Thanks for looking into this David. It is good to have your insight.
It might be a good idea to look at the KE data for these test ciphers, to see how often such peaks occur for non-random cipher texts with real messages: https://docs.google.com/spreadsheets/d/ … sp=sharing (I see that smokie already did something like that in this thread with his own generated ciphers).
David This is very interesting…. I have had a quick look and this very handy for testing in future.
The shuffling results is also of interest just mulling it over in my head…
I too have done a little bit of sanity checking and have a few findings to share with all. A while ago i generated a Vigenere cipher text which i have been using as a reference since. anyway i tried some of my test on it and came up with a typical coincidence vs shift graph.

As you can see there is a spike every 10 positions.
However when i plotted the IoC by column width i got a surprise
instead of the IoC dropping it peaked.

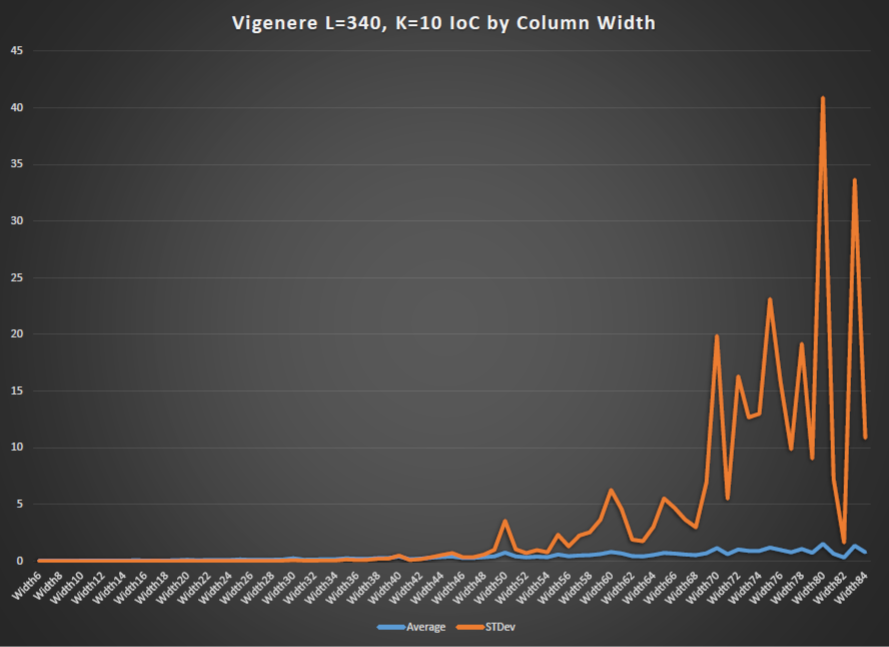
This was unexpected and so i need to review my code and for no my rule of thumb.
If this is the case then there is the possibility that Z340 has an underlying Vigenere with Valid key lengths of 6 13 26 39 78
To look deeper into the Vigenere i loaded 340 with the key of 408…
ending up with the following.
TEG.EANBII..TOA.OEEELNLNLN EU...SDHL..VHEIEAENHTLDTFA EESNAA.B.ENEEGS.YIHEDRXO.T SIER.IKEAGNSAN..O.IS..NNLT ESML..IVOAB.DT.NA.FDXLNEYE UDESTIO.HE.EEG.SLV.WE.S.DA IBENFENES.SL..IEGKTRE.NULE .OHSN..VAGF..TO.H.ERLSDEIA .LEE.TSLVN.AGAASENDT....VB .REE.LO....I.E.BIET.E.V..D LSNNEN.DHMA.GVOET.E..ESAEL .HTEEHE.DEVINATOKNHE.SIOE. SRLYUNL...V.HNTEEIADENAW.S .E
I then ran the text through a program i wrote a while a go which does a ceasar shift and reports the chi for each shift.
