
Interesting stuff. If I’m understanding your approach correctly, I think the problem you’re going to have is the following. For your calculations to remain tractable, you’ll have to limit your strings to the point that they are relatively unconstrained. If you expand your strings to the point that they are sufficiently constrained (which is really the vast majority of the cipher), your calculations become intractable.
I did something a little similar to what your describing when I worked on my cipher solver which is called CipherExplorer. One of the components of the scoring function was the number of recognizable words of a configurable length range — usually I used lengths of 3-5 or 3-6. I recognized the words by putting the contents of /usr/share/dict/words (~225,000 words) into a trie. I added some optimization to the trie for doing incrementally increasing lookups, i.e. removing redundancy when looking up words of length 3, 4, 5, 6 starting from the same position.
Of course, this had the same problem mentioned earlier in this thread, namely word overlap. But, that was okay for me because I translated the number of words found into a score based on statistical expectations developed from analyzing various text.
I also feel the same way as glurk… If the the 340 was a standard homophonic substitution cipher, it would have been solved ten years ago, if not earlier. I think it’s fundamentally a HSC, but there are almost certainly one or more additional complexities that are thwarting straight-forward analysis. Regarding your comments about sequential symbol assignment, many of the cipher generators (including the one at my website) don’t do sequential symbol assignment. It doesn’t matter. The set of available cipher solvers can, relatively easily, solve ciphers equivalent to the apparent strength of the 340 (i.e. 63 symbols across 340 symbol instances) regardless of symbol-assignment algorithm.
could qt’s method be useful for identifying columnar transposition? e.g. – if columns 1-6 in a given row are "mtheod" you could surmise that the word is "method" and column 2 was moved two columns over. right?

But, that was okay for me because I translated the number of words found into a score based on statistical expectations developed from analyzing various text.
Nice idea!

@Zodiacrevisited: Thanks for your comment, wonder what a machine you had used when putting 225,000 words in a trie.
As long as we’ve got way too many variations possible, even with words in it, I’m not sure about why the cipher should not be a homophone substitution. The question remains why this one has not been solved, however, using the tools you mentioned.
Regarding the FCCPs..I’ve now chosen three parts of the cipher with text strings of length 9, 10, and 12:

And they are quite well-connected to each other:
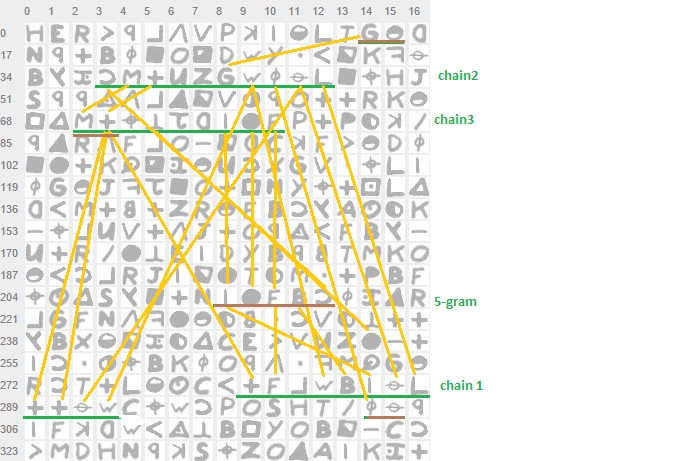
In the following scenario, I’ve considered all the information above as well as frequeny data for e.g. bigrams. I then set-up the search function to first search the longest string, then second longest and finally the third. So far, all searching through for words with a length>5. All based on the assumption + =’L’, too (Bernoulli; could be modified).
The result actually looks like this:

The program works but the questions are different ones:
– Is there any word > 5 in each of the strings? Is the dictionary sufficient to find Zs words?
– How long does the analysis take (simultaneous calculation > memory error /// vs. /// step-by-step calculation > iterating every result)
It is quite easy to combine the three steps into a simultaneous calculatin. But my pc gives up on that one while the step-by-step calculation is running. Nevertheless I’ll interrupt the calculation to search for two words in each string (length >4) instead of only word of length >5 (overlapping will still show up).
