
Okay smokie,
I am now using the same measurement as you, 39 unigrams that appear in the top and bottom 6 rows but not in the middle 8 rows. This count of 39 is the score.
– Versus randomizations of the 340 it is a 2.37 sigma observation (mean 20).
– Versus randomized plaintexts + sequential homophonic substitution with 26% cycle randomization hypothesis it is a 5.12 sigma observation (mean 10).
– Versus randomized plaintexts + 6-8-6 caesar shift + sequential homophonic substitution with 26% cycle randomization hypothesis it is a -2.23 sigma observation (mean 68).
That seems to line up with your tests does it not? The observation correlates better with randomizations than with a regular sequential homophonic substitution hypothesis… Also with the caesar shifts, it seems you only need to shift the middle 8 rows to get the effect since my results were nearly indentical between these two, could be a time saver.
Finding a cycle model that fits may not lead to a solution, but it would be interesting to see if we can.
Okay. Preferably in a new dedicated thread.
10. The regional cycle, which restricts substitutions to or from specific regions, or areas, of the ciphertext; this restriction typically manifests as either a restriction to specific rows or to specific columns, and, if used exclusively, is the equivalent of a series of simple substitutions.
Where did he come up with this stuff?
This moonrock personage is really intriguing to me. He really knows what he is talking about. This is not some guy who invented some cycle systems on the fly. What the hell?

10. The regional cycle, which restricts substitutions to or from specific regions, or areas, of the ciphertext; this restriction typically manifests as either a restriction to specific rows or to specific columns, and, if used exclusively, is the equivalent of a series of simple substitutions.
Where did he come up with this stuff?