I choose the first and last columns for testing to get a feel for the cipher text. surprisingly the 0 shift is the low point for both tests.
testing the entire string also proved a reasonable Chi2 for plaintext
COL1 00, TEESEUILS ,CHI = 15.509 01, UFFTFVJMT ,CHI = 133.421 02, VGGUGWKNU ,CHI = 88.849 03, WHHVHXLOV ,CHI = 135.875 04, XIIWIYMPW ,CHI = 114.261 05, YJJXJZNQX ,CHI = 1215.275 06, ZKKYKAORY ,CHI = 297.895 07, ALLZLBPSZ ,CHI = 632.769 08, BMMAMCQTA ,CHI = 167.632 09, CNNBNDRUB ,CHI = 48.097 10, DOOCOESVC ,CHI = 36.901 11, EPPDPFTWD ,CHI = 65.085 12, FQQEQGUXE ,CHI = 1135.735 13, GRRFRHVYF ,CHI = 51.978 14, HSSGSIWZG ,CHI = 187.137 15, ITTHTJXAH ,CHI = 158.987 16, JUUIUKYBI ,CHI = 133.728 17, KVVJVLZCJ ,CHI = 555.033 18, LWWKWMADK ,CHI = 102.277 19, MXXLXNBEL ,CHI = 683.295 20, NYYMYOCFM ,CHI = 72.238 21, OZZNZPDGN ,CHI = 1364.304 22, PAAOAQEHO ,CHI = 134.582 23, QBBPBRFIP ,CHI = 206.461 24, RCCQCSGJQ ,CHI = 576.529 25, SDDRDTHKR ,CHI = 41.135 COL26 00, NATTEAEABDLS ,CHI = 15.655 01, OBUUFBFBCEMT ,CHI = 74.461 02, PCVVGCGCDFNU ,CHI = 79.861 03, QDWWHDHDEGOV ,CHI = 127.365 04, REXXIEIEFHPW ,CHI = 235.261 05, SFYYJFJFGIQX ,CHI = 406.337 06, TGZZKGKGHJRY ,CHI = 581.217 07, UHAALHLHIKSZ ,CHI = 141.612 08, VIBBMIMIJLTA ,CHI = 101.960 09, WJCCNJNJKMUB ,CHI = 521.511 10, XKDDOKOKLNVC ,CHI = 167.805 11, YLEEPLPLMOWD ,CHI = 40.822 12, ZMFFQMQMNPXE ,CHI = 559.389 13, ANGGRNRNOQYF ,CHI = 119.035 14, BOHHSOSOPRZG ,CHI = 136.775 15, CPIITPTPQSAH ,CHI = 129.766 16, DQJJUQUQRTBI ,CHI = 1018.478 17, ERKKVRVRSUCJ ,CHI = 140.245 18, FSLLWSWSTVDK ,CHI = 48.189 19, GTMMXTXTUWEL ,CHI = 245.771 20, HUNNYUYUVXFM ,CHI = 109.666 21, IVOOZVZVWYGN ,CHI = 533.896 22, JWPPAWAWXZHO ,CHI = 266.240 23, KXQQBXBXYAIP ,CHI = 882.771 24, LYRRCYCYZBJQ ,CHI = 305.997 25, MZSSDZDZACKR ,CHI = 1034.285 Full line text. 00, TEG.EANBII..TOA.OEEELNLNLNEU...SDHL..VHEIEAENHTLDTFAEESNAA.B.ENEEGS.YIHEDRXO.TSIER.IKEAGNSAN..O.IS..NNLTESML..IVOAB.DT.NA.FDXLNEYEUDESTIO.HE.EEG.SLV.WE.S.DAIBENFENES.SL..IEGKTRE.NULE.OHSN..VAGF..TO.H.ERLSDEIA.LEE.TSLVN.AGAASENDT....VB.REE.LO....I.E.BIET.E.V..DLSNNEN.DHMA.GVOET.E..ESAEL.HTEEHE.DEVINATOKNHE.SIOE.SRLYUNL...V.HNTEEIADENAW.S.E ,CHI = 92.592
From this at a glance i would normally conclude that there is no vigenere cipher present however due to the fact i am guessing at the Keyspace i can not prove this.
Unfortunately i can not post any more images so i will jump to a new reply.
So carrying on from the previous post. I then had a close look at Z408.
David also made mention to a statistically significant spike in the coincidence counting of Z408
I also plotted the coincidence count vs shift and found the same spike at 49 however i would have to say that there is more noise present also.
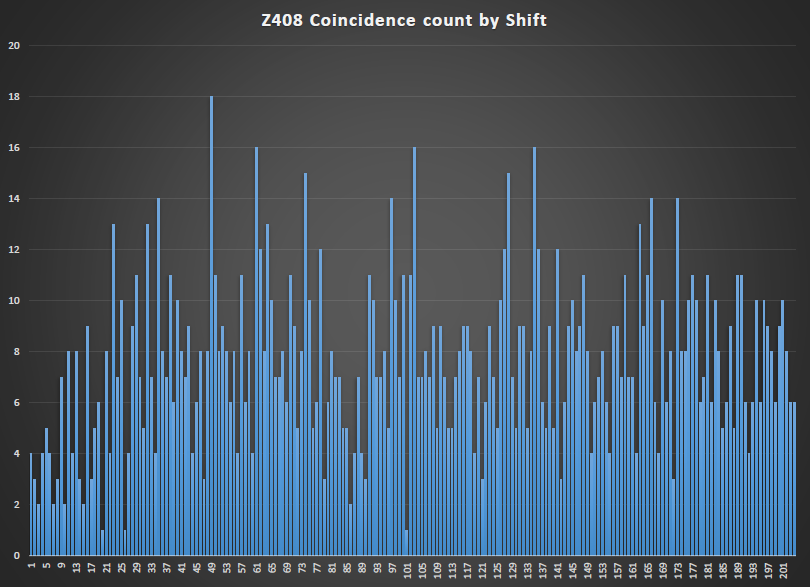
The interesting thing came when i ploted the IoC of columns vs column width.
There seem hardly any correlation with that of the Coincidence counting.
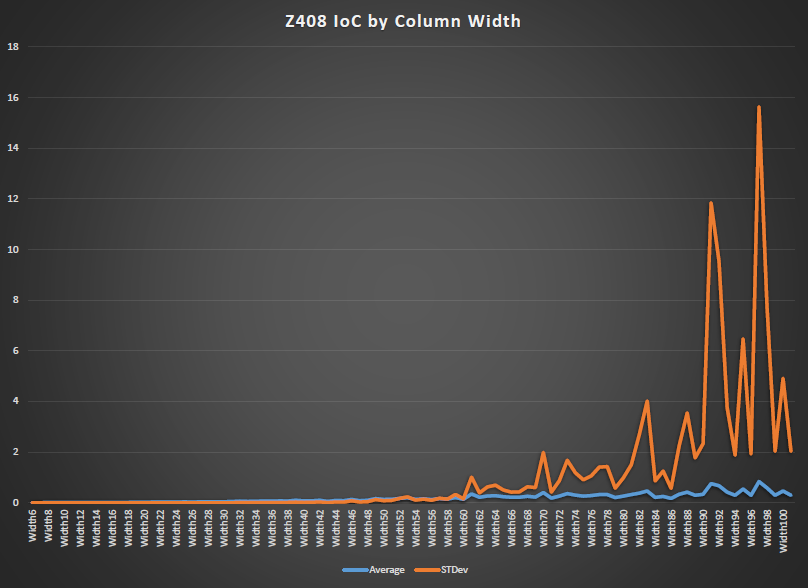
From All of this work i would have to conclude that the coincidence counting spike is an artifact of homophonic process.
What do you guys recon?
Programs and data sets can be made available on request.
Regards
Bart

Of the 35 positions involved with the period 78 unigram repeats, 19 of them are also involved with the period 39 bigram repeats. All of the above, assuming of course, that he transcribed the message from left to right, top to bottom. 89 / 340 = 26% of the message for positions covered by the bigram repeats. So you would think that roughly 26% of the period 78 unigram repeat positions would fall on period 39 bigram repeat positions. But that is not true. 54% of the period 78 unigram repeat positions fall on period 39 bigram repeat positions.
Why? Does it mean something, or does it mean nothing?
This is an interesting observation. I was wondering if the unigram repeats detected by the Kasiski examination at shift 78 are just "echoes" of the bigrams occurring at period 39. But if that were so, then why aren’t there other Kasiski peaks at multiples of other periods that have high numbers of repeated bigrams (such as periods 19, 74, 65, 5, 158, etc)?
Here’s an idea. Let X represent the shift value used for Kasiski examinations. Let Y represent the period used for counting repeated bigrams. Then let Z be the number of positions shared between the KE-detected unigram repeats at shift X and the repeating bigrams detected at period Y. In your example, X=78, Y=39, and Z=19. Goal: Find all combinations of X and Y that maximize Z. Maybe we’ll find more peaks for Z at other combinations of X and Y. I will try to work on this.
Here’s an idea. Let X represent the shift value used for Kasiski examinations. Let Y represent the period used for counting repeated bigrams. Then let Z be the number of positions shared between the KE-detected unigram repeats at shift X and the repeating bigrams detected at period Y. In your example, X=78, Y=39, and Z=19. Goal: Find all combinations of X and Y that maximize Z. Maybe we’ll find more peaks for Z at other combinations of X and Y. I will try to work on this.
Here’s a preliminary result:
https://docs.google.com/spreadsheets/d/ … sp=sharing
Note that I hastily coded the routine that produces that data, so there may be errors. I noticed that my values for shift 78 / period 39 are slightly different: I show 37 KE positions, and 20 positions in common with repeating bigrams (you said there are 35 KE positions and 19 in common). I will try to double check my work.
I sorted the results based on the proportion of Z to the total number of positions (from both KE and period untransposition). Shift of 78 is involved in many of the top results. Shift of 35 comes up a lot too.
I have no idea what any of it means, of course. ![]() But maybe I’ll run the same test on some regular homophonic substitution ciphers to see if similar peaks occur in the quantity of shared symbols.
But maybe I’ll run the same test on some regular homophonic substitution ciphers to see if similar peaks occur in the quantity of shared symbols.
UPDATED: I added a 2nd tab to the above spreadsheet for the Z408. There are some similar "high commonality" combinations of shift/period, but the percentages are a little lower.

Regarding the shuffle tests and comparing the 340 with the 408. The 340 has 63 symbols and the 408 has only 54 symbols. So it seems to me that it would be easier to have a coincidence count ( "CC" ) spike like the one that Bart found if there are fewer symbols. If you had a message with only 26 symbols, then you would get more and bigger spikes. If you had a message with 100 symbols, then you would get fewer and smaller spikes. It seems to me that the results of the shuffle tests are largely a function of the count of symbols and the distribution of symbol count. In the 340, there are symbols with count of 1, 2, 3, etc. all the way to 24. Maybe do a shuffle test with a message that has a very similar distribution of symbol count for a comparison.
And so that leads to scoring these CC repeats as well. I am just now starting to play around with finding the probability score of each pair of identical symbols with period 78. If you calculate the probability of each CC repeat by symbol count, I wonder how the distribution of these probabilities would compare with a distribution of probabilities for spike CC repeats in other messages.
Regarding the comparison of shared positions of all CC periods 1-170 with all bigram period 1-170 repeats. Thanks for the spreadsheet; that’s exactly what I was thinking of doing. I sorted by column E ( number of common positions ). I don’t know what it means either. It seems to me that if you have a spike at a certain CC period, then there will invariably be some bigram periods with a lot of common positions. But it is interesting that 26 and 39, both divisors of 78, are in the top 6 of all results.
Thanks for carrying the ball over the weekend. I am very curious and open minded about these interesting new statistics and plan on spending some time with this subject before resuming my cycle start / end position work. I wonder if these CC repeats are caused by the cipher.
EDIT: I finally came up with 18 period 78 CC repeats, with only 35 positions because there is one situation where the + symbol occurs three times in two continuous repeats.
Other thoughts on the subject of encoding conditioned upon position. Daikon found that some symbols only occur at even positions, and some symbols occur at odd positions. We explored this idea and also found that some of the symbols that occur on only odd positions also cycle together. And we looked into the possibility of multiple keys this way. However, we didn’t look at this subject in the context of different routes. We only looked at it as if Zodiac encoded left right, top bottom. See:
viewtopic.php?f=81&t=2625; and
viewtopic.php?f=81&t=2617&hilit=checkerboard&start=210 ( read into the following page )
Hi Guys I still need to catch up on everyone’s posts but while I had a moment i just wanted to post this for completeness and to clarify my last posts.
As David pointed out Z408 has a significant spike at 49 so my main question is here "Did Z408 Plain text have a strong coincidence count here or is it an artifact of the homoponic process?".
I did a Coincidence count for the 408 Plaintext and apart from seeing some presents at 49 it is not a major spike nor was it a fundamental or harmonic. (it was close though and could be argued i guess.). From this i would have to conclude that the homophonic process filter’s out other samples that its cycle rates do not resonate with. this should be mathematically provable but i don’t have time for that today.
I really want to go through everyone else posts ASAP.
