J lF=LXC:;Sb25Rwpal =GuBXI8F=rE2sXvVA xtQ3KZnyq=NMXedU; D7H=SG9:X=kRXLo=4 VhJpw8FiATXrt1Zns 2vGNSVq+BL=pc;d7H zDCk5ITXr=RuTjA0l FXlEUiB:Thl=vuHkc PIXt2fnT=SlXrUBvq HgGKwZ7kpaM8=YYxB
Raw: 2261, Distance 15944
lhLFdoXnw=Ib2Xjac ApC1Q=5exEX=k9XTz DhBQiqF3:Kc7JCR82 yA=sMXIZG=IITXrl5 uU4+pdYYTNFDLT=v2 iQ0HXqPZ:uI=VpftT XSU=QgbX;a7=ldRk9 xoh:3AwTXr1FDuUjc zK2yn=qe+40IXGPC8 5MB=7f9vsNpgRTXS; roLE=iAHTXv;S1w:a ZQxd8;TzhJqKDT7=l XVks=;iBZ;3TXrjR= lFXlcNCMl5L2pytwF +n0;vo84PA=12Xbjd qTj7=lufHEgXIsphz l=SUk9aXRxe=;3lyD :ul+ANrYLXUvbTKG= X;iVwFSt4TBcn0e8C =qGP;Z57fHXrsMhkg
Raw: 2663, Distance: 15184
;aXAx:=XjIn=;TXrl huUlcY3dlDTi:uLFC o1=zZk2XvGI=V5lXS UBH=lpdwD;iqbZ78X KdQyT=rItX;M=nGXl mvosNFhRjI=Vl2T1p XS:kcECQ+;Tz0uIK= ;reFXIUD9=vtiABMX ;Sb2=IoXnG=l5pZQP eX;fFgVaIt=;;TXlq :d7HL=kXl2DwhbiR= IJX=BZ8spxIcn1NLX Yu3dzy;TIGC+AHm=F qD7kw20R8XpPUYiKl fgsT=rAE:ZBTlFX;N =X5ed;aL=uXQxI=V2 3thD;iMpZ;yHwXodT 1=;vbF4S8czDTCs5q jh7kR+KMcJiQ0l2ZN TXrEdQPLpf9U=XB=I

In the 340 there are very few unigram repeats over short distances, especially when taking in consideration its higher ioc per cipher length than the 408. This is why we see 9 rows which have no repeats, it is not easily connected to transposition after/during encoding and typical encoding randomization.
I did another test comparing unigrams in rows and columns. The idea is this:
Take a symbol, then count how many columns it is in. For example, there are three P symbols but they appear in only two columns.
Make these counts for every symbol, then the final measurement is the sum of the counts.
Cool measurement doranchak. I have verified your numbers, added normalization and gave it a name if you do not mind.
340: Unigram row coverage: - Raw: 322 - Normalized: 0.9583333333333334 Unigram column coverage: - Raw: 284 - Normalized: 0.8528528528528528 408: Unigram row coverage: - Raw: 380 - Normalized: 0.9313725490196079 Unigram column coverage: - Raw: 337 - Normalized: 0.8259803921568627
The following test encoded each message of my plaintext library a 100 times with cyclic homophonic substitution (26% cycle randomization) while targetting the ioc of the 340. It covers 10000 samples. The 340 appears to line up very well except for unigram distance and rows with no unigram repeats.
Test average versus 340:
Average raw ioc: 2236.09 versus 2236
Average 2-symbol cycles: 2139.03 versus 2137
Average 3-symbol cycles: 5999.64 versus 5922
Average perfect 2-symbol cycles: 1480.27 versus 1576
Average perfect 3-symbol cycles: 930.58 versus 1060
Average unigram repeats: 21.17 versus 18
Average unigram distance: 13756.88 versus 15034
Average unigram row coverage: 318.76 versus 322
Average unigram column coverage: 284.15 versus 284
Average rows with no unigram repeats: 6.55 versus 9
Average columns with no unigram repeats: 0.27 versus 0
The less cyclic the encryption is, the less frequently high distance scores occur. This is also no surprise. But here z340 stands out…again. Its not perfect cyclic but has a high distance score.
I am glad you came to the same conclusion. If not an outlier then here are some ideas of mine (from the 2nd page of this thread).
Here are my 2 most likely hypotheses for the high unigram distance in the 340:
1. The high unigram distance of the 340 is related to the group of symbols that do not appear in the middle 7 rows (as marie said).
2. A long key (as Largo said) is used in the homophonic substitution process and some of the most frequently occuring symbols are for whatever reason not part it or are wildcards. Likely hypotheses for the symbols that were not taken up in the homophonic substitution or are wildcards are that these are 1:1 substitutes, plaintext nulls or wildcards (as smokie said). I would like to go as wide as possible with the interpretation of wildcards.In your test my cipher jarlve2 very closely matches the 340 which is hypothesis 2. Some things to look in may be exotic cycling types (again) such as palindromic cycling which also increases unigram distance and not trying to repeat symbols in a certain view window as opposed to actively cycling homophones.
I have tested the no repeat view window hypothesis and it does not produce a high unigram distance so that can be ignored. Palindromic cycling has also been tested by doranchak but still has my interest.
Crude example of hypothesis 2:
1-gram frequencies > 0: -------------------------------------------------------- +: 24 B: 12 p: 11 |: 10 O: 10 c: 10 F: 10 <--- Symbols above this line much more likely to be 1:1 substitutes, not part of the key. Symbols under this line are part of a long (efficient) key. 2: 9 z: 9 R: 8 l: 7 (: 7 K: 7 M: 7 5: 7 ^: 6 V: 6 L: 6 G: 6 W: 6 .: 6 <: 6 *: 6 4: 6 k: 5 T: 5 d: 5 N: 5 #: 5 ): 5 y: 5 U: 5 -: 5 C: 5 H: 4 >: 4 D: 4 Y: 4 f: 4 Z: 4 J: 4 S: 4 8: 4 9: 4 t: 4 E: 3 P: 3 1: 3 7: 3 _: 3 /: 3 ;: 3 b: 3 6: 3 %: 2 :: 2 3: 2 j: 2 &: 2 q: 2 X: 2 A: 2 @: 1
I have added the standard deviation to my analysis tool.
Unigram based measurements results of the 340 versus 1.000.000 randomizations:
Unigram repeats by rows, sigma of 18: 5.39
Sliding unigram repeats (slide window=17), sigma of 364: 5.66
Unigram row coverage (doranchak’s new test), sigma of 322: 5.39
Unigram column coverage (doranchak’s new test), sigma of 284: 0.46
Rows that have no unigram repeats, sigma of 9: 7.01
Columns that have no unigram repeats, sigma of 0: 0.60
Unique sequence length 17 repeats, sigma of 26: 7.89
Unigram distance, sigma of 15034: 4.23
Unigram based measurements results of the 340 versus plaintext 1 to 100 + sequential homophonic substitution (26% cycle randomization) raw ioc target 2236 totalling 100.000 samples:
Unigram repeats by rows, sigma of 18: 0.73
Sliding unigram repeats (slide window=17), sigma of 364: 0.39
Unigram row coverage (doranchak’s new test), sigma of 322: 0.73
Unigram column coverage (doranchak’s new test), sigma of 284: 0.01
Rows that have no unigram repeats, sigma of 9: 1.18
Columns that have no unigram repeats, sigma of 0: 0.53
Unique sequence length 17 repeats, sigma of 26: 2.51
Unigram distance, sigma of 15034: 2.32

Thanks for that nice summary, Jarlve. The unigram observations have been very interesting.
I tested your unigram distance measurement on a per-symbol basis, by tracking the distance sums for individual symbols and comparing to shuffles. Here are the results, limited to outlier symbols that had sigma greater than 1 or less than -1:
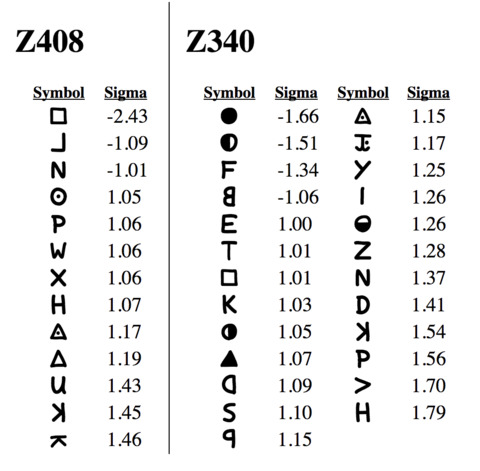
Observations:
1) Z340 has almost twice as many outliers under this criterion (abs(sigma) >= 1.0)
2) The most anomalous symbol behavior happens in Z408 for the empty square symbol, with sigma of -2.43. The reason is because it stands for plaintext "Y" which is clustered in the 2nd half of the cipher (due to repetitions of words MY and YOU).


3) In Z340, filled circle (sigma -1.66) and left filled circle (sigma -1.51) have low sigma due to apparent clustering of symbols. Z408 shows some clustering for empty square and backwards L.



4) In Z340, higher sigma symbols such as H, >, P, and backwards K result from being unusually spread out (as has been already discussed).

Thank you doranchak,
These visuals will help people to understand the unigram distance measurement on an intuitive level.
1) Z340 has almost twice as many outliers under this criterion (abs(sigma) >= 1.0)
I am trying to find out if the high unigram distance of the 340 is related solely to the symbols that have large gaps between them or if it is a more widespread phenomenon. What do you think?

Here is another similar visualization, but with the new font thanks to Largo and doranchak. It just looks so awesome I can’t get over it. Plus I got a big new high definition monitor plugged into my little laptop so I can see it really big.
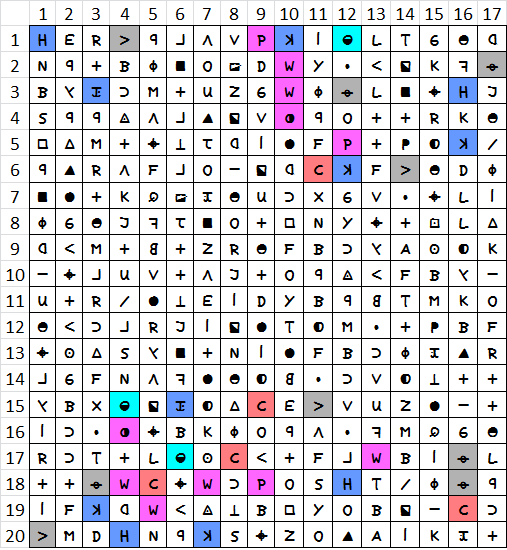
I am trying to find out if the high unigram distance of the 340 is related solely to the symbols that have large gaps between them or if it is a more widespread phenomenon. What do you think?
My hunch is it is more widespread. Here’s an idea for a test:
1) Remove the symbols that have large gaps between them
2) Measure unigram distance for the now shorter cipher text
3) Compare to shuffles of the shorter cipher text
4) See what effect the symbol removal has on sigma.
Another approach could be this:
1) Select some integer "k"
2) Determine the set of k symbols that has greatest effect on sigma, by testing removals of all combinations of k symbols.
I.e., the goal of this test would be to identify a specific set of symbols that has the greatest effect on unigram distance.
Here is another similar visualization, but with the new font thanks to Largo and doranchak. It just looks so awesome I can’t get over it. Plus I got a big new high definition monitor plugged into my little laptop so I can see it really big.
Yes! That does look very good. And more impactful than a pile of numbers. ![]()
My hunch is it is more widespread. Here’s an idea for a test:
1) Remove the symbols that have large gaps between them
2) Measure unigram distance for the now shorter cipher text
3) Compare to shuffles of the shorter cipher text
4) See what effect the symbol removal has on sigma.
Good idea. I changed my unigram distance measurement to only log distances under 171. The 340 scores 12514 then.
Versus randomizations it is a 2.07 sigma. Not unexpected since unigram distance is a property of sequential homophonic substitution.
Versus a sequential homophonic substitution with 26% cycle randomization hypothesis it is a -0.19 sigma. This tells us that versus such a hypothesis, the observation is not widespread and local to the symbols that have large gaps between them (what I wanted to find out). The distribution seems important, I need to ponder this.
Here is another result to add to your pondering.
Earlier I posted the outliers in my unigram distance sum per symbol tests:
Z408 has 13 outliers and Z340 has 25 outliers.
Compared to 1000 shuffles, are the outlier counts unusual?
Result:
1) Z408’s outlier count is -1.72 sigma below the mean outlier count observed during shuffles.
2) Z340’s outlier count is 0.68 sigma above the mean outlier count observed during shuffles.
So, I suppose we can conclude that Z408 shows fewer unigram distance outliers than expected, and Z340 shows a little more than expected, at least compared to randomizations.
Using regular unigram distance, versus a sequential homophonic substitution with added cycle randomization hypothesis the 408 (first 340 characters) has a -0.75 sigma and the 340 has a 2.32 sigma. Logging distances over 170 only, the sigma goes up to 2.85 for the 340, yet versus randomizations it goes down from 4.23 to 1.37.
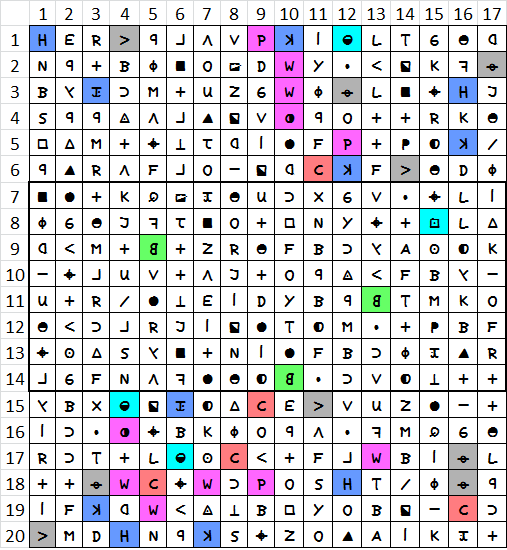
The four symbol-positions unique to the middle 8 rows interest me as well.
I P 20 transposed and homophonic encoded most of Brave New World with a key that was a little less efficient than one that exactly matches plaintext frequencies, with one polyphone to simulate the +, closely matching symbol and polyphone count on average, 768 messages total ( it only took a few minutes with my new spreadsheet suite that would have taken me hours before ). EDIT: 25% random.
Left column is count of symbols unique to both top 6 rows and bottom 6 rows, right column is number of messages with that count. The 340 has 39 symbol-positions. None of my messages had 39, and the most was one message that had 34. The average was only 12.
EDIT: After typo in formula fixed, same test, but different messages because of random symbol selection at 25%. Average is still 12. There were two of 768 that had 35 in this batch.
1 0
2 23
3 18
4 20
5 36
6 35
7 36
8 46
9 53
10 53
11 46
12 53
13 33
14 42
15 30
16 34
17 39
18 22
19 34
20 18
21 18
22 15
23 11
24 10
25 4
26 4
27 3
28 4
29 3
30 2
31 1
32 1
33 0
34 0
35 2
36 0
37 0
38 0
39 0
40 0
Left column is count of symbol-positions unique to the middle 8 rows, right column is number of messages with that count. The 340 has only 4 symbols, and only three of 768 messages have 4 or fewer symbols.
EDIT: After typo in formula fixed. The average was 4, making the 340 very typical in the middle.
1 84
2 92
3 104
4 106
5 102
6 87
7 54
8 35
9 20
10 10
11 9
12 0
13 2
14 1
15 0
16 0
17 1
18 0
19 0
20 0
21 0
22 0
23 0
24 0
25 0
26 0
27 0
28 0
29 0
30 0
31 0
32 0
33 0
34 0
35 0
36 0
37 0
38 0
39 0
40 0
Well this does not fit the transposition + nulls, skips & filler + homophonic +/- 63 + polyphone +/- 24 model.
We have seen that regional Caesar shifting the letters in a key like this one, but keeping the homophones in place, makes it easy to create a lot of symbol-positions unique to the top 6 and bottom 6 rows, but make it difficult to make repeats and only four symbol-positions unique to the middle 8 rows. Shifting the homophonic symbols and keeping the letters in their place would be the same thing.
E 1 2 3 4 5 6 7 68
T 8 9 10 11 12 68
O 13 14 15 16 68
A 17 18 19 20 68
I 21 22 23 24 68
N 25 26 27 28
H 29 30 31
S 32 33 34
R 35 36 37
D 38 39 40
L 41 42 43
U 44 45
C 46 47
W 48 49
M 50 51
G 52 53
Y 54 55
F 56 57
P 58 59
B 60 61
V 62
K 63
X 64
Z 65
Q 66
J 67
When I say 39 symbol-positions, I mean some number of different symbols occupying 39 positions total. In the case of the 340, there are 9 symbols occupying 39 positions. But only some of these 9 symbols are responsible for the phenomenon because most test messages have at least some unique symbol positions.
So of those 9 symbols, there is a small group that maybe he introduced to the key for the top / bottom, but did not use in the key in the middle. Is there a slow, subtle rotation of symbols through the key?
Or, did he use some type of creative cycling that causes this?
Or something else?
Could be 4-12-4, 5-10-5, 6-8-6, 7-9-7, or by position. Don’t know.
Left column is count of symbols unique to both top 6 rows and bottom 6 rows, right column is number of messages with that count. The 340 has 39 symbol-positions. None of my messages had 39, and the most was one message that had 34. The average was only 12.
Thank you for this excellent test. I will try to follow up on this.
So of those 9 symbols, there is a small group that maybe he introduced to the key for the top / bottom, but did not use in the key in the middle. Is there a slow, subtle rotation of symbols through the key?
Or, did he use some type of creative cycling that causes this?
Or something else?
Could be 4-12-4, 5-10-5, 6-8-6, 7-9-7, or by position. Don’t know.
It is insane. I do not know either.

The 4 symbols unique to the middle may be trivial. If you look at the outlier table that doranchak put up for the 340 and 408 it can be seen that a symbol in the 408 has a -2.43 sigma (because it maps to the letter "Y" that only appears in the third part of the cipher). It is just one of many distributions that all happen to be equally unlikely (for only a handful of symbols).
The symbols that do not appear in the middle 8 rows are where the money is at.
Moonrock, out of all his cycle types considered regional cycling for the 340.
The 4 symbols unique to the middle may be trivial. If you look at the outlier table that doranchak put up for the 340 and 408 it can be seen that a symbol in the 408 has a -2.43 sigma (because it maps to the letter "Y" that only appears in the third part of the cipher). It is just one of many distributions that all happen to be equally unlikely (for only a handful of symbols).
The symbols that do not appear in the middle 8 rows are where the money is at.
Moonrock, out of all his cycle types considered regional cycling for the 340.
Well, I don’t know.
Thanks to marie, by the way, to help us focus on this issue.
Since the last test was of transposed plaintext, I figured to try with untransposed plaintext, since maybe certain words could appear at the bottom and top but not the middle. I thought that this would maybe produce a few more results similar to the 340.
Left column is count of symbols unique to both top 6 rows and bottom 6 rows, right column is number of messages with that count. The 340 has 39 symbol-positions. Only one of the 768 test messages had 39. The next closest one had 32. This is all with no transposition, and the average is 11, very similar to with transposition.
EDIT: Similar data for top and bottom after typo in formula fixed, just new batch and average is now 12.
1 0
2 20
3 13
4 33
5 44
6 44
7 39
8 61
9 51
10 52
11 51
12 46
13 40
14 37
15 48
16 30
17 20
18 25
19 21
20 16
21 10
22 13
23 11
24 8
25 8
26 7
27 4
28 3
29 2
30 1
31 2
32 0
33 0
34 1
35 1
36 0
37 0
38 0
39 0
40 0
Left column is count of symbol-positions unique to the middle 8 rows, right column is number of messages with that count. The 340 has only 4 symbols, and this time, with no transposition, none of the 768 messages have 4 or fewer unique symbol-positions. There was like one that had 5 and three that had 6.
EDIT: New data after typo in formula fixed. This is very different because 4 is the average for the middle of a 6-8-6.
1 92
2 102
3 130
4 99
5 86
6 63
7 42
8 39
9 22
10 16
11 10
12 5
13 0
14 1
15 1
16 0
17 2
18 0
19 0
20 0
21 0
22 0
23 0
24 0
25 0
26 0
27 0
28 0
29 0
30 0
31 0
32 0
33 0
34 0
35 0
36 0
37 0
38 0
39 0
40 0
So both with and without transposition, the results are similar.
If you have to fix a car that isn’t running, then start with the simplest, cheapest solution and the cheapest parts. Since it was a paper and pencil cipher, and changing the key throughout seems like overkill after alleged transposition, maybe just some creative cycling. There have to be other options besides what moonrock said. Finding a cycle model that fits may not lead to a solution, but it would be interesting to see if we can. I would say a cycle model that only results in a just a few unique symbol-positions in the middle portion of the message as well.
EDIT: Or a different key model. Like maybe mapping a whole lot of symbols to a few high frequency plaintext together with some 1:1. Would this fit other stats?