This moonrock personage is really intriguing to me. He really knows what he is talking about. This is not some guy who invented some cycle systems on the fly. What the hell?
I know. He apparently has put a great deal of thought into the cycles. He showed up out of the blue, made a really good post that still lingers with us, and then just disappeared. Weird!
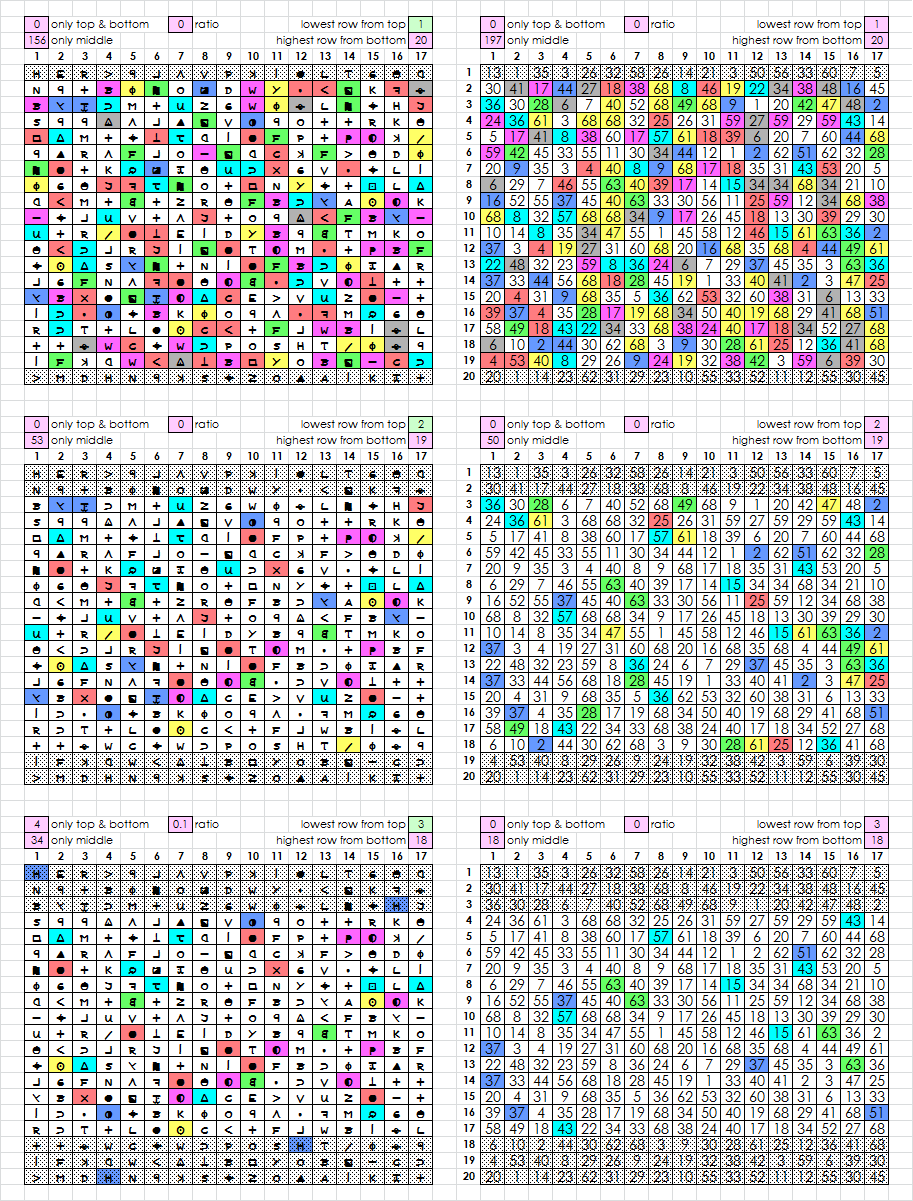
Here is a progression by rows, 340 on the left and an average message from my first experiment, with transposition, on the right. If a cell is colored, that means that it is unique to the region(s), whether top / bottom or middle.
13 1 35 3 26 32 58 26 14 21 3 50 56 33 60 7 5
30 41 17 44 27 18 38 68 8 46 19 22 34 38 48 16 45
36 30 28 6 7 40 52 68 49 68 9 1 20 42 47 48 2
24 36 61 3 68 68 32 25 26 31 59 27 59 29 59 43 14
5 17 41 8 38 60 17 57 61 18 39 6 20 7 60 44 68
59 42 45 33 55 11 30 34 44 12 1 2 62 51 62 32 28
20 9 35 3 4 40 8 9 68 17 18 35 31 43 53 20 5
6 29 7 46 55 63 40 39 17 14 15 34 34 68 34 21 10
16 52 55 37 45 40 63 33 30 56 11 25 59 12 34 68 38
68 8 32 57 68 68 34 9 17 26 45 18 13 30 39 29 30
10 14 8 35 34 47 55 1 45 58 12 46 15 61 63 36 2
37 3 4 19 27 31 60 68 20 16 68 35 68 4 44 49 61
22 48 32 23 59 8 36 24 6 7 29 37 45 35 3 63 36
37 33 44 56 68 18 28 45 19 1 33 40 41 2 3 47 25
20 4 31 9 68 35 5 36 62 53 32 60 38 31 6 13 33
39 37 4 35 28 17 19 68 34 50 40 19 68 29 41 68 51
58 49 18 43 22 34 33 68 38 24 40 17 18 34 52 27 68
6 10 2 44 30 62 68 3 9 30 28 61 25 12 36 41 68
4 53 40 8 29 26 9 24 19 32 38 42 3 59 6 39 30
20 1 14 23 62 31 29 23 10 55 33 52 11 12 55 30 45
You can see a big difference in symbols only appearing in the middle for 3-14-3. Almost twice as many. 34 for the 340 and 18 for the test message.
And then the difference starts to get more dramatic stepping into 4-12-4, 5-10-5, and 6-8-6.

They get more similar with 7-6-7, 8-4-8 and 9-2-9, except that with 8-2-8 there is a big difference between the top / bottom counts.
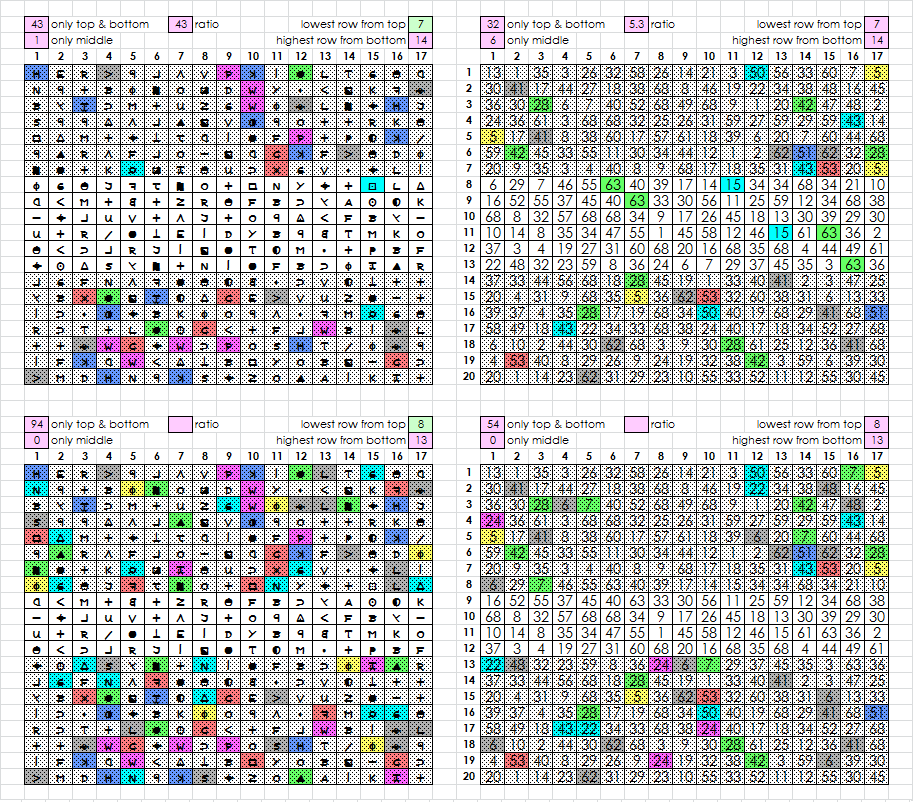
9-2-9 the same again.
Here is a better visual, if you can see it:
https://drive.google.com/drive/folders/ … vJv7urWX7e
EDIT: I could see it. The thin blue line shows the regions. More comparisons coming soon.
The visuals are fine. Do you think something special is going on besides 6-8-6?
The visuals are fine. Do you think something special is going on besides 6-8-6?
Yes I do. I believe that 6-8-6 is just a glimpse into something more. Here is another slideshow. I chose three messages from the experiment at random, all transposition P20. I changed the color scheme to make it easier to focus on the issue. Watch the progression.
1-18-1 similar
2-16-2 similar
3-14-3 similar
4-12-4 there is a shift, with more symbol positions unique to both regions
5-10-5 more in top bottom
6-8-6 more in top bottom
7-6-7 more in top bottom
8-4-8 more in top bottom
9-2-9 similar
https://drive.google.com/drive/folders/ … wds7LLjwLz
You were right about the middle in 6-8-6. I had a typo in one of my formulas and will be going back to update the data a few posts above shortly. Just a few symbol positions in the middle is very common.
Here is another example, but three randomly selected messages from the experiment not transposed. The comparisons are about the same.
1-18-1 similar
2-16-2 similar
3-14-3 similar
4-12-4 there is a shift, with more symbol positions unique to both regions
5-10-5 more in top bottom
6-8-6 more in top bottom
7-6-7 more in top bottom
8-4-8 more in top bottom
9-2-9 similar
https://drive.google.com/drive/folders/ … 1MYD8jSofY
The visuals are fine. Do you think something special is going on besides 6-8-6?
Yes I do. I believe that 6-8-6 is just a glimpse into something more. Here is another slideshow. I chose three messages from the experiment at random, all transposition P20. I changed the color scheme to make it easier to focus on the issue. Watch the progression.
