
Wow!!

We have ‘learned’ to create a fictitiously created partial string out of the cipher, as a cleartext, using e.g. frequent bigrams, trigrams, alphabet letters etc.. Let all variations of such string, here of length = 27 symbols/letters, be an array of ‘variations’.
In a first step, we cut off all variations which do not contain e.g. 3 or 4 words of length>4.
Only those remaining are used for further computation, searching for additional words but in other parts of the cipher, by adding letters, bigrams etc.. As a result, a huge Matrix occurs, involving all potential cipher parts, letters, bigrams, trigrams etc..for the rest of the cipher – which is way too much to compute.
BUT..what we can actually do is to BREAK the computation process as soon as at least one setting has been found with at least one word in each of the multiple partial cipher strings. Obvious advantage of this proess: If any potential solution does exist for our first (long) string, the rest of its sub-variations is not (yet) computed at all. This saves a lot of time.
Thus, the focus is only on the first string. But this string is shown only if – currently – a total of 9 words are found, 5 of them being found in different ‘background’ strings. If no word is found in one of the background strings, e.g. #5, the computation proceeds until either one word is found. Or, if none has been found, there is the elimination of the whole variation/array.
All successful variations, however, with at least one word in each string, are printed.
So far, this method works fine with an estimated 99.99999999% of all computable variations not to be computed at all. The results look – similar to my previous post – like this:
THERE HI TH TIMESSIEXPOSEEARTHISSHAPEAE SLTHERETHEMETEL TEISTILL EOSANTATHI LOOSESNMIERE THERE HI TH TIMESSIIMPOSEEARTHISSHAPEAE SLTHERETHEMETEL TIISTILL EOSANTATHI LOOSESNMIERE THERE HI TH TIMESSIREPOSEEARTHISSHAPEAE SLTHERETHEMETEL TRISTILL EOSANTATHI LOOSESNMIERE THERE HI TH TIMESSIOPPOSEEARTHISSHAPEAE SLTHERETHEMETEL TOISTILL EOSANTATHI LOOSESNMIERE THERE HI TH TONESSIEXPOSEEARTHISSHAPEAE SMTHERETHINETEM TEISTORM EASANTATHI ROASTSNNOERE THERE HI TH TONESSIIMPOSEEARTHISSHAPEAE SMTHERETHINETEM TIISTORM EASANTATHI ROASTSNNOERE THERE HI TH TONESSIREPOSEEARTHISSHAPEAE SMTHERETHINETEM TRISTORM EASANTATHI ROASTSNNOERE THERE HI TH TONESSIOPPOSEEARTHISSHAPEAE SMTHERETHINETEM TOISTORM EASANTATHI ROASTSNNOERE THERE HI TH STEERSIHOURSENORTHISSHOUTOE STTHERETEDENSET THIRSTCT EASHESOTHI CRASHSEETERE
Thus, let us ignore everything around the string of length 27, we find potential solutions such as "…TONES. I IMPOSE EARTH IS SHAPED E…", which is quite a nice cleartext variations (with at least the words THERE, THINE [poet.], STORM, SANTA and ROASTS being found on different places of the cipher. Please note that all letters not covered by words are still fully iterable, e.g. the D of the word SHAPED as the program has actually found SHAPE (and not SHAPED); which is part of future computation.
Please not that the specific string of length 27 contains a total of 19 different homophones, thus the theoretical amount of all variations is:
26^19 = 766,467,265,200,361,890,474,622,976 or 766.5 Septillion
out of which we are now able to select dozens of potential cleartext solutions in a few minutes only. Computation, of course, will still take it’s time. Then, all results can be analyzed in a second computation process – already having eliminated most of the 766.5 Septillion variations – for further results.
Considering a pre-setup of the + symbol as well as one 5-gram (IoFBc), each 5-gram takes a computation time of a few hours only. Thus, guessing those two pre-setup variablse correctly and one can get Z’s cleartext on the same day (assuming homophone substitution; non-statistical outlier).
So far, the method chosen currently covers ~60% of all symbols of the Z340 cipher.
The BREAK function makes it possible..hopefully.
QT
*ZODIACHRONOLOGY*

QT-
Assuming you are still trying to solve the 340 as a normal homophonic cipher – it’s not – I ran the string you named (TONESSIIMPOSEEARTHISSHAPEAE) through an old program of mine, and tried it in every possible position in the 340. It fits in seven positions, starting with 0. They are positions 5, 6, 7, 8, 11, 246, and 270. And in every one, the bulk of the cipher becomes gibberish. Here are the results:
(Position 5) HER>pl^VPkI1LTG2d = ----ETONESSIIMPOS Np+B(#O%DWY.<!Kf) = EEARTHISSHAPEAE-- By:cM+UZGW()L#zHJ = R----A--PHT-IH--- Spp7^l8!V3pO++RK2 = -EE-OT-AN-EIAA-EO _9M+ztjdI5FP+&4k/ = ---A---SS--EA--S- p8R^FlO-!dCkF>2D( = E--O-TI-AS-S--OST #5+Kq%;2UcXGV.zLI = H-AE-S-O---PNP-IS (G2Jfj#O+_NYz+@L9 = TPO---HIA-EA-A-I- d<M+b+ZR2FBcyA64K = SE-A-A--O-R-----E -zlUV+^J+Op7<FBy- = --T-NAO-AIE-E-R-- U+R/5tEIDYBpbTMKO = -A-----SSARE-M-EI 2<clRJI!5T4M.+&BF = OE-T--SA-M--PA-R- z69Sy#+NI5FBc(;8R = -----HAES--R-T--- lGFN^f524b.cV4t++ = TP-EO--O--P-N--AA yBX1!:49CE>VUZ5-+ = -R-IA------N----A Ic.3zBK(Op^.fMqG2 = S-P--RETIEOP---PO RcT+L16C<+FlWBI)L = --MAII--EA-THRS-I ++)WCzWcPOSHT/()p = AA-H--H-EI--M-T-E IFkdW<7tB_YOB!-Cc = S-SSHE--R-AIRA--- >MDHNpkSzZO8AIK;+ = --S-EES---I--SE-A (Position 6) HER>pl^VPkI1LTG2d = ----E-TONESSIIMPO Np+B(#O%DWY.<!Kf) = SEEARTHISSHAPEAE- By:cM+UZGW()L#zHJ = A----E--MSR-IT--- Spp7^l8!V3pO++RK2 = -EE-T--EO-EHEE-AP _9M+ztjdI5FP+&4k/ = ---E---OS--NE--E- p8R^FlO-!dCkF>2D( = E--T--H-EO-E--PSR #5+Kq%;2UcXGV.zLI = T-EA-I-P---MOA-IS (G2Jfj#O+_NYz+@L9 = RMP-E-THE-SH-E-I- d<M+b+ZR2FBcyA64K = OP-E-E--P-A-----A -zlUV+^J+Op7<FBy- = ----OET-EHE-P-A-- U+R/5tEIDYBpbTMKO = -E-----SSHAE-I-AH 2<clRJI!5T4M.+&BF = PP----SE-I--AE-A- z69Sy#+NI5FBc(;8R = -----TESS--A-R--- lGFN^f524b.cV4t++ = -M-STE-P--A-O--EE yBX1!:49CE>VUZ5-+ = -A-SE------O----E Ic.3zBK(Op^.fMqG2 = S-A--AARHETAE--MP RcT+L16C<+FlWBI)L = --IEIS--PE--SAS-I ++)WCzWcPOSHT/()p = EE-S--S-NH--I-R-E IFkdW<7tB_YOB!-Cc = S-EOSP--A-HHAE--- >MDHNpkSzZO8AIK;+ = --S-SEE---H--SA-E (Position 7) HER>pl^VPkI1LTG2d = ----S--TONESSIIMP Np+B(#O%DWY.<!Kf) = OSEEARTHISSHAPEAE By:cM+UZGW()L#zHJ = E----E--ISAESR--- Spp7^l8!V3pO++RK2 = -SS----PT-STEE-EM _9M+ztjdI5FP+&4k/ = ---E---PE--OE--N- p8R^FlO-!dCkF>2D( = S-----T-PP-N--MIA #5+Kq%;2UcXGV.zLI = R-EE-H-M---ITH-SE (G2Jfj#O+_NYz+@L9 = AIM-A-RTE-OS-E-S- d<M+b+ZR2FBcyA64K = PA-E-E--M-E-----E -zlUV+^J+Op7<FBy- = ----TE--ETS-A-E-- U+R/5tEIDYBpbTMKO = -E-----EISES-I-ET 2<clRJI!5T4M.+&BF = MA----EP-I--HE-E- z69Sy#+NI5FBc(;8R = -----REOE--E-A--- lGFN^f524b.cV4t++ = -I-O-A-M--H-T--EE yBX1!:49CE>VUZ5-+ = -E-SP------T----E Ic.3zBK(Op^.fMqG2 = E-H--EEATS-HA--IM RcT+L16C<+FlWBI)L = --IESS--AE--SEEES ++)WCzWcPOSHT/()p = EEES--S-OT--I-AES IFkdW<7tB_YOB!