Regards
Bart
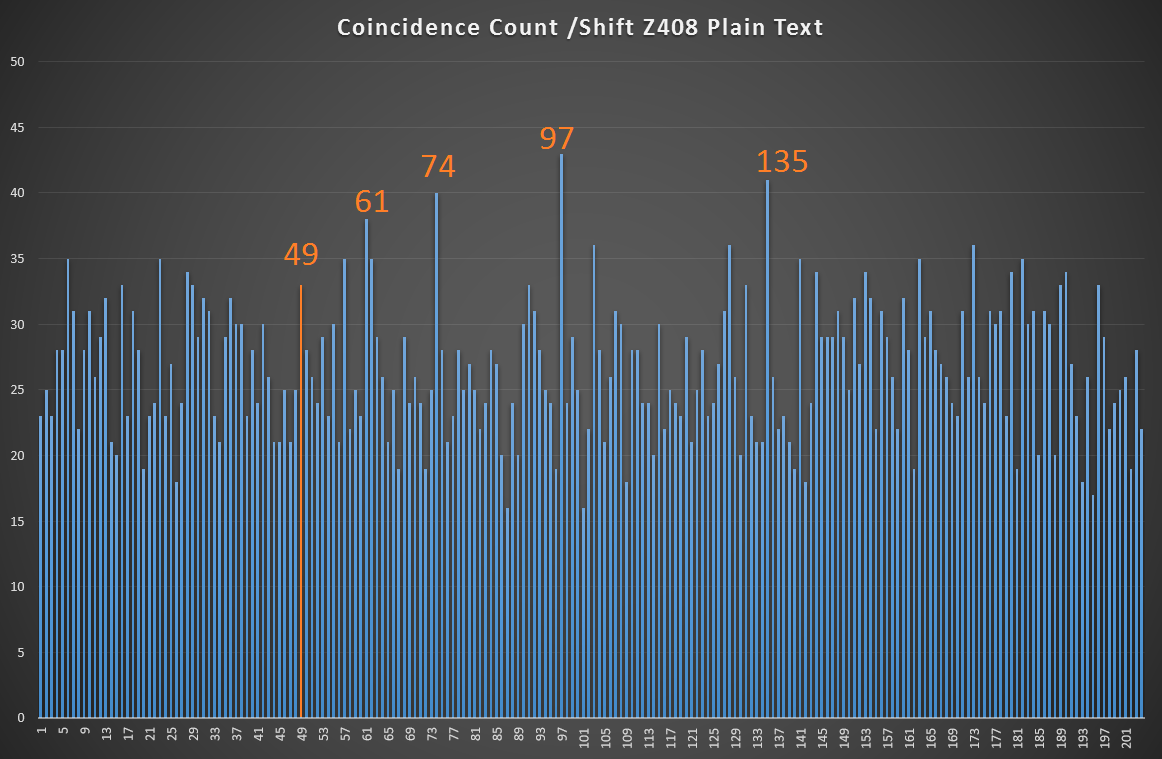
Code and outputs
http://codepad.org/f0l8yyLc
#include <stdio.h>
#include <string.h>
unsigned char input[]="ILIKEKILLINGPEOPLEBECAUSEITISSOMUCHFUNITISMOREFUNTHANKILLINGWILDGAMEINTHEFORRESTBECAUSEMANISTHEMOATDANGERTUEANAMALOFALLTOKILLSOMETHINGGIVESMETHEMOATTHRILLINGEXPERENCEITISEVENBETTERTHANGETTINGYOURROCKSOFFWITHAGIRLTHEBESTPARTOFITIATHAEWHENIDIEIWILLBEREBORNINPARADICESNDALLTHEIHAVEKILLEDWILLBECOMEMYSLAVESIWILLNOTGIVEYOUMYNAMEBECAUSEYOUWILLTRYTOSLOIDOWNORSTOPMYCOLLECTINGOFSLAVESFORMYAFTERLIFEEBEORIETEMETHHPITI";
//*********************************************************************************************************************
void main (void)
{
unsigned int index,count,length,offset;
length = strlen(input);
for (offset = 0 ; offset <= (length/2) ; offset++)
{
count = 0;
for (index = 0 ; index < (length) ; index++)
if ((input[index] == input[(index+offset)%length]))
count++;
printf("%u,%un",offset,count);
}
}
//*********************************************************************************************************************
Here are some of the less probable period 78 unigram repeats.
There are four of the D symbol, and two of them are involved.
There are four of the upside down T, and two of them are involved.
There are five of the backwards D, and two of them are involved.
There are five of the solid square, and two of them are involved.

There are five of the T, and two of them are involved.
There are six of the G, and two are involved.
There are six of the half filled circle (?), and two are involved.
There are 24 of the +, and 7 are involved.

What I have for symbol 53, the half filled circle, left half is filled. Um, that’s what everyone else has as far as I know. But they do not all look alike. It looks to me like only three of them are half filled, and three of them are solid, like the other solid circles which I have for symbol 50. This can’t possibly be the first time the question has been asked. Is it just a computer resolution issue?
What I have for symbol 53, the half filled circle, left half is filled. Um, that’s what everyone else has as far as I know. But they do not all look alike. It looks to me like only three of them are half filled, and three of them are solid, like the other solid circles which I have for symbol 50. This can’t possibly be the first time the question has been asked. Is it just a computer resolution issue?
It’s come up before – yes, it’s a resolution issue. You can see in this version that they are all half-filled:
http://zodiackillerciphers.com/wiki/ima … lution.jpg
I did some simple testing to find out if the least probable period 78 unigram repeats are statistically significant. I scored them with the following formula:
score = ln ( 1 / ( ( ( symbol count / 340 ) * ( symbol count / 340 ) ) ^ number of repeats ) )
And I rounded the scores to the nearest 0.25 so that I could tally them up and make a column chart. I shuffled the message for a while, maybe a few hundred times, before I came up with a spike that has 18 repeats. The probability score distribution for the 340 is on top, and the + symbol repeats is the value to the far right. The probability score distribution for the shuffled message is on bottom. You can see that the scores are comparable, and the value to the far right is also for the + symbol. If the 340 scores were remarkable, I would expect to see lower scores for the shuffled message. But they are about the same.
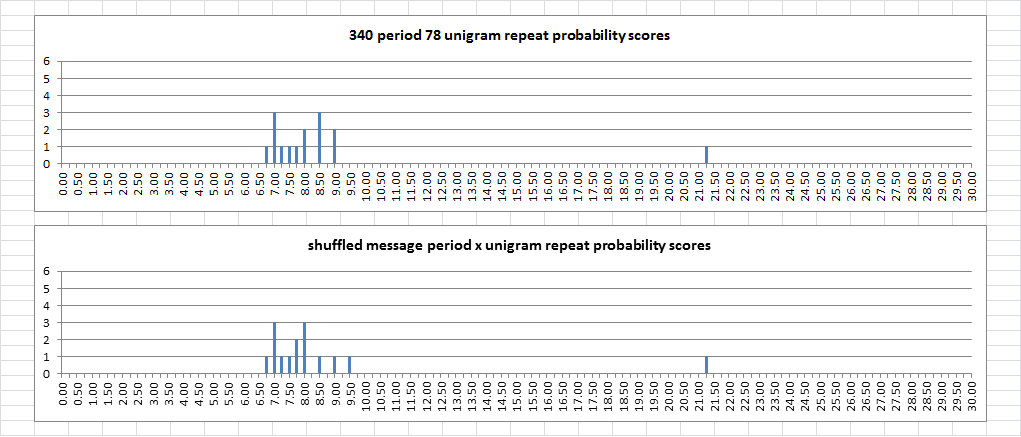
As a matter of fact, every time I shuffle the message I get a cluster of scores in the same area of the chart, regardless of the repeat count. And often times there is a value to the right, and most often it is the + symbol. Sometimes it is the B. Below is a comparison for the very next shuffle. The repeat count was only 11, but there were five repeats involving the + symbol instead of four.
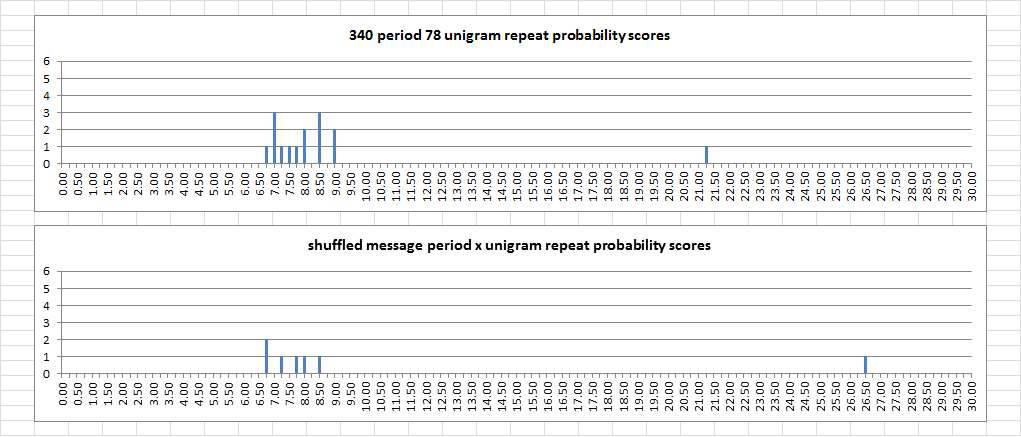
So it looks like the count of period 78 unigram repeats is much more significant than any of the the individual repeats. With the period 19 bigram repeats, both the count and the individual repeats are less probable.
I was playing around and made a heatmap, showing the involvement by position ( left ). For example, at position 1, there is only one occurrence where at ANY period where there is a repeat ( marked with blue box right ). Symbol 19, the +, scores higher because for any particular position the spreadsheet is just counting all of the period x unigram repeats with symbol 19.
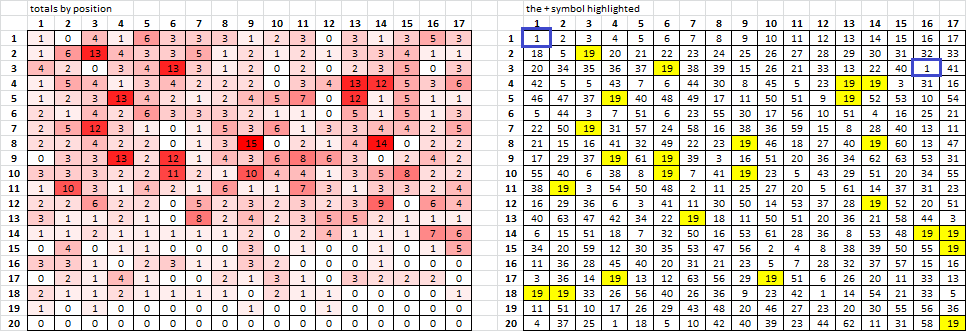
If I shuffle the message, symbol 19 always scores high.

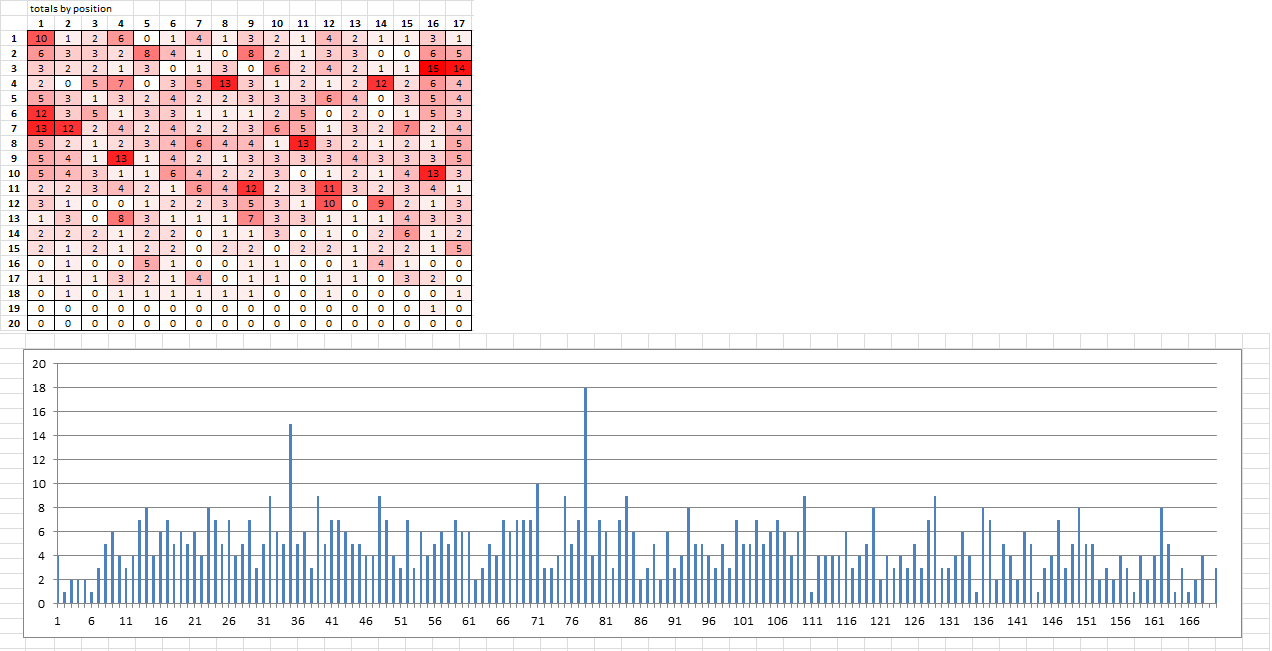
My spreadsheet slides the x position through the message for x = 1 to 170. You can see that this causes the second half of the message to score lower than the first half, because I did not "wrap" to the top of the message when sliding the x in the bottom half of the message. Is that what I am supposed to do? I flipped and mirrored the 340, using the same spreadsheet, EDIT: I found another spike at 78, but counting more of the bottom half of the message. So I am wondering should I always test the regular message, and the flipped mirrored, and add the counts together for better period detection? If the bottom half and top half are consistent, does this mean anything?
Smokie, thanks for posting your findings – I will give them a closer look soon.
Here’s a visualization of the "shift 78" Kasiski examination peak done by untransposing at period 78 and highlighting the doubles that appear:

I only counted 18 doubles there. BartW, your code counts 19, I think because it thinks there’s an extra double "+" somewhere. Is 18 the correct count or did I miss something?
Here’s the same thing with corresponding pivot positions highlighted:

Sorry for the quietness i have been tied up with work and i really need some time to understand everyone’s maths and analysis.
I only counted 18 doubles there. BartW, your code counts 19, I think because it thinks there’s an extra double "+" somewhere. Is 18 the correct count or did I miss something?
David there is a wrap over which i think you are missing (Pair 19 @, 281,19)
EDIT I start at location 0 so the the 282nd char and 20th char
note that my code doesn’t short the 19 wrap around char due to a bug/laziness ![]()
Shift = 078 ................d ................. ........G....#... ............+.R.. ............+.... p........d.....D. .......2.c....... .G....#......+... .....+.R.F.....4. .....+....p...... ....5..|D........ 2.c......T....... ......+.......... ..F.....4.....t+. ..............5.. |................ ..T......+....... ................. .......t......... ................. Pair 1 @, 16,94 Pair 2 @, 42,120 Pair 3 @, 47,125 Pair 4 @, 63,141 Pair 5 @, 65,143 Pair 6 @, 80,158 Pair 7 @, 85,163 Pair 8 @, 100,178 Pair 9 @, 109,187 Pair 10 @, 111,189 Pair 11 @, 132,210 Pair 12 @, 145,223 Pair 13 @, 151,229 Pair 14 @, 158,236 Pair 15 @, 174,252 Pair 16 @, 177,255 Pair 17 @, 196,274 Pair 18 @, 235,313 Pair 19 @, 281,19
http://codepad.org/YUzrcWgq#output
My spreadsheet slides the x position through the message for x = 1 to 170. You can see that this causes the second half of the message to score lower than the first half, because I did not "wrap" to the top of the message when sliding the x in the bottom half of the message. Is that what I am supposed to do? I flipped and mirrored the 340, using the same spreadsheet, EDIT: I found another spike at 78, but counting more of the bottom half of the message. So I am wondering should I always test the regular message, and the flipped mirrored, and add the counts together for better period detection? If the bottom half and top half are consistent, does this mean anything?
Never mind. I moved through positions 1 through 170, and made x = 1 to 170. The heatmap only shows the lowest position counts, not the highest position counts. I could make one that does both, but it doesn’t really matter. The high count symbols show up with higher period x unigram counts, no matter what you do. I don’t think that the heatmap tells us much.
There are 15 symbols involved, and I wanted to find out if there is any relationship between the period 78 unigram repeats and the cycles. So I made a little table. On the top and left are the symbols, and in the boxes the count of consecutive alternations.
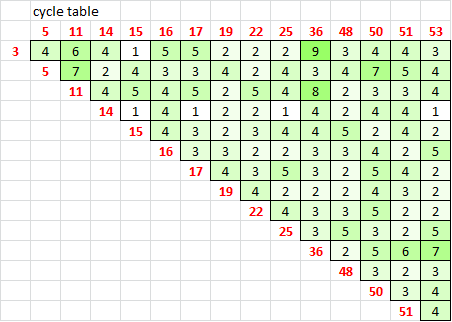
Symbols 3 and 36 have 9 consecutive alternations, and a few of the symbol positions are shared with the period 78 unigram repeats. But I don’t see anything particularly interesting here.

Doranchak, I think that Bart found this one, marked in bold outline. It is wraparound. I found it too, but I honestly don’t know if wraparound is appropriate because the number of positions would have to be a multiple of the period I think.

Hi Smokie… Silly question time…
What is your definition of a "shuffle" you and David mention it often but i am assume the following
PT is based on Random chars which are then keyed with 63 symbol homophonic randomly is this correct?
In the following
score = ln ( 1 / ( ( ( symbol count / 340 ) * ( symbol count / 340 ) ) ^ number of repeats ) )
I assume Symbol count = 63?
I know natural log etc but what is the relevance to the equation?
Natural log (squared (chance) to the power of instances)
Regards
Bart

{kind=link}