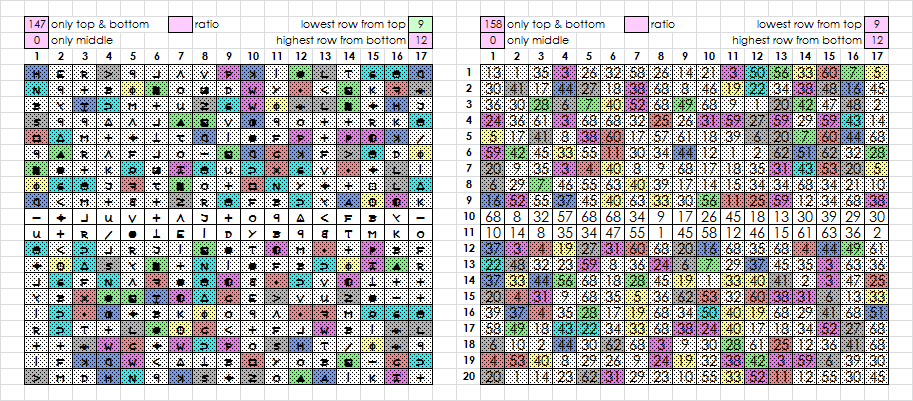
Here are my results versus a randomized plaintext + sequential homophonic substitution with 26% random homophone selection hypothesis. They line up with yours. Row divisions 4-12-4 and 6-8-6 are most significant, that is roughly by thirds. Though, I currently see no reason to believe there is more to it. Can you formulate "something more" yet?
Row division: top-bottom unique unigram count, sigma -------------------------- 1: 0, -0.17 2: 0, -0.38 3: 4, 2.04 4: 15, 5.39 <--- 5: 20, 4.20 6: 39, 5.15 7: 43, 2.32 8: 94, 3.14 9: 147, 0.88
And versus randomizations of the 340:
Row division: top-bottom unique unigram count, sigma -------------------------- 1: 0, -0.20 2: 0, -0.45 3: 4, 1.02 4: 15, 2.93 <--- 5: 20, 1.89 6: 39, 2.37 7: 43, 0.30 8: 94, 1.24 9: 147, -0.22
He didn’t make a key, then cycle through his symbols, and +/- 25% of the time randomly select from the homophone groups. A person could match the L=2 cycle scores by doing that, but that is not what he did because if he did that there would not be the regional biases that we see. I think that the regional biases are a clue to how he encoded the messages, one that we can actually see.
He either selected the symbols from his key in some way by position or row, or used some type of creative cycle. Because the top and bottom parts have the same symbols but those symbols are not in the middle.
One possibility is that he gradually added symbols from the beginning to the middle, then gradually removed symbols from the middle to the end.
Or sounding more like what we see, vice versa, gradually removing symbols from the key from the beginning to the middle, then gradually adding the removed symbols from the middle to the end.
He could have had a key made into a grid, and selected by row, moving to one side of the grid toward the middle, then moving from the middle to the other side of the grid.
Or, maybe a cycle that overlaps itself, sort of like:
A B C D
B C D A
C D A B
D A B C
A B C D
Rough ideas.

Left column is count of symbols unique to both top 6 rows and bottom 6 rows, right column is number of messages with that count. The 340 has 39 symbol-positions. None of my messages had 39, and the most was one message that had 34. The average was only 12.
This regional bias for certain symbols continues to be interesting. I have tried to confirm the significance of the observation via one million randomizations of Z340.
Z340 has 10 symbols that occur only in the first or last six lines (Yes, I love showing this font! ![]() ):
):
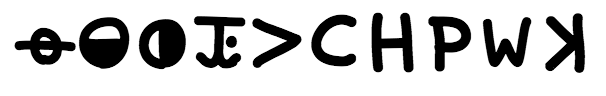
This is a 0.83 sigma observation compared to randomizations. About 1 in 4 shuffles has at least that many symbols exclusive to those lines.