-Cc = E-NPSA--E-STEP--- >MDHNpkSzZO8AIK;+ = --I-OSN---T--EE-E (Position 8) HER>pl^VPkI1LTG2d = ----O---TONESSIIM Np+B(#O%DWY.<!Kf) = POSEEARTHISSHAPEA By:cM+UZGW()L#zHJ = E----S--IIEASA--- Spp7^l8!V3pO++RK2 = -OO----A--ORSS-PI _9M+ztjdI5FP+&4k/ = ---S---MN--TS--O- p8R^FlO-!dCkF>2D( = O-----R-AM-O--IHE #5+Kq%;2UcXGV.zLI = A-SP-T-I---I-S-SN (G2Jfj#O+_NYz+@L9 = EII-E-ARS-PS-S-S- d<M+b+ZR2FBcyA64K = MH-S-S--I-E-----P -zlUV+^J+Op7<FBy- = -----S--SRO-H-E-- U+R/5tEIDYBpbTMKO = -S-----NHSEO-S-PR 2<clRJI!5T4M.+&BF = IH----NA-S--SS-E- z69Sy#+NI5FBc(;8R = -----ASPN--E-E--- lGFN^f524b.cV4t++ = -I-P-E-I--S----SS yBX1!:49CE>VUZ5-+ = -E-EA-----------S Ic.3zBK(Op^.fMqG2 = N-S--EPERO-SE--II RcT+L16C<+FlWBI)L = --SSSE--HS--IENAS ++)WCzWcPOSHT/()p = SSAI--I-TR--S-EAO IFkdW<7tB_YOB!-Cc = N-OMIH--E-SREA--- >MDHNpkSzZO8AIK;+ = --H-POO---R--NP-S (Position 11) HER>pl^VPkI1LTG2d = ----I------TONESS Np+B(#O%DWY.<!Kf) = IIMPOSEEARTHISSHA By:cM+UZGW()L#zHJ = PEAE-M--EROAOS--- Spp7^l8!V3pO++RK2 = -II----S--IEMM-SS _9M+ztjdI5FP+&4k/ = ---M---S----M---- p8R^FlO-!dCkF>2D( = I-----E-SS----SAO #5+Kq%;2UcXGV.zLI = S-MS-E-S-E-E-H-O- (G2Jfj#O+_NYz+@L9 = OES-H-SEM-IT-M-O- d<M+b+ZR2FBcyA64K = SI-M-M--S-PEE---S -zlUV+^J+Op7<FBy- = -----M--MEI-I-PE- U+R/5tEIDYBpbTMKO = -M------ATPI-N-SE 2<clRJI!5T4M.+&BF = SIE----S-N--HM-P- z69Sy#+NI5FBc(;8R = ----ESMI---PEO--- lGFN^f524b.cV4t++ = -E-I-H-S--HE---MM yBX1!:49CE>VUZ5-+ = EP-TSA----------M Ic.3zBK(Op^.fMqG2 = -EH--PSOEI-HH--ES RcT+L16C<+FlWBI)L = -ENMOT--IM--RP-AO ++)WCzWcPOSHT/()p = MMAR--RE-E--N-OAI IFkdW<7tB_YOB!-Cc = ---SRI--P-TEPS--E >MDHNpkSzZO8AIK;+ = --A-II----E---S-M (Position 246) HER>pl^VPkI1LTG2d = -OENI-SE--P---EA- Np+B(#O%DWY.<!Kf) = -IMAT-H----S--RH- By:cM+UZGW()L#zHJ = A--OAMSSE-T---E-- Spp7^l8!V3pO++RK2 = -II-S---EEIHMMERA _9M+ztjdI5FP+&4k/ = --AME---PI--M---- p8R^FlO-!dCkF>2D( = I-ES--HI--T--NA-T #5+Kq%;2UcXGV.zLI = -IMRP--ASO-EESE-P (G2Jfj#O+_NYz+@L9 = TEA-H--HM---EM--- d<M+b+ZR2FBcyA64K = --AM-MSEA-AO----R -zlUV+^J+Op7<FBy- = IE-SEMS-MHI---A-I U+R/5tEIDYBpbTMKO = SME-I-OP--AI--ARH 2<clRJI!5T4M.+&BF = A-O-E-P-I--ASM-A- z69Sy#+NI5FBc(;8R = E-----M-PI-AOT--E lGFN^f524b.cV4t++ = -E--SHIA--SOE--MM yBX1!:49CE>VUZ5-+ = -A------TONESSIIM Ic.3zBK(Op^.fMqG2 = POSEEARTHISSHAPEA RcT+L16C<+FlWBI)L = EO-M---T-M---AP-- ++)WCzWcPOSHT/()p = MM--TE-O-H----T-I IFkdW<7tB_YOB!-Cc = P-------A--HA-ITO >MDHNpkSzZO8AIK;+ = NA---I--ESH--PR-M (Position 270) HER>pl^VPkI1LTG2d = --N--E----TIISTO- Np+B(#O%DWY.<!Kf) = --SR-----A--O---H By:cM+UZGW()L#zHJ = R--E-S--TA-HI-E-- Spp7^l8!V3pO++RK2 = -----E------SSN-O _9M+ztjdI5FP+&4k/ = ---SE---T-E-S---- p8R^FlO-!dCkF>2D( = --N-EE----P-E-O-- #5+Kq%;2UcXGV.zLI = --S----O-E-T--EIT (G2Jfj#O+_NYz+@L9 = -TO-----S---ES-I- d<M+b+ZR2FBcyA64K = -O-S-S-NOERE--M-- -zlUV+^J+Op7<FBy- = -EE--S--S---OER-- U+R/5tEIDYBpbTMKO = -SN----T--R--S--- 2<clRJI!5T4M.+&BF = OOEEN-T--S---S-RE z69Sy#+NI5FBc(;8R = EM----S-T-ERE---N lGFN^f524b.cV4t++ = ETE----O---E---SS yBX1!:49CE>VUZ5-+ = -R-I----P-------S Ic.3zBK(Op^.fMqG2 = TE--ER---------TO RcT+L16C<+FlWBI)L = NESSIIMPOSEEARTHI ++)WCzWcPOSHT/()p = SSHAPEAE----S--H- IFkdW<7tB_YOB!-Cc = TE--AO--R---R--PE >MDHNpkSzZO8AIK;+ = --------E----T--S
Unless I am missing something, there is NO WAY to make readable text around that in any placement. It’s easy to fit strings in parts of the cipher, but one has to look at the entire thing, right? I just do not see how this is progress.
-glurk
——————————–
I don’t believe in monsters.
hi all
I’m really new to the site and relatively new to the zodiac, but here goes.
I’m a 51 year old postman that works between 60 – 70 hrs p/w. Everything about my life is routine in that I wake at 5am, leave the house returning at 7:30pm most days. The little time I do have is recovering from fatigue.
In Oct 2018 I believe my life took an interesting turn in that I came across an old case accidently during a weeks holiday. The case involves a child that was murdered but the body has never been discovered…I believe I know where that body is within 22mtrs of its original burial and whilst this is not for this forum I’m hoping members who are willing will help me highlight my case by deciphering the 340.
I know it sounds crazy but keep reading before you make your mind up as maybe I found something I didn’t know I had before.
The Zodiac graduated from Lompoc High School in 1959. I know this because I deciphered the ‘My Name Is’…The code is "My Name Is + the symbols".
Q. How do I know he graduated Lompoc High School in 1959?
A. I simply looked into the Zodiac 340 because my thinking was if I could decipher the code it would highlight my case….so his name came up with a single hit in the areas of the murders at that was Lompoc High School.
I believe this individual was studying (academic or personal) religion in cultures based on the many references to different cultures and his constant ref of slaves and
I have no doubt the Zodiac was influenced by the works of Hector Hyppolite (a Haitian painter) I can see Hector’s work in the Triple-eyed Magician being used in the Zodiac’s Halloween skeleton Boo card.
Having said that, it does not mean anything unless the 340 code is cracked so I have started it and looking for anyone that is also interested in attempting to decipher it as I believe a coallition will quickly resolve this.
The Zodiac 340 resets itself 3 times.
Startpoint1: 2nd line
Startpoint2: 10th Line
Startpoint3: 17th line
You will notice on the 2nd line 4th character is B…This is a startpoint with B being repeated as the 1st character on the next line
Startpoint2 and 3 follow the same rules with + being startpoint3 (think of everything as letters)
From the 10th line down and 8th character in the line reads ‘Reborn in paradice slaves i call’
From the 12th line down and 12th line in the line reads ‘I never stop preaching’
His key word that broke the above two lines is ‘BECUASE’
He liked to use this word so thats where I started….BECUASE is located 8th line down 8th character in.
If people are interested, let me know and I will show you how he does it….I have to return to work in a couple of days so my time will be limited, thats why I’m reaching out to you guys.
Thanks for your time.
Glurk, what you have mentioned is absolutely correct (however, I still believe it to be a homophone substitution).
ELIMINATION of non-usable variations takes place: E.g. by the way that the cleartext string you mentioned only fits on seven but all possible positions of the cipher: A 27-letter string in a 340 cipher, potentially 313 positions to place such a string – but only 7 positions are ‘possible’. This equals an overall elimination rate of 97.76% (for this specific string)..
The settings currently allow approximately 1,000 results for a pre-selected setup of one 5-gram and two 2-grams. Regardless, still handling an enormous amount of variations that are actually gibberish or not even covered by the current setup. With only one solution to be the correct one.
Goal is to JUMP from one partial solution result to another, until there is one partial solution found that allows a solution over the complete cipher.
With ZDK as an example:
The program starts, runs, finds a partial solution, e.g. with 9 words of length >4. But the partial solution is gibberish. You press F5 (or F9?), to shuffle the whole cipher and it computes again, finding another ‘fake’ partial result or ‘hill’. And so on…
The difference of FCCP is the following: Instead of computing all variations, FCCP is already satisfied with one partial solution (word), only then is it that the computation process continues found. Indeed, there could be Billions of partial ‘fake’ results out there.
If no word is found, subvariations, different words etc. are not computed any more. If one word is found, FCCP checks on the next string. If no word is found, computation is interrupted (for this section). Jump, jump, jump…word yes – computation, word no – interruption.
Imagine a Satellite in space, high above our planet. A goal could be to find the highest mountain on earth, Mount Everest: Searching the surface square-foot per square-foot, if done by humans, would take a very long time. But if you scan for regions on earth with an average height of at least 10,000 ft. (mountain areas), this would somehow improve your searching process. In cryptanalysis such effect can be achieved by simultaneously entering cipher structures into the computation process, e.g. the IoFBc section (consists of two repeating trigrams..).
It then is definitely easier to ‘jump’ from one region to another, measuring its mountain’s heights, hopefully finding the highest one as a final result. All regions covered by sea or below 10,000 ft. are not even considered (method fails if Mountain is statistical outlier).
By doing so, one safes the time to scan 99.99999% of the whole surface (or all variations of the cipher). Mount Everest could be n#1 or the last one to be found, but it should – sooner or later – show up on the list. All areas below 10,000 ft., e.g. all seas or forests, not being analyzed/computed at all.
QT
*ZODIACHRONOLOGY*

I still believe it to be a homophone substitution.
Why?
First of all, it is very similar to the 408.
Second, most of the other encryption methods ‘look’ differently, eg. figures only etc..Z340 has more than 26 symbols..
Third, the ratio of homophones to alphabetical letters is similar, even if the cipher is ‘harder’.
Fourth, run some tests with cryptool, early version, compliant with homophone substitution.
Sixth, hard to crack – so why using another method, after all?
The truth is, beyond that, I dont know..
QT
*ZODIACHRONOLOGY*
Slightly modified settings..less trigrams, as a test run. Also, added the trigrams used so we can now follow somehow the computation progress. As you can see, all is computed with S, THERE as well as (still) HI, TH bigrams. Except ‘S’, the latter values are supposed to change automatically during the computation process, of course.
According to a (here smaller) trigram frequency list, we can now rule out the existence of any solution (11 words of length >4 on specific strings) for the following trigrams (column four) as a presetting:
AND, ING, ION, TIO, ENT, ATI, FOR, HER, TER, HAT, THA, ATE, HIS, CON, RES, VER, ALL, ONS, NCE, MEN, ITH
So far, this computation covers 1,400,000,000,000,000 different variations with ~4,500 words being checked on each (!) possible position of the strings chosen. After approximately 20 minutes, the following 21 cleartext groups (computation even interrupts a group after having found at least one solution) were ‘identified’:
Easy to see that there is still a lot to compute, nevertheless the cracking strength is quite high with approximately 66,800,000,000,000 : 1
A needle in a haystack..
QT
*ZODIACHRONOLOGY*

Hey Quicktrader,
Take one of your strings without spaces:
THEREHITHTEDENSLOSNCLTEDENSINCLOSEEARTHISSHALLAESTTHERETRADETETTNINTENTEISANTATHINOISESNDEEREENIECEOEEDSTEERLRETCCSSDEEDSISL
And put it into http://www.shannonentropy.netmark.pl/calculate to calculate its entropy which turns out to be 3.33097.
3.33097 is to low for a string of 124 English letters in mostly any case. For example a random selection of 124 English letters from a larger text (or just the first 124 letters from a text) will have an entropy of about 4.
Thus, I would advise filtering your clear text groups based on entropy (information content). And only include results which have a more normal entropy.
Just trying to help.
![]()
Thanks, I understand what you say..two thoughts: First of all it is not one string but multiple areas from the cipher, with gaps between the strings, too. Thus, the strings are not without spaces (although possibly relevant if you look into entropy). Secondly, I could select the results according to entropy but actually want to compute (and get) them first. Involving entropy, at the moment, is future music to me ![]()
QT
*ZODIACHRONOLOGY*
Cipher solving is like mud racing: You get stuck. Let’s have a short review on what we did so far and what to do from now on:
1. Pre-setting of variables (e.g. FBc = frequent trigram, as it occurs twice)
2. Completion of a string (FCCP) with alphabetical letters, bigrams etc.
3. Using Aho-Corasick algorithm to search for word(s) from dictionary in that string
4. If word is found: Continue with the next string, search for words there
5. Continue with string 3, 4, 5..12
6. Break computation (one solution found >> Pre-Setting is worth a ‘closer look’..’Break’ helps us to cut the computation effort short).
Running the prog has indeed quickly delivered some results (positive pre-settings), but sooner or later the program got stuck (computing endless variations until the end of time or development of quantum computing..).
Positive pre-settings, however, tell us that if the + symbol is e.g. ‘S’ and at the same time the IoFBc section is ‘THERE’, that some other homophones must be this and that letters or bigrams (otherwise no words would be found in all strings #1-12). So far, this program ran approximately 2-3 weeks – until I killed it.
Something new had to come and is it, imo, worth to write about it:
a.) Method above ‘works’, however finds too many results if only one or two strings are ‘checked’ (‘potential cleartext dimension too large’).
b.) Method above ‘gets stuck’ if too many variables flow into the prog model (‘search procedure too specific’; e.g. computation time too high to search for 12 positive strings).
c.) Conclusion: Computation intensity (time effort) can be ‘adjusted’ by the amount of strings being created/searched/cross-checked.
So what happens from now on: The program assumes some variables plus always considers the structures given by the cipher text. It creates/completes the first string, then searches for a word. Only if it finds one, the program continues computation (with this specific pre-setting). Finally, the program checks for a second, third, fourth, fifth and sixth string.
It therefore searches for pre-settings only, that allow at least one partial solution delivering a minimum of six different words (of length >4) on six different locations of the cipher.
All other pre-settings, which do not deliver at least one such result, are eliminated automatically for future computation.
Assuming Z had used only 200 different trigrams (it’s a test run..), due to the use of ‘Break’ function, the program is now able to cover 8,320,000,000,000 variations in less than 5 minutes. Out of this amount, approximately 10-30 positive pre-settings (finding at least six words) are returned. Quite a nice cracking ratio, considering the theoretical 26^63 variations of the cipher. Only positive pre-settings will be used for future computation. All other pre-setting variations are not considered anymore, to check for words in strings #7-12.
Line 6 shows the first result found, thus this pre-setting is worth further computation while for the pre-setting "THERE HI E VER" no further computation should be done
Assuming Z having used the 1,000 most frequent trigrams gives us 26,000,000,000,000,000 variations…slowing down the computation process, of course.
QT

*ZODIACHRONOLOGY*
Another update…
The program was modified…it was useless to search for multiple words, more than in the first string, as computation took – again – way too long. By focussing on the first combination of two strings, a string of totally 27 letters (!), it is still computable. The previous at least to the degree that all (!) main cipher structures, e.g. trigrams, are considered, repeating bigrams are no statistical outliers etc.
Here come’s the good news: After approximately 4-5 hours, about one third of one 5-gram for the + symbol being ‘S’, was computed. As a result, we can e.g. now say the following:
If  represents the cleartext letter ‘S‘ and
represents the cleartext letter ‘S‘ and 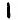

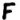
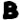
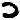 represents the n-gram ‘THERE‘, there is NO solution for
represents the n-gram ‘THERE‘, there is NO solution for 
 > representing the bigram ‘AS‘. There is, however, at least one solution for a computed pre-setting for > representing the bigram ‘PO‘. Only the latter setting should be good for further analysis (three words found e.g. ‘tints’, ‘exert’, ‘spent’).
> representing the bigram ‘AS‘. There is, however, at least one solution for a computed pre-setting for > representing the bigram ‘PO‘. Only the latter setting should be good for further analysis (three words found e.g. ‘tints’, ‘exert’, ‘spent’).
One 5-gram covers approximately 1,270,880,000,000 different variations, mostly consisting of trigrams, for the presetting AND has to check approximately 4,500 words on each position, thus about 91,125,000,000 (4,500^3) words tried out on each position in different combinations etc…..for EACH presetting variation. It is only the cipher structure itself (e.g. double letter etc.) that reduces this amount to a computable level, after all.
So far, approximately one third of the first (‘THERE’) is computed. Out of ~400,000,000,000 variations of such presettings, approximately 5,000 variations delivered at least one result consisting of at least three words of length >4 found in the 27 letter string (non-overlapping).
Now the smart part: The results we currently get are, at the same time, statistically seen the most likely ones (e.g. 5-gram ‘THERE’ instead of ‘XJWYQ’). Z, we are getting closer.
QT

*ZODIACHRONOLOGY*
Update:
For the + symbol representing the letter ‘S’, with IoFBc representing ‘THERE’ simultaneously, there do exist approx. 24,720 potential solutions containing three words of length >4 in the following string:
As you can see, only the + symbol and IoFBc section have been chosen in advance. Bernoulli analysis has shown the + symbol most likely (>95% chance )to represent the letter ‘S’ or ‘L’. Regarding IoFBc, how can we guess a 5-gram? With potentially 26^5 or 11,881,376 different 5-grams existing? On the one hand, this actually shows the complexity of the cipher. On the other hand, the IoFBc consists of two repeating (!) trigrams – IoF and FBc. Both occur on different places of the cipher, so it might (..) be assumed that they are frequent ones but accidentially occur based on identical homophones (e.g. THE to be expected 6-8 times in a text of length 340). Therefore, IoFBc would only consist of two of such frequent trigrams, e.g. ‘THERE’, ‘ENTHE’ and not e.g. ‘QJUXC’.
The fun part now is that the combination of S and THERE has already been computed: 24,720 potential results – the statistically most likely ones, btw – from now on usable for further processing. 24,720 combinations instead of approximately 1.27 Trillion to have a closer look into. Each potential solution covers 151 of 340 symbols, thus 44.4% of the cipher, including a string of 26 letters containing at least three words.
And we can proceed: Currently the combination of S and ENTHE is computed, with a similar amount of potential results to be expected. Then we may compute L and THERE or L and ENTER, just like we wish to. And so on.
Of course this method has its price:
– if IoFBc is a non-frequent 5-gram, it will take years to compute until Z’s solution is found
– computation is based on the assumption that repeating bigrams are frequent (most frequent 82 bigrams are currently in use), thus it is expected that a repeating bigram is amongst the ~12% most frequent ones
– same with trigrams..currently computation runs with the most frequent 1,000 trigrams (out of 17,576..) or ~6%. If only one repeating trigram is not amongst those 6%, computation process fails. This one is not easy to increase as the repeating trigrams are sort of ‘multiplicating’ the computation effort, thus a way stronger computer would be needed to e.g. cover the 25% most frequent trigrams.
– other reasons why computation could fail: + symbol a non-frequent letter; dictionary does not contain word; string does not contain three words of length >4 etc. etc..
Searching the haystack..
QT

*ZODIACHRONOLOGY*
Short update:
Considering the 27 letter string starting on position 271 out of 340. This string contains 18 different homophones, each potentially representing any letter from A to Z. This simple assumption leads us to
26^18 or
29,479,510,200,013,918,864,408,576
different variations of how letters from A to Z could be arranged on that specific string (part of the cipher).
Considering homophones present in different trigrams, frequent trigrams, cipher structures, double letters, etc., for each 5-gram as well as each plus symbol we can now compute this tremendous amount of variations and get a list of only ~30,000 combinations that might be further analyzed. Such ‘cracking ratio’, approximately one Sextillion to one, means that out of one Sextillion the one most likely combination is found (needle in a haystack..).
Although still scratching on the surface, e.g. by only considering the 5-10% most likely trigrams, bigrams etc., this seems to be quite an efficient ‘first approach’ to find a 27 letter cleartext. Each solution found contains at least three words of length >4.
In a second computational step, the ~30,000 results can be checked if they are consistent with finding up to twelve words on different positions all over the cipher (moreless without adding plenty of additional symbols). Only one solution should be able to deliver such a result. One wrongful assumption and the whole method fails. Computation of one plus symbol and 5-gram combination takes approximately one week.
Oh, and one more thing: The list is complete. This means that IF Z had used at least three words of length >4 from the English dictionary in use (~4,500 word roots) with the same 5-10% most frequent trigrams, bigrams, his cleartext is amongst the results.
QT
*ZODIACHRONOLOGY*
Python is wonderful. Not using the Intel distribution of Python any more (as it crashed during the two week computation process – not stable).
Now, to not compute a list of the most frequent 1,000 trigrams, some groups of trigrams have been created such as:
S_Cklpl_A = ['ASS', 'ANS', 'ALS', 'AUS', 'ARS', 'AYS'] S_Cklpl_B = ['BAS'] S_Cklpl_C = ['CES', 'CAS', 'CTS', 'CUS', 'CIS'] S_Cklpl_D = ['DIS', 'DES'] S_Cklpl_E = ['ERS', 'ESS', 'EAS', 'ENS', 'EMS', 'ELS'] ...
If from a different trigram, e.g. WCZ the letter C is already defined, only the related list as shown above is used. That saves a lot of computation time. In connection to that, some second improvement: instead of
If C = A do this and that If C = B do this and that If C = C do this and that ..
the program has now been written more beautifully like
Do this and that if C = A else this and that if C = B else this and that if C = C...
Pleasant side-effect?
The Python program actually runs approximately 10x faster.
What took about two weeks can now be computed in approximately 1-2 days only. This, on the long run, enlarges our possibilities to compute with e.g. not only the most 5-10% but 20-30% frequent trigrams. Or to cover more 5-grams for IoFBc. Over months, the program is imo now ready to crack the 340 (well, we will see..). There is no or at least not many additional cipher structures left over to be considered in the specific string.
Computation of 29,479,510,200,013,918,864,408,576 variations, by considering cipher structures, word patterns etc., has now been reduced to approximately 23,829,000,000 variations by considering the cipher structures; depending on which letters occur in each trigram etc.
Actually the next step is to simply choose the + symbol as well as the IoFBc 5-gram, e.g.:
ENTHE S
ENTER S
THERE S
ENTHE L
ENTER L
THERE L
etc. and compute it. Each computation takes about 1-2 days.
Based on that, we get the correct presettings for each IoFBc & + combination, already covering the complete 26-letter string. With these presettings given it should be easy to find all word combinations for each presetting. Additional words will be searched in various areas of the cipher (outside of the 26-letter string).
Estimated time of the 340 cipher to be solved: It could be possible in about two to four weeks. But if I had to talk to my boss, I’d say maybe the end of next year. ![]() As long as it is not a statistical outlier or different encryption method, of course.
As long as it is not a statistical outlier or different encryption method, of course.
QT
*ZODIACHRONOLOGY*
