
BTW, I have replaced the 407kb language dictionary file with a 8,000kb file..however I still got the feeling that its quality is not only bad but also not sufficient enough…anybody an idea if there is a good dictionary file somewhere? Thx, QT
You could replace the dictionary file with the entire Oxford English Dictionary. It wouldn’t matter. ZKDecrypto only uses that file to display words that are found in the solution.
The dictionary file is not used in the solving process at all.
-glurk
——————————–
I don’t believe in monsters.

BTW, I have replaced the 407kb language dictionary file with a 8,000kb file..however I still got the feeling that its quality is not only bad but also not sufficient enough…anybody an idea if there is a good dictionary file somewhere? Thx, QT
You could replace the dictionary file with the entire Oxford English Dictionary. It wouldn’t matter. ZKDecrypto only uses that file to display words that are found in the solution.
The dictionary file is not used in the solving process at all.-glurk
Alright..thanks for the hint..
Do you still know the configuration of how to solve the 408, with the v1.2?
QT
*ZODIACHRONOLOGY*
QT-
I’m not sure what you mean. I can run ZKD 1.2 just "out of the box," all default settings, and it will solve the 408 in about two seconds. Do you mean getting it to solve it absolutely 100% correct?
It probably won’t do that. But it gets it 95-99% in seconds without any settings changes at all, at least for me.
-glurk
——————————–
I don’t believe in monsters.
Well, mine does not…possibly because I had changed those algorithm parameters I had mentioned before..if you change those, they remain as they have been changed. So now I have not idea what the original settings had been..plzhlp.
– Failures until random restart
– Number of random swaps per iteration
– Lower score intolerance
Thanks,
QT
*ZODIACHRONOLOGY*
ZKD creates a file named "ZODIAC.INI" that saves the previous settings. Just delete that file and run the program again, it will go back to defaults.
-glurk
EDIT: I guess we should have put in a "return to default settings" button, but no one thought of it. Sorry. ![]()
——————————–
I don’t believe in monsters.
So here comes the hard part…I still end up with a value of ~32,000 when entering all above as eg. exclusions in the ZDK 1.2…no solution yet ![]()
QT
*ZODIACHRONOLOGY*
Trigraphs…
The 340 has two repeating trigraphs…the ‘IOF’ and the ‘FBc’. Luckily those two trigraphs ‘meet’ each other in line no. 13 leading to a ‘IOFBc’ formation.
Approximately 5-20 of such trigraphs are the most frequent, whilst about 98 different trigraphs are the most common in American language. Those 98 trigraphs are:
AIN ALL AME AND ANT ARE ART ATE ATI AVE BLE BUT COM CON CTI DER DID EAR ECT END ENT ERE ERS ESS EST EVE FOR FRO GHT HAN HAT HAV HEN HER HIN HIS HOU DIE IGH ILL IND INE ING INT ION IST ITH IVE LIN MAN MEN MON NCE NDE NOT NTE NTI OME ONE ONS ORE ORT OTH OUL OUN OUR OUT OVE PER PRO REA RED RES RIN ROM STA STE STI STR TED TEN TER THA THE THI THO TIN TIO TUR TOR ULD UND USE VER WAS WHI WIT YOU
Before I will list a full combination of – all – those trigraphs to each other, I should mention that the ‘IOFBc’ formation of line 13 may very well be seen in context with the ‘+’ symbol as one of the ‘+’ symbols is very close to the formation (‘+_IOFBc’). Using the correct combination of ‘+’ (which presumably is either S, L, T or E) with one of the following ‘IOFBc’ formations in fact leads to a total of 73 symbols or 21.5% of the whole 340 cipher..
The overall amount of trigraph combinations is 837, while the ‘+’ symbol may represent a maximum of 1-5 different letters (depending on what someone thinks ‘+’ could represent). Assuming ‘+’ to be either S, L, T or E therefore leads to 837×4=3,348 different cipher sheets to start with, all containing already a total of 21.5% as a cleartext..
Believing in ‘+’ being ‘S’ makes it even easier…with ‘only’ 837 different possibilities, those may even be entered manually to hopefully decode the rest of the cipher text. An example is e.g.
S + EAR + RED >>> S_EARED >>> SMEARED
Here you go with the complete trigraph combination list:
‘IOFBc’
AMEAR
AMECT
AMEND
AMENT
AMERE
AMERS
AMESS
AMEST
AMEVE
AINCE
AINDE
AINOT
AINTE
AINTI
ALLIN
ANDER
ANTED
ANTEN
ANTER
ANTHA
ANTHE
ANTHI
ANTHO
ANTIN
ANTIO
ANTUR
ANTOR
AREAR
ARECT
AREND
ARENT
ARERE
ARERS
ARESS
AREST
AREVE
ARTED
ARTEN
ARTER
ARTHA
ARTHE
ARTHI
ARTHO
ARTIN
ARTIO
ARTUR
ARTOR
ATEAR
ATECT
ATEND
ATENT
ATERE
ATERS
ATESS
ATEST
ATIGH
ATILL
ATIND
ATINE
ATING
ATINT
ATION
ATIST
ATITH
ATIVE
AVEAR
AVECT
AVEND
AVENT
AVERE
AVERS
AVESS
AVEST
AVEVE
BLEAR
BLECT
BLEND
BLENT
BLERE
BLERS
BLESS
BLEST
BLEVE
BUTED
BUTEN
BUTER
BUTHA
BUTHE
BUTHI
BUTHO
BUTIN
BUTIO
BUTUR
BUTOR
COMAN
COMEN
COMON
CONCE
CONDE
CONOT
CONTE
CONTI
CTIGH
CTILL
CTIND
CTINE
CTING
CTINT
CTION
CTIST
CTITH
CTIVE
DEREA
DERED
DERES
DERIN
DEROM
DIDID
DIDER
EAREA
EARED
EARES
EARIN
EAROM
ECTED
ECTEN
ECTER
ECTHA
ECTHE
ECTHI
ECTHO
ECTIN
ECTIO
ECTUR
ECTOR
ENDER
ENDID
ENTED
ENTEN
ENTER
ENTHA
ENTHE
ENTHI
ENTHO
ENTIN
ENTIO
ENTUR
ENTOR
EREAR
ERECT
EREND
ERENT
ERERE
ERERS
ERESS
EREST
EREVE
EREAR
ERECT
EREND
ERENT
ERERE
ERERS
ERESS
EREST
EREVE
ERSTA
ERSTE
ERSTI
ERSTR
ESSTA
ESSTE
ESSTI
ESSTR
ESTED
ESTEN
ESTER
ESTHA
ESTHE
ESTHI
ESTHO
ESTIN
ESTIO
ESTUR
ESTOR
ESDER
ESDID
ESTED
ESTEN
ESTER
ESTHA
ESTHE
ESTHI
ESTHO
ESTIN
ESTIO
ESTUR
ESTOR
EVEAR
EVECT
EVEND
EVENT
EVERE
EVERS
EVESS
EVEST
EVEVE
EVEAR
EVECT
EVEND
EVENT
EVERE
EVERS
EVESS
EVEST
FOREA
FORED
FORES
FORIN
FOROM
FROME
FRONE
FRONS
FRORE
FRORT
FROTH
FROUL
FROUN
FROUR
FROUT
FROVE
GHTED
GHTEN
GHTER
GHTHA
GHTHE
GHTHI
GHTHO
GHTIN
GHTIO
GHTUR
GHTOR
HANCE
HANDE
HANOT
HANTE
HANTI
HATED
HATEN
HATER
HATHA
HATHE
HATHI
HATHO
HATIN
HATIO
HATUR
HATOR
HAVER
HENCE
HENDE
HENOT
HENTE
HENTI
HEREA
HERED
HERES
HERIN
HEROM
HINCE
HINDE
HINOT
HINTE
HINTI
HISTA
HISTE
HISTI
HISTR
HISTA
HISTE
HISTI
HISTR
HOULD
HOUND
HOUSE
DIEAR
DIECT
DIEND
DIENT
DIERE
DIERS
DIESS
DIEST
DIEVE
DIEAR
DIECT
DIEND
DIENT
DIERE
DIERS
DIESS
DIEST
IGHAN
IGHAT
IGHAV
IGHEN
IGHER
IGHIN
IGHIS
IGHOU
ILLIN
INDER
INDID
INEAR
INECT
INEND
INENT
INERE
INERS
INESS
INEST
INEVE
INEAR
INECT
INEND
INENT
INERE
INERS
INESS
INEST
INGHT
INTED
INTEN
INTER
INTHA
INTHE
INTHI
INTHO
INTIN
INTIO
INTUR
INTOR
IONCE
IONDE
IONOT
IONTE
IONTI
ISTED
ISTEN
ISTER
ISTHA
ISTHE
ISTHI
ISTHO
ISTIN
ISTIO
ISTUR
ISTOR
ITHAN
ITHAT
ITHAV
ITHEN
ITHER
ITHIN
ITHIS
ITHOU
IVEAR
IVECT
IVEND
IVENT
IVERE
IVERS
IVESS
IVEST
IVEVE
IVEAR
IVECT
IVEND
IVENT
IVERE
IVERS
IVESS
IVEST
LINCE
LINDE
LINOT
LINTE
LINTI
LINCE
LINDE
LINOT
LINTE
MENCE
MENDE
MENOT
MENTE
MENTI
MANCE
MANDE
MANOT
MANTE
MANTI
MONCE
MONDE
MONOT
MONTE
MONTI
NCEAR
NCECT
NCEND
NCENT
NCERE
NCERS
NCESS
NCEST
NCEVE
NCEAR
NCECT
NCEND
NCENT
NCERE
NCERS
NCESS
NCEST
NOTED
NOTEN
NOTER
NOTHA
NOTHE
NOTHI
NOTHO
NOTIN
NOTIO
NOTUR
NOTOR
NTEAR
NTECT
NTEND
NTENT
NTERE
NTERS
NTESS
NTEST
NTEVE
NTEAR
NTECT
NTEND
NTENT
NTERE
NTERS
NTESS
NTEST
OMEAR
OMECT
OMEND
OMENT
OMERE
OMERS
OMESS
OMEST
OMEVE
OMEAR
OMECT
OMEND
OMENT
OMERE
OMERS
OMESS
OMEST
ONEAR
ONECT
ONEND
ONENT
ONERE
ONERS
ONESS
ONEST
ONEVE
ONEAR
ONECT
ONEND
ONENT
ONERE
ONERS
ONESS
ONEST
ONSTA
ONSTE
ONSTI
ONSTR
ONSTA
ONSTE
ONSTI
ONSTR
OMEAR
OMECT
OMEND
OMENT
OMERE
OMERS
OMESS
OMEST
OMEVE
OMEAR
OMECT
OMEND
OMENT
OMERE
OMERS
OMESS
OMEST
ONEAR
ONECT
ONEND
ONENT
ONERE
ONERS
ONESS
ONEST
ONEVE
ONEAR
ONECT
ONEND
ONENT
ONERE
ONERS
ONESS
ONEST
ONSTA
ONSTE
ONSTI
ONSTR
ONSTA
ONSTE
ONSTI
ONSTR
OREAR
ORECT
OREND
ORENT
ORERE
ORERS
ORESS
OREST
OREVE
OREAR
ORECT
OREND
ORENT
ORERE
ORERS
ORESS
OREST
ORTED
ORTEN
ORTER
ORTHA
ORTHE
ORTHI
ORTHO
ORTIN
ORTIO
ORTUR
ORTOR
OTHAN
OTHAT
OTHAV
OTHEN
OTHER
OTHIN
OTHIS
OTHOU
OULIN
OUNCE
OUNDE
OUNOT
OUNTE
OUNTI
OUREA
OURED
OURES
OURIN
OUROM
OUTED
OUTEN
OUTER
OUTHA
OUTHE
OUTHI
OUTHO
OUTIN
OUTIO
OUTUR
OUTOR
OVEAR
OVECT
OVEND
OVENT
OVERE
OVERS
OVESS
OVEST
OVEVE
OVEAR
OVECT
OVEND
OVENT
OVERE
OVERS
OVESS
OVEST
PEREA
PERED
PERES
PERIN
PEROM
PROME
PRONE
PRONS
PRORE
PRORT
PROTH
PROUL
PROUN
PROUR
PROUT
PROVE
REAIN
REALL
REAME
REAND
REANT
REARE
REART
REATE
REATI
REAVE
REDER
REDID
RESTA
RESTE
RESTI
RESTR
RESTA
RESTE
RESTI
RESTR
RINCE
RINOT
RINTE
ROMAN
ROMEN
ROMON
STAIN
STALL
STAME
STAND
STANT
STARE
START
STATE
STATI
STAVE
STEAR
STECT
STEND
STENT
STERE
STERS
STESS
STEST
STEVE
STEAR
STECT
STEND
STENT
STERE
STERS
STESS
STEST
STIGH
STILL
STIND
STINE
STING
STINT
STION
STIST
STITH
STIVE
STREA
STRED
STRES
STRIN
STROM
TEDER
TEDID
TENCE
TENDE
TENOT
TENTE
TENTI
TEREA
TERED
TERES
TERIN
TEROM
THAIN
THALL
THAME
THAND
THANT
THARE
THART
THATE
THATI
THAVE
THEAR
THECT
THEND
THENT
THERE
THERS
THESS
THEST
THEVE
THEAR
THECT
THEND
THENT
THERE
THERS
THESS
THEST
THIGH
THILL
THIND
THINE
THING
THINT
THION
THIST
THITH
THIVE
THOME
THONE
THONS
THORE
THORT
THOTH
THOUL
THOUN
THOUR
THOUT
THOVE
TINCE
TINOT
TINTE
TIOME
TIONE
TIONS
TIORE
TIORT
TIOTH
TIOUL
TIOUN
TIOUR
TIOUT
TIOVE
TUREA
TURED
TURES
TURIN
TUROM
TOREA
TORED
TORES
TORIN
TOROM
ULDER
ULDID
UNDER
UNDID
USEAR
USECT
USEND
USENT
USERE
USERS
USESS
USEST
USEVE
USEAR
USECT
USEND
USENT
USERE
USERS
USESS
USEST
VEREA
VERED
VERES
VERIN
VEROM
WASTA
WASTE
WASTI
WASTR
WASTA
WASTE
WASTI
WASTR
WHIGH
WHILL
WHIND
WHINE
WHING
WHINT
WHION
WHIST
WHITH
WHIVE
WITED
WITEN
WITER
WITHA
WITHE
WITHI
WITHO
WITIN
WITIO
WITUR
WITOR
YOULD
YOUND
YOUSE
QT
*ZODIACHRONOLOGY*

Trigraphs…
Before I will list a full combination of – all – those trigraphs to each other………..
Must you, QT? Oh well, I see you have.
….. I should mention that the ‘IOFBc’ formation of line 13 may very well be seen in context with the ‘+’ symbol as one of the ‘+’ symbols is very close to the formation (‘+_IOFBc’). Using the correct combination of ‘+’ (which presumably is either S, L, T or E) ……….
Well, I’m not sure we can presume it’s one of those characters, that plus.
It might be a different character each time it appears.
It might be a combination of different characters.
It might not be a character at all (but it probably is.)
That’s all I wanted to say, really.
I suppose if we don’t presume anything, then we’ll never solve it, but…..
Do go on – don’t mind me. ![]()
Trigraphs…
Before I will list a full combination of – all – those trigraphs to each other………..Must you, QT? Oh well, I see you have.
….. I should mention that the ‘IOFBc’ formation of line 13 may very well be seen in context with the ‘+’ symbol as one of the ‘+’ symbols is very close to the formation (‘+_IOFBc’). Using the correct combination of ‘+’ (which presumably is either S, L, T or E) ……….
Well, I’m not sure we can presume it’s one of those characters, that plus.
It might be a different character each time it appears.
True..then it would be a different – unsolvable – encryption method than the 408..
It might be a combination of different characters.
..as above..
It might not be a character at all (but it probably is.)
..well, what else..but still possible, true.
That’s all I wanted to say, really.
I suppose if we don’t presume anything, then we’ll never solve it, but…..
Do go on – don’t mind me.
lol..can’t you help me with it? It’s not so easy and I waste a lot of time..couldn’t make the Eward Elgars’, the Taman Shud, the Z340, the Voynoch and some others either..maybe someone would like to give me one I could solve..just for the success feeling…
*ZODIACHRONOLOGY*
…and I agree…a Genetic Algorithm should be added..
http://citeseerx.ist.psu.edu/viewdoc/do … 1&type=pdf
QT
*ZODIACHRONOLOGY*
Hi, a wonderful lazy Sunday to do some Z research..
Last week I have downloaded Cryptool, a wonderful tool for de- and encryption of ciphers. It does offer loads of tools, also for complicated encryption methods, and even does so for homophone substitution ciphers. Unfortunately, the decryption only works ‘once’ and if you know the homophone structure – so no ‘attack’ on the cipher is possible so far…..ZKD is way better regarding that issue.
However it does offer some analytical tools (Analysis>AnalyzeRandomness) and are there some similarities between the 408 and the 340. Please note that it might not be necessary to understand all of the test’s backgrounds to see such similarities:
– both ciphers fail the frequency test (of course, as they are homophone ciphers with >26 symbols for the cleartext alphabet)
– both ciphers fail the ‘Poker’ test (whatever its purpose might be)
– both ciphers fail the ‘Runs’ test, however both ciphers pass the ‘Long Runs’ test
– both ciphers fail the ‘Serial’ test
Vigenere ciphers, for example, have a very clear autocorrelation structure that looks like the heartbeat of a hedgehog having a nap on a heating radiator…not so the 408 & the 340. Their autocorrelation look – surely not identical (different ciphers, different number of homophones, different lenght etc.) – but are in some way comparable to each other:


…continue next post (3 attachments only..)…
QT
*ZODIACHRONOLOGY*
…similarly the ‘floating frequency’ is indeed very comparable to each other:
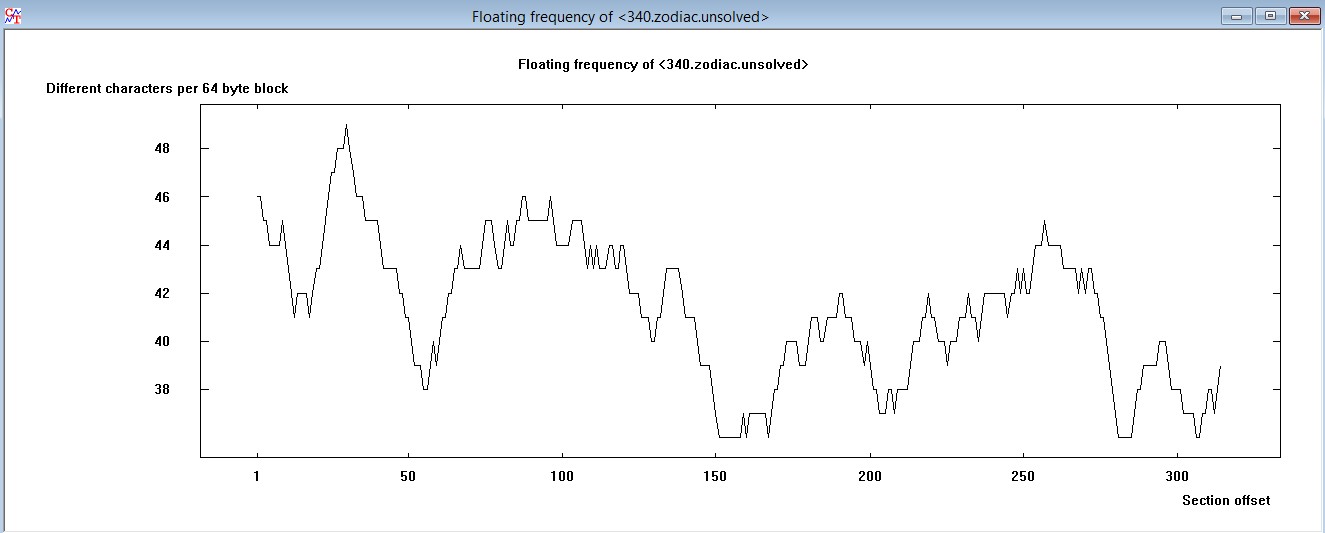
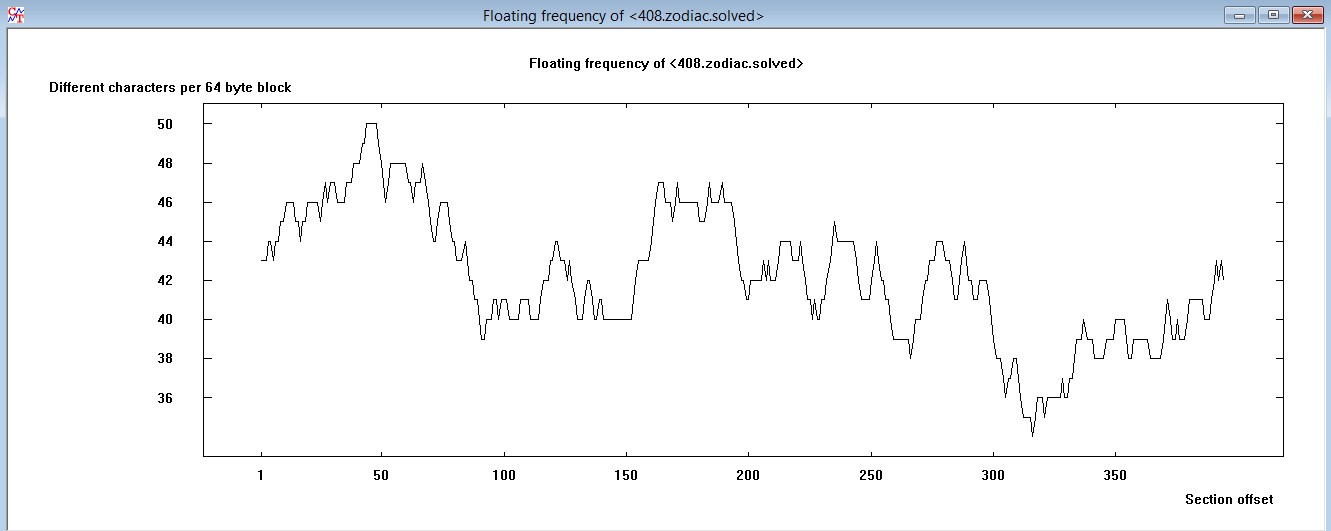
QT
*ZODIACHRONOLOGY*
However our focus shall not be on statistical analysis, although at least when I look at the floating frequency, I feel the idea supported that the 340 is in fact a homophone substitution cipher, too.
Using ZKDecrypto, the tool we love, for each alphabetical letter a numbers of homophones may be defined. This may either happen according to the expected frequency or by entering the numbers of homophones manually for each letter (‘Init Key’). This structure does not change during the cipher attack as only the homophones are changed until a good score is reached:
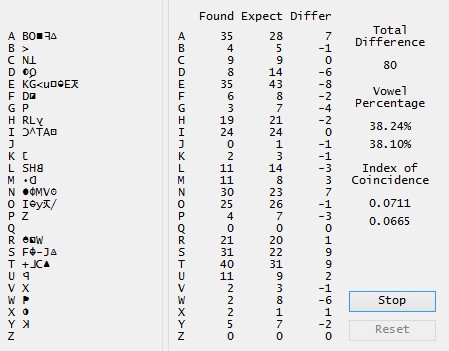
This is why I would like to draw our focus on the number of homophones that might be expected for each alphabetical letter.
Now we may assume that Z had some knowledge in cryptology. Considering this, we may expect him to having used the frequency of letters used in the 408 cleartext to define the amount of homophones for each letter. This amount can easily be figured out as the following example will show:
Letter ‘E’:
54 times used in the 408 cleartext
13.2% frequency (54/408)
multiplicated with the number of homophones (55)
RESULT: 7,28
which equals 7 homophones for the letter ‘E’. In fact, Z had used exactly seven homophones for this letter.
This structure is valid for 16 out of 26 alphabetical letters (ABCEHJKOPQRUVWYZ)…but hey – why not for the rest of it? To understand this, we should have a short look on the letter ‘D’. Present 7 times in the 408 cipher, this letter has – identical to the letter ‘P’ – of 1.7%. Nevertheless, although these two letters – ‘P’ and ‘D’ – have the same frequency, Z had used only one homophone for the letter ‘P’ but two homophones for the letter ‘D’.
Why?
This is not clear unless we have a look on the common letter frequency tables, such as the one of Scott Bryce. Because there, in fact, the frequency of the two letters ‘P’ and ‘D’ are different. They are different in a way that ‘P’ would be present in the 408 with a frequency of 2.0% (equal to 1.1 homophones), the letter ‘D’ however would be present with a frequency of solid 4.0% (equal to 2.19 homophones).
So in fact, according to Scott Bryce’s letter frequency table, in the 408 (with 55 homophones), the letter ‘D’ would be represented by two homophones while the letter ‘P’ would be represented by one homophone only.
This little fact, that the ‘D’ has two homophones instead of one (which would have been implied by the cleartext’s frequency table itself) indicates that Z had chosen the amount of homophones according to a different letter frequency table.
So Z did not distribute the amount of homophones according to his own cleartext frequency, but rather according to a separate statistic frequency table.
Almost 70% of the homophones match Scott Bryce’s frequency table (EIOASRMGUBYWPDVKZQJ), including the letter ‘D’, but not all of them. Considering this, we should accept that Z did not Scott Bryce’s frequency table as it did not exist when Z made his cipher and that Z had used a different frequency table.
In fact, Scott Bryce is expecting a 9.3% frequency of the letter ‘T’, leading to 5.09 or 5 homophones for ‘T’. However Z had used only 4 homophones for the letter ‘T’, indicating that he must have expected the letter ‘T’ to occur with a frequency of less than 8.2%. Again..to distribute the homophones on the alphabet
– Z did not use the cleartext’s own frequency
– the letter ‘D’ and some others are complying rather to a separate frequency table
– 70% of the amount of homophones is a match to such a frequency table
– however there are still differences, indicating that Z had used a different frequency table than Scott Bryce’s
– of the remaining 30%, the amount of homophones differs only max. 1 homophone, indicating that the number of homophones has not been chosen accidentially but according to a letter frequency table.
The letter ‘D’ simply revealed that Z had acted according to such a separate letter frequency table, e.g. from a cryptology book. Differences stil do exist, so I looked at other frequency tables to compare with Z’s homophone distribution: Kahn, Singh, Cornell Math and Oxford dictionary.
They mostly are similar to Scott Bryce’s ETAION SHRDLU frequency order of the alphabet.
Z’s frequency order of the alphabet however was different. He used 7 homophones for the letter ‘E’, 5 homophones for the letter ‘N’ and the continued with the other letters. So his frequency order of the alphabet was similar to
7 homophones: E
5 homophones: N
4 homophones: TAIOS
3 homophones: RL
2 homophones; HDF
so Z’s frequency order of the alphabet is somehow like the following: ENTAI OSRLHDF.
Well, all this can be explained very easily. Z did not randomize the amount of homophones, otherwise there could easily have been e.g. three homophones for letters such as ‘M’ or ‘G’. His structure also does not resemble the cleartext’s frequency, but rathern a separate frequency table. This frequency table might have come from a 1920-1970 cryptology book such as David Kahn’s or the ‘Cryptography, the Science of Secret Writing.‘ (please let me know if you do know the frequency table of this book..).
In 1970, the letter frequencies might have been understood according to such book’s knowledge during that time and therefore might have differed from the nowadays well-accepted ETAOINSHRDLU structure.
Now here comes the deal: We do accept Z’s frequencies so far that the correct 70% is also correct in the 340 cipher.
We therefore do accept Scott Bryce’s letter frequency for the letter ‘E’, as it leads to the same amount of homophones (7) as Z had used in the 408. According to this – and according to Z’s cleartext frequency [which is not valid] – the amount of homophones for the letter ‘E’ would be:
63 x 12.5% = 7.88
which is equal to 8 homophones for the letter ‘E’. This in compliance with Z’s (yet unknown) frequency table under negligance of rounding errors. The same we do with the rest of the 70% matching letters, therefore for EIOASRMGUBYWPDVKZQJ we do assume to Z having used the same or similar frequencies like Scott Bryce.
For the rest of the alphabet, we should have a closer look at each alphabetical letter (TLNHFCKX). For those letters, we have to figure out if Z’s frequency – if not identical with Scott Bryce’s expectation – if Z had used a higher or a lower frequency for each particular letter.
For the letter ‘T’ for example, Z had used 4 homophones although letter frequency (both, cleartext and Scott Bryce) would implicate an amount of 5 homophones. Therefore it might be assumed that Z had used a lower expected frequency for the letter ‘T’.
Different for the letter ‘L’: There Z had expected 3 homophones, although his own cleartext letter frequency would have implied 5, Scott Bryce’s letter frequency implying only 2 homophones. So Z there had expected a higher than Scott Bryce would do.
We continue to complete our alphabet and end up with the following – according to Scott Bryce – expected amount of homophones for each letter:
E: 7.88
I: 4.57
T: 5.83
L: 2.61
..
etc.
For the letters matching Scott Bryce’s frequency table, we do accept the amount of homophones, therefore E=8, I=5. For the letter ‘T’ and ‘L’ however, we now modify the expected amount of homophones so that it does match Z’s frequency table:
Z’s expectancy on the letter ‘T’ was essentially [lower, so we do reduce the amount of homophones from 5.83 to 5 only. The formula is 5.83/(5.09/4)x5.83=4.58 > 5).
Z’s expectancy on the letter ‘L’ was essentially higher, so we do increase the amount of homophones from 2.61 to 3 (2.61/(2,28/3) =3.43 > 3).
Finally we end up with 64 expected homophones, one more than actually available. This is no problem as we do not yet know Zs precise expectations of letter frequencies, but rather have derived it from the amount of homophones he used in the 408.
The amount of homophones had to be rounded by him, so such a rounding error in fact may have been expected.
To apply the cipher structure, however, we now do reduce one homophone from the letter ‘D’, this mainly because its expected amount of homophones is 2.51, which is slightly above the 2.5 rounding level.
An alternative would be to reduce this ‘backlog’ homophone from the letter ‘E’ or ‘N’ or ‘T’, as those letters have the most homophones and therefore might have led to the rounding error most likely. To really understand where this overall, 26 letters including, rounding error is deriving from, it is required see which ENTAI OSRLHDF letter frequency table has originally been used by Z.
However by reducing this backlog homophone, we do now have an amount of homophones for each letter which matches Zs expectancy of letter frequency at its best:
EITLOANSRMHGFUCBYWPDVKXZQJ
85535564422122111112111000
or in alphabetical order
ABCDEFGHIJKLMNOPQRSTUVWXYZ
51128212501326510445211100
Latter in fact, imo, is the best configuration of the ‘Init Key’ for further decryption.
…continue next post…
QT
*ZODIACHRONOLOGY*
…this is the transformation table of 408 to 340 amount of homophones:
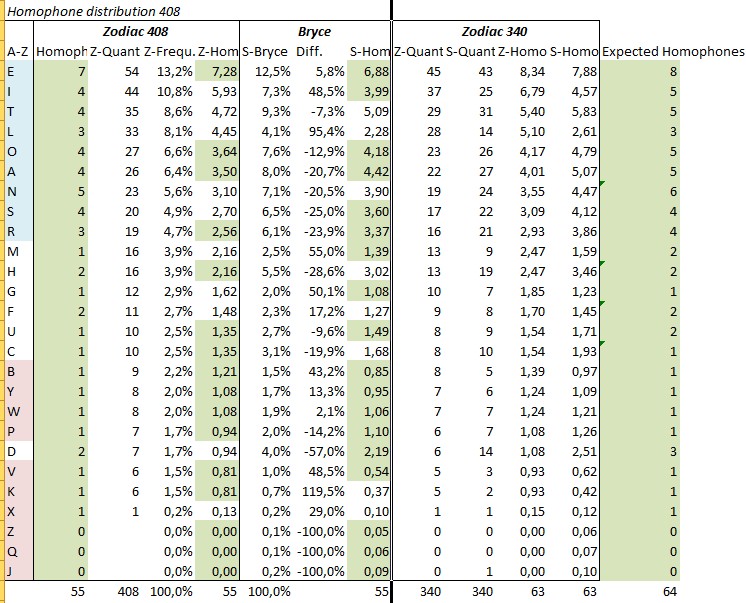
…and as it may be entered as an init key for the cipher:
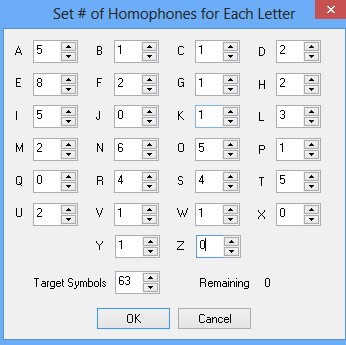
QT
*ZODIACHRONOLOGY*
Conclusio:
1. In the 408, Z presumably followed a frequency table which is different from the cleartext’s own frequency.
2. This frequency table is mainly (~70%) coinciding with common frequency tables and does the letter ‘D’ indicate that Z had used such one.
3. The frequency table used, however, has a slightly modified expectation of alphabetical letters (ENATOI or comparable instead of ETAION). This frequency table might have derived from a cryptology book.
4. Modified according to this frequency table, we may expect a certain amount of homophones for each alphabetical letter, as far as Z has not changed his encryption method.
5. Floating frequency and autocorrelation indicate that Z had used the same encryption method in both ciphers.
Nevertheless some questions do occur:
A.) Which cryptology book / frequency table had Z used to receive his EN…. frequency table from?
B.) Considering ‘S’ being a good candidate for the ‘+’ symbol (both, the double letter frequency as well as the overall frequency are a good match), how can this comply with 4 homophones being expected for such a letter frequency? Similar with the letter ‘L’, which should be expected to be represented by two additional homophones..?
Latter aspect increases the possibility that ‘+’ is rather representing the letter ‘T’ or ‘E’ instead of ‘S’ or ‘L’…except if Z had chosen to use only one homophone for this letter to use e.g. the other 3 homophones for different letters, such as to cover the alphabetical letters ‘Z’, ‘Q’ and ‘J’ (as their expected amount of homophones is zero, according to their frequency).
However, something is wrong in the box: Although the symbols ‘+’ as well as ‘p’ (reverse P) would expect to be represented by more than one homophones (rather 3-4), both of them are repeating on the position of the double letters! This would not happen if other homophones were involved, at least not three times in a row..so in fact, Z has changed some of his cipher encryption method by the way that he reduced the number of homophones of certain letters by purpose to irritate, to not let the former encryption method (408) become valid in the same way.
We therefore should be aware that, at least for the ‘+’ as well as the ‘p’ symbol a modification in the distribution of homophones has actively been done. The circumstance that Z might have used only one symbol for a letter that actually would be expected to be covered by multiple homophones, may be called a ‘blender’.
Final comment: Does a book such as ‘Cryptography, the Science of Secret Writing’ eventually contain such a frequency table matching Z’s homophone structure? We might look for such a frequency table matching the 408 homophone structure (100%) to figure out the ‘true’ values and subsequently the correct amount of homophones for each alphabetical letter in the 340..
QT
*ZODIACHRONOLOGY*