The 10 exclusive symbols occupy 39 positions of Z340. This is a 1.66 observation compared to randomizations. About 1 in 16 shuffles had at least that many positions occupied by symbols exclusive to those lines.
I am curious about other regions that show symbol exclusivity, such as the middle 8. I am going to try to run a brute force search for exclusive symbol counts for all selections of rows. Then hopefully compare to a similar search using columns.
I am curious about other regions that show symbol exclusivity, such as the middle 8. I am going to try to run a brute force search for exclusive symbol counts for all selections of rows.
Here are the full raw results; I haven’t organized them to summarize the interesting bits.
http://zodiackillerciphers.com/z340-exc … ctions.txt
(Warning: it’s a 54 megabyte text file)
To compare against the known result for the 12 rows (6 at the beginning and 6 at the end), here is a sampling of some of the best selections of rows.
n rows symbols count positions 12 [0, 1, 2, 4, 5, 7, 10, 14, 16, 17, 18, 19] )/1:>@CDEHPWY_jk 16 57 12 [0, 1, 2, 4, 6, 7, 10, 12, 14, 16, 17, 18] #%)/19:@ELPWXY_j 16 54 12 [0, 1, 2, 4, 6, 7, 10, 11, 14, 16, 17, 18] %&)/1:@ELPTWXY_j 16 52 12 [1, 2, 4, 6, 7, 8, 11, 12, 13, 14, 15, 19] #%&.49:;@ANXZfjq 16 52 12 [0, 1, 2, 4, 6, 7, 8, 12, 14, 16, 17, 19] #%)169:;@AHLPXZj 16 51 12 [0, 1, 2, 4, 5, 8, 10, 14, 16, 17, 18, 19] )/1:>ACDEHPWZdk 15 58 12 [0, 1, 2, 4, 5, 7, 8, 14, 16, 17, 18, 19] )1:>@ACHPWZ_djk 15 54 12 [0, 1, 2, 4, 5, 6, 7, 14, 16, 17, 18, 19] %)1:>@CHLPWX_jk 15 53 12 [1, 4, 6, 7, 8, 10, 11, 12, 13, 14, 15, 18] %&.459@XY_bfjqt 15 52 12 [2, 4, 6, 7, 8, 9, 10, 11, 12, 13, 14, 19] &459:;@AJUXZbjy 15 52 12 [0, 1, 2, 4, 6, 7, 12, 14, 16, 17, 18, 19] #%)19:;@HLPWX_j 15 51 12 [0, 2, 4, 5, 6, 7, 8, 14, 16, 17, 18, 19] 1:>@ACHLPXZ_djk 15 51 12 [1, 4, 6, 7, 10, 11, 12, 13, 14, 15, 18, 19] %&.59;@NXY_fjqt 15 51 12 [1, 4, 6, 7, 8, 10, 11, 12, 13, 14, 15, 19] %&.459;@ANXbfjq 15 51 12 [0, 1, 2, 4, 5, 6, 7, 10, 14, 16, 17, 18] %)/1:@CELPWXY_j 15 50 12 [0, 1, 2, 4, 6, 7, 9, 10, 14, 16, 17, 18] %)/1:@ELPUWXY_j 15 50 12 [0, 1, 2, 6, 7, 8, 12, 13, 14, 15, 16, 19] #%16:;@AGLNXZfq 15 50 12 [0, 2, 4, 5, 7, 8, 12, 14, 16, 17, 18, 19] 169:>@ACHPZ_djk 15 50 12 [1, 2, 4, 6, 7, 10, 11, 12, 13, 14, 15, 18] #%&.59:@XY_fjqt 15 50 12 [1, 2, 4, 6, 7, 8, 10, 11, 12, 13, 14, 19] #%&459:;@ANXZbj 15 50 12 [1, 4, 6, 7, 8, 10, 11, 12, 13, 14, 18, 19] %&459;@ANXY_bjt 15 50 12 [0, 1, 2, 4, 5, 7, 8, 10, 14, 17, 18, 19] /:>@ADEHPYZ_djk 15 49 12 [0, 1, 2, 4, 6, 7, 10, 13, 14, 16, 17, 18] %)/1:@ELPWXY_jt 15 49 12 [0, 1, 2, 4, 6, 7, 10, 14, 16, 17, 18, 19] %)/1:@EHLPWXY_j 15 49 12 [0, 2, 4, 5, 6, 7, 8, 12, 14, 16, 18, 19] 169:;>@ALXZ_djk 15 49 12 [0, 2, 4, 5, 7, 8, 10, 14, 16, 17, 18, 19] /1:>@ACEHPZ_djk 15 49 12 [1, 2, 4, 6, 7, 8, 9, 11, 12, 13, 14, 19] #%&49:;@AJNXZjy 15 49 12 [0, 1, 2, 4, 6, 7, 10, 11, 12, 14, 16, 17] #%&)/19:@ELPTXj 15 48 12 [0, 1, 2, 4, 6, 7, 10, 12, 14, 16, 17, 19] #%)/19:;@EHLPXj 15 48 12 [0, 1, 2, 4, 6, 7, 9, 10, 11, 14, 16, 17] %&)/1:@EJLPTUXj 15 48 12 [0, 2, 4, 5, 7, 8, 10, 13, 14, 17, 18, 19] /:>@AEHPZ_bdjkt 15 48 12 [0, 1, 2, 4, 6, 7, 10, 14, 15, 16, 17, 18] %)/1:@ELPWXY_jq 15 47 12 [1, 2, 4, 6, 7, 8, 10, 12, 13, 14, 18, 19] #%9:;@ANXYZ_bjt 15 46 12 [0, 2, 4, 6, 7, 8, 10, 12, 14, 16, 17, 19] /169:;@AEHLPXZj 15 45
That may be an example of seeing the tail end of the bell curve for "symbol exclusivity", since I am not restricting row selection to specific patterns of rows.
Moonrock, out of all his cycle types considered regional cycling for the 340.
My hypothesis was that the 340 cipher used a combination of regional cycles and semi-regional cycles for the nine most common English plaintext letters and likely more typical methods thereafter due to the less frequent letters not having as many substitutions to work with. This is evidenced by (1) the combined frequency of all ciphertext letters that appear regionally and semi-regionally roughly matching the combined frequency of the nine most common English plaintext letters, and (2) ciphertext letters M and backward L alternating with each other perfectly for the entire cipher and having a combined frequency matching English plaintext letters D and L, which are the 10th and 11th most common English plaintext letters, having a similar frequency and not being close to other letters in frequency, thus acting as a barrier between the high frequency letters and the other letters of the alphabet.
I created multiple test ciphers to test this after someone suggested to do so and found that it was easy to manually produce ciphers that have similar statistical characteristics to the 340 cipher. However, all of these ciphers were easily decipherable. That implies that if my work is correct, then likely a transposition method was used before homophonic substitution and that that is the reason why the 340 cipher hasn’t been deciphered.
Something worth mentioning about regional and semi-regional cycles is that you can get a good guess of what plaintext letters a ciphertext letter might be substituting by looking at its frequency in areas where it does occur (in the case of regional cycles) or where its frequency is high (in the case of semi-regional cycles). These are only estimations, but consider ciphertext symbol W, which is limited to two areas of the ciphertext and has a high frequency in both areas. In that case, it isn’t a stretch to assume that W is substituting a high frequency letter.
Another way to approach these two cycles is that ciphertext letters that behave inversely may be substituting the same plaintext letter whereas ciphertext letters that behave the same are unlikely to be the same plaintext letter, meaning that W is unlikely to be substituting the same letter as the circle with a horizontal line through it since these two symbols both only occur in the same lines as each other. It is more likely then that W is grouped with ciphertext letters that either don’t occur where it occurs or occur at a relatively low frequency where it occurs.