QT
*ZODIACHRONOLOGY*
Update:
Today I modified the tool to go for a longer string, 18 letters, instead of cross-checking three shorter strings. The search function is set-up to look for at least two 5-letter words. In addition, the program was modified in a way that it first interates a certain group of 5-grams instead of iterating any A-Z variables (which is done, too, but later). The program is very fast, however it has 1,3B variations to perform a complete check (non-outliers, + being an ‘L’).
The results are promising, eg finding phrases such as
EELESSRECALLCSENSE
(recall, sense)
Nevertheless, many results are – so far – still some sort of misinterpretation, e.g. overlapping (e.g. ‘raise’ and ‘sells’). There still is a huge amount of data, which should either take a while to get through or is not possible to be performed on a normal pc at all. There also is the risk that there are no more than one 5-letter words in this specific part of the cipher. If there are, however, the cleartext result could actually come up right now, while running the program.
QT
*ZODIACHRONOLOGY*
The FCCP analyzer had run for the last three consecutive days and will, hopefully, complete soon with the first 1,3B variations of frequent, cipher related analysis of the text string in line 17/18. So far it has produced ~200,000 results of which 98% are still related to e.g. overlapping or plural terms in the dictionary (e.g. ‘agent’ + ‘agents’ finding as two words). Nevertheless there are already some interesting results, just to show a few:
LTUGHESELLSGAUGE [{‘index’: 6, ‘word’: ‘sells’}, {‘index’: 11, ‘word’: ‘gauge’}]
LEAGREEALLEGINGE [{‘index’: 2, ‘word’: ‘agree’}, {‘index’: 7, ‘word’: ‘alleging’}]
LTOMHESELLSMIAMI [{‘index’: 6, ‘word’: ‘sells’}, {‘index’: 11, ‘word’: ‘miami’}]
LADULTSALLSUBRUL [{‘index’: 1, ‘word’: ‘adult’}, {‘index’: 1, ‘word’: ‘adults’}]
LEACRESALLSCARCE [{‘index’: 2, ‘word’: ‘acres’}, {‘index’: 10, ‘word’: ‘scarce’}]
LIGHTTWILLWHICHH [{‘index’: 0, ‘word’: ‘light’}, {‘index’: 10, ‘word’: ‘which’}]
LAGENTSALLSERVED [{‘index’: 1, ‘word’: ‘agent’}, {‘index’: 1, ‘word’: ‘agents’}, {‘index’: 10, ‘word’: ‘serve’}, {‘index’: 10, ‘word’: ‘served’}]
The ‘light twill which’ I like most, so far (found a third 5-letter word, ’twill’, although not present in the dictionary).
QT
*ZODIACHRONOLOGY*
Source code…
The following is a working Python code to perform a cipher crack on the 340.
It will not work on a normal pc as it contains too many variables for iteration: 9 alphabetical letters, 1 vowel and 1 frequent bigram plus both, the letter ‘L’ as a + symbol as well as a list of 5-grams according to certain trigram and double letter frequencies. Latter can be modified in the settings ("pl" and "quint"). Not all variables are necessarily required due to the usage of the program on other parts of the cipher, e.g. "Y"). The dictionary ("lex") must be modified according to individual preferences (in this example it consists of only two words).
The program requires a certain amount of memory, on my pc with 4GB it’s getting an overflow resulting in memory error..however up to 5 alphabetical variables work excellent (~1.3B variations, running time 4-5 days @19GFlops).
The dictionary should be set-up in a way that longer words are found, e.g. searching for two words of the length >6 in this specified string of 24 letters ("chain1")..running this program on a calculating machine with sufficient memory should actually deliver fine results, although overlapping words would still occur in the list.
So it’s now an open source project :p
For those interested in the program itself, less than in finding the words, you may directly go to the "Main Program" section…there you can find the chain, in this case starting from the ‘G’ symbol in line 16 and ending with the reverse "C" symbol in line 18 (7% of the cipher – in one readable line of cleartext).
QT
# ZODIAC 340 CIPHER CRACKING TOOL
# compiled by Quicktrader
# Python 3.5 Environment (CPython recommended)
# FCCP-String concatenation ("Fictitiously-Created Cleartext Phrases")
# Aho-Corasick algorithm for linguistic multiple pattern match analysis (external)
# Iterators & variables
lex = ['ABOUT', 'ABOVE', '...']
alphabet = ["E", "T", "A", "O", "I", "N", "S", "R", "H", "L", "D", "C", "U", "M", "F", "P", "G", "W", "Y", "B", "V", "K", "X", "J", "Q", "Z"]
bigrams = ['AL', 'SL', 'RL', 'BL', 'GL']
bigrams2 = ["AL", "HE", "IN", "ER", "AN", "RE", "AT", "ON", "NT", "ES", "ST", "EN", "TO", "IT", "IS", "OR", "AS", "TE", "ET", "NG", "TH", "ND", "HA", "ED", "OU", "EA", "HI", "TI"]
quint = ['THERE', 'ENTHE', 'ENTER', 'ERENT', 'THAND', 'HATHE', 'HATHA', 'ENTHA', 'THING', 'WITHA', 'WITHI', 'ITHER', 'THENT', 'ERERE', 'HATER', 'WITHE', 'ENTHI', 'ITHAT', 'THALL', 'HATHI', 'ITHIS', 'THITH']
vowel = ["E", "A", "O", "I", "U"]
blank = ["_"]
pl = "L" # Definition '+'-Symbol, may also be set as 'input'
q = 0
C_ = 0
kl_ = 0
l_ = 0
w_ = 0
ö_ = 0
z_ = 0
L_ = 0
M_ = 0
N_ = 0
O_ = 0
R_ = 0
T_ = 0
S_ = 0
P_ = 0
Z_ = 0
X_ = 0
Y_ = 0
U_ = 0
V_ = 0
iofbc = quint[q]
F = iofbc[2]
B = iofbc[3]
I = iofbc[0]
c = iofbc[4]
C = alphabet[C_]
kl = alphabet[kl_]
l = alphabet[l_]
w = alphabet[w_]
ö = alphabet[ö_]
z = blank[z_]
L = vowel[L_] #If pl is a consonant, otherwise 'L = alphabet[0]' (should also consider 'W' and 'R' before 'LL' in list 'vowel')
M = bigrams[M_]
N = bigrams2[N_]
O = bigrams2[O_]
R = alphabet[R_]
T = alphabet[T_]
S = alphabet[S_]
P = alphabet[P_]
Z = alphabet[Z_]
X = alphabet[X_]
Y = alphabet[Y_]
U = alphabet[U_]
V = alphabet[V_]
chain1 = N+R+c+T+pl+L+S+P+C+kl+pl+F+l+w+B+I+ö+L+pl+pl+ö+w+C+z+w+c
# Functions
from collections import deque
def init_trie(keywords):
""" creates a trie of keywords, then sets fail transitions """
create_empty_trie()
add_keywords(keywords)
set_fail_transitions()
def create_empty_trie():
""" initalize the root of the trie """
AdjList.append({'value':'', 'next_states':[],'fail_state':0,'output':[]})
def add_keywords(keywords):
""" add all keywords in list of keywords """
for keyword in keywords:
add_keyword(keyword)
def find_next_state(current_state, value):
for node in AdjList[current_state]["next_states"]:
if AdjList[node]["value"] == value:
return node
return None
def add_keyword(keyword):
""" add a keyword to the trie and mark output at the last node """
current_state = 0
j = 0
keyword = keyword.lower()
child = find_next_state(current_state, keyword[j])
while child != None:
current_state = child
j = j + 1
if j < len(keyword):
child = find_next_state(current_state, keyword[j])
else:
break
for i in range(j, len(keyword)):
node = {'value':keyword[i],'next_states':[],'fail_state':0,'output':[]}
AdjList.append(node)
AdjList[current_state]["next_states"].append(len(AdjList) - 1)
current_state = len(AdjList) - 1
AdjList[current_state]["output"].append(keyword)
def set_fail_transitions():
q = deque()
child = 0
for node in AdjList[0]["next_states"]:
q.append(node)
AdjList[node]["fail_state"] = 0
while q:
r = q.popleft()
for child in AdjList[r]["next_states"]:
q.append(child)
state = AdjList[r]["fail_state"]
while find_next_state(state, AdjList[child]["value"]) == None
and state != 0:
state = AdjList[state]["fail_state"]
AdjList[child]["fail_state"] = find_next_state(state, AdjList[child]["value"])
if AdjList[child]["fail_state"] is None:
AdjList[child]["fail_state"] = 0
AdjList[child]["output"] = AdjList[child]["output"] + AdjList[AdjList[child]["fail_state"]]["output"]
def get_keywords_found(line):
""" returns true if line contains any keywords in trie """
line = line.lower()
current_state = 0
keywords_found = []
for i in range(len(line)):
while find_next_state(current_state, line[i]) is None and current_state != 0:
current_state = AdjList[current_state]["fail_state"]
current_state = find_next_state(current_state, line[i])
if current_state is None:
current_state = 0
else:
for j in AdjList[current_state]["output"]:
keywords_found.append({"index":i-len(j) + 1,"word":j})
return keywords_found
# Main program
import re
chain1 = N+R+c+T+pl+L+S+P+C+kl+pl+F+l+w+B+I+ö+L+pl+pl+ö+w+C+z+w+c
AdjList = []
init_trie(lex)
print ('FCCP-List')
for q in range(0, 22): ## Amount of 5-grams to be checked (List: 'quint')
iofbc = quint[q]
F = iofbc[2]
B = iofbc[3]
I = iofbc[0]
c = iofbc[4]
for w, z, C, ö, L, l, kl, P, S, T, R, N in [(w,z,C,ö,L,l,kl,P,S,T,R,N) for w in alphabet for z in alphabet for C in alphabet for w in alphabet for ö in alphabet for L in vowel for kl in alphabet for P in alphabet for R in alphabet for S in alphabet for T in alphabet for N in bigrams2]:
chain1 = N+R+c+T+pl+L+S+P+C+kl+pl+F+l+w+B+I+ö+L+pl+pl+ö+w+C+z+w+c
if int(len(get_keywords_found(chain1))) >2: ## Number of keywords to be found in chain1
print (chain1, get_keywords_found(chain1))
print ('List complete')
*ZODIACHRONOLOGY*
Modified Python to the CELEBRITY CIPHER and in fact it comes up with some partial solutions. Here is the one I like most:
__A_G ATTORNEY TARGETTING AIRLINE TO .. R___ .. CA ___Y TO __A_G ATTORNEY
The cipher is not complete as you can replace certain parts of it with multiple words (e.g. SLANG, CLANG etc.). Nevertheless, this matching (!) combination of the three 10-, 8- and 7-letter words was not seen before.
SLANG ATTORNEY TARGETTING AIRLINE TO BE RUN RENT THE TA CITY TO SLANG ATTORNEY
CLANG ATTORNEY TARGETTING AIRLINE TO DO FUN RENT THE TA PITY TO CLANG ATTORNEY
All the bold letters in the first line above have been added manually, the rest of the cleartext configured itself according to the cipher structures (cross-matching word structures).
QT
*ZODIACHRONOLOGY*

That’s an interesting fit; nice job.
Best I came up in a previous brief attempt for the beginning part was: UNCLE SINCLAIR OGLETHORPE CULPRIT
I wonder how many sensible combinations of words can fit within those 10-, 8- and 7-letter cipher chunks.
Here are a few more words that fit in the "_ _ A _ G" pattern: craig bragg chang twang huang cragg
Here are a few more words that fit in the "_ _ A _ G" pattern: craig bragg chang twang huang cragg
Correct, could also a ‘bragg’ or ‘chang’ attorney, for example. Not many other possibilities, at least not with a normal-sized dictionary.
QT
*ZODIACHRONOLOGY*
Here are a few more words that fit in the "_ _ A _ G" pattern: craig bragg chang twang huang cragg
Correct, could also be a ‘chang’ attorney, for example. Not many other possibilities, at least not with a normally-sized dictionary. There are some other solutions, will post them asap.
QT
*ZODIACHRONOLOGY*
Python running..
..with some assumptions:
a.) We know the + symbol is frequent in both, singular and double letters. Thus Bernoulli’s formula has lead us to either ‘L’ or ‘S’ as being the represented cleartext letter. ![]()
b.) We also ‘know’ that two repeating trigrams are present in the cipher. Those are even connected in the IoFBc-string (line 13). Usually a trigram would occurr only once, maximum twice (statistically) in a text with 340 letters. It therefore likely consists of two of such frequent trigrams, e.g. THI + ING leading to THING or THA + AND leading to THAND etc. Thus we use a list of such frequent trigram combinations (not 5-grams!). ![]()
c.) The ‘M+’ bigram occurs three times..assuming an ‘L’ or an ‘S’ as its second letter, we get a bigram list for ‘M+’ as a result, e.g. consisting of ‘AS’, ‘DS’, ‘OS’ etc..due to its frequency ‘QS’, ‘JS’, etc. is not very likely. ![]()
d.) There are other bigrams repeating at least once. We do look up the common bigram frequencies and create a second list. ![]()
e.) In line 17, 18 & 19, the ‘w’ symbol occurs four times. This implies that it must be a frequent letter (in a selection of 27 symbols, four of it is a ‘w’, it therefore has a sectional frequency of 14%!). One may therefore assume that it represents the cleartext letter ‘E’. ![]()
Now we throw everything into a pot, set-up a Python script with an algorithm to find at least two words of a length > 4. All this we use e.g. on a 16-symbol section starting in line 17. ![]()
So far my program finds multiple results with two words. However, most of them are not connected in a logical sense, e.g. "SEVEREZQEASED…" contains two words, but is no more than nonsense. Other results, however, seem to be interesting: ![]()
S-AGENT-WAS-SWEEPED
S-AGENT-HAS-SHEETED
S-AGENT-WAS-SWEET-ED
etc.
The list is still running, god knows for how long. I’ll try to find some reasonable values, maybe one of it is the correct solution for this part of the cipher. If found, it should be possible to solve the cipher completely. If not (e.g. because any of the assumptions is wrong), it won’t be solved..any ideas are welcome.
QT

*ZODIACHRONOLOGY*
A new ‘cracking’ attempt:
Let’s (still) assume a certain alphabetical letter (e.g. ‘S’) for the  symbol as well as a group of frequent 5-grams (e.g. ‘ENTER’, ‘THERE’ etc.) for the
symbol as well as a group of frequent 5-grams (e.g. ‘ENTER’, ‘THERE’ etc.) for the 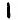

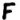
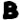
 section in line 13 of the 340 cipher.
section in line 13 of the 340 cipher.
We now construct a fictional cleartext section represented by the following symbols in line 17: 


In addition to that, we create a second fictional cleartext section from line 9 of the cipher: 
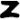
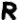
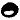
Let’s assume being a vowel as it occurs before as well as and 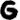 being frequent bigrams (as they do show up multiple times in the cipher).
being frequent bigrams (as they do show up multiple times in the cipher).
Now we cross-check the first section (in line 17) on a dictionary with the task to find at least two words of length >4. If found, we then check – based on the then-given key for all symbols of line 17, the second section in line 9. There we are going to look for at least one word of length >4.
Python is still running and so far, approximately 700,000 fictional combinations (FCCP strings) are found meeting the criteria above. Many of them are duplicates, e.g. if the program finds two similar words (e.g. ‘assume’ and ‘assumed’).
Then there shalll be an additional step: We then take each of the strings found and will try to match them to a third (!) section of the cipher, e.g. the one in line 3: 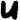
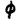
If there can be found an additional word in line 3, the result will be no, one or a group of strings (and therefore ‘keys’) that allows the ciphertext to apply cleartext on three different locations of the 340 cipher. This, however, although the various symbols are present on totally different positions in each of the three sections (cracking process itself).
Purpose of this procedure is to eliminate all potentially wrong ‘keys’ in which such multiple cleartext occurrences are not possible (due to the cipher structure). Those keys in which such occurrences are possible, however, are worth a closer look at. Such partial solution automatically delivers a total of 159 cleartext letters out of 340. In fact, an additional run might be performed to further eliminate wrongful key constellations which eventually do not produce any cleartext in all of the chosen cipher sections.
The procedure may be repeated until a final solution is found.
If the 340 is a normal substitution cipher, this procedure will automatically lead to a solution. The main risk to fail lies in the assumptions described, which not necessarily are true (e.g. no word of length >4 or symbol representing ‘E’ instead of ‘S’ etc.). Those, however, may be modified in future, too. Chances of this procedure is not only that a solution might come up (sort of a lucky strike under consideration of statistical data..) but also that it can be performed on a ‘normal’ home computer. Another advantage is that the method is not depending on a specific distribution of homophones but rather tries to freely combine the cleartext sections amongst each other.
QT
*ZODIACHRONOLOGY*
Some progress..previous method is fine, however computer gives up after a while due to memory capacity issues..however:
I refocussed on line 17 and changed the dictionary..found a new one which is way better than the other one (no words such as ‘Xerox’ etc included). I then reworked the whole dictionary (5,000 entries..) to eliminate duplicates (e.g. if ‘liability’, ‘disability’, ‘ability’ is present I deleted all but ‘ability’) to get sort of a word root dictionary. That indeed reduced the whole dictionary to approximately 2,500 entries only, still representing a top 5,000 word database. The program now runs very fine besides some minor duplicate problems (e.g. ‘agent’ and ‘gentile’..rather not a good idea to delete one of the words).
Running it for line 17, a total of 18 symbols starting from the ‘C’ symbol. Left away the third but last symbol to ease up the computation process. And there are promising results, which are shown below. It now is possible to adapt, e.g. regarding the IoFBc section or the + symbol itself. Searching for at least two words of length >4 in the 18-letter section. Potential cleartext found e.g. words such as ‘RESIDENT’, ‘DESERT’, ‘DESIRE’, ‘SILENT’, ‘SEVERE’, ‘ASSIGN’ etc..no obvious complete cleartext solution found containing any logical text, at least so far.
DESERTRTEASSETD_TE [{'index': 0, 'word': 'desert'}, {'index': 9, 'word': 'asset'}]
EESTATEEEASSETE_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
EESTAREEUASSURE_RR [{'index': 2, 'word': 'stare'}, {'index': 9, 'word': 'assure'}]
EESTOREEUASSURE_RR [{'index': 2, 'word': 'store'}, {'index': 9, 'word': 'assure'}]
EESTHREEUASSURE_RR [{'index': 3, 'word': 'three'}, {'index': 9, 'word': 'assure'}]
TESTATEEEASSETT_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
TESTAREEEASSERT_RR [{'index': 2, 'word': 'stare'}, {'index': 9, 'word': 'assert'}]
TESTOREEEASSERT_RR [{'index': 2, 'word': 'store'}, {'index': 9, 'word': 'assert'}]
TESTHREEEASSERT_RR [{'index': 3, 'word': 'three'}, {'index': 9, 'word': 'assert'}]
AESTATEEEASSETA_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
OESTATEEEASSETO_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
IESTATEEEASSETI_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
NESTATEEEASSETN_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
NESTAGEEIASSIGN_GR [{'index': 2, 'word': 'stage'}, {'index': 9, 'word': 'assign'}]
SESTATEEEASSETS_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
RESTATEEEASSETR_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
HESTATEEEASSETH_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
LESTATEEEASSETL_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
DESTATEEEASSETD_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
CESTATEEEASSETC_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
UESTATEEEASSETU_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
MESTATEEEASSETM_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
FESTATEEEASSETF_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
PESTATEEEASSETP_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
GESTATEEEASSETG_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
WESTATEEEASSETW_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
YESTATEEEASSETY_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
BESTATEEEASSETB_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
VESTATEEEASSETV_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
KESTATEEEASSETK_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
XESTATEEEASSETX_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
JESTATEEEASSETJ_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
QESTATEEEASSETQ_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
ZESTATEEEASSETZ_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
EESEVENEUISSUEE_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
TESEVENEUISSUET_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
AESEVENEUISSUEA_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
OESEVENEUISSUEO_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
IESEVENEUISSUEI_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
NESEVENEUISSUEN_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
SESEVENEUISSUES_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
RESEVENEUISSUER_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
HESEVENEUISSUEH_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
LESEVENEUISSUEL_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
DESERTNEEASSETD_TT [{'index': 0, 'word': 'desert'}, {'index': 9, 'word': 'asset'}]
DESEVENEUISSUED_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
CESEVENEUISSUEC_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
UESEVENEUISSUEU_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
MESEVENEUISSUEM_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
FESEVENEUISSUEF_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
PESEVENEUISSUEP_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
GESEVENEUISSUEG_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
WESEVENEUISSUEW_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
YESEVENEUISSUEY_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
BESEVENEUISSUEB_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
VESEVENEUISSUEV_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
KESEVENEUISSUEK_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
XESEVENEUISSUEX_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
JESEVENEUISSUEJ_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
QESEVENEUISSUEQ_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
ZESEVENEUISSUEZ_ET [{'index': 2, 'word': 'seven'}, {'index': 9, 'word': 'issue'}]
EESAGENTLESSLEE_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
EESAGENTUISSUEE_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
TESAGENTLESSLET_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
TESAGENTUISSUET_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
AESAGENTLESSLEA_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
AESAGENTUISSUEA_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
OESAGENTLESSLEO_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
OESAGENTUISSUEO_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
IESAGENTLESSLEI_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
IESAGENTUISSUEI_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
NESAGENTLESSLEN_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
NESAGENTUISSUEN_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
SESAGENTLESSLES_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
SESAGENTUISSUES_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
RESAGENTLESSLER_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
RESAGENTUISSUER_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
HESAGENTLESSLEH_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
HESAGENTUISSUEH_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
LESAGENTLESSLEL_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
LESAGENTUISSUEL_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
DESAGENTLESSLED_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
DESAGENTUISSUED_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
CESAGENTLESSLEC_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
CESAGENTUISSUEC_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
UESAGENTLESSLEU_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
UESAGENTUISSUEU_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
MESAGENTLESSLEM_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
MESAGENTUISSUEM_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
FESAGENTLESSLEF_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
FESAGENTUISSUEF_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
PESAGENTLESSLEP_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
PESAGENTUISSUEP_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
GESAGENTLESSLEG_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
GESAGENTUISSUEG_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
WESAGENTLESSLEW_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
WESAGENTUISSUEW_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
YESAGENTLESSLEY_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
YESAGENTUISSUEY_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
BESAGENTLESSLEB_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
BESAGENTUISSUEB_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
VESAGENTLESSLEV_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
VESAGENTUISSUEV_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
KESAGENTLESSLEK_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
KESAGENTUISSUEK_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
XESAGENTLESSLEX_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
XESAGENTUISSUEX_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
JESAGENTLESSLEJ_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
JESAGENTUISSUEJ_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
QESAGENTLESSLEQ_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
QESAGENTUISSUEQ_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
ZESAGENTLESSLEZ_ED [{'index': 3, 'word': 'agent'}, {'index': 4, 'word': 'gentle'}]
ZESAGENTUISSUEZ_ED [{'index': 3, 'word': 'agent'}, {'index': 9, 'word': 'issue'}]
EESILENTUISSUEE_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
TESILENTUISSUET_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
AESILENTUISSUEA_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
OESILENTUISSUEO_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
IESILENTUISSUEI_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
NESILENTUISSUEN_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
SESILENTUISSUES_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
RESISTNTEASSETR_TG [{'index': 0, 'word': 'resist'}, {'index': 9, 'word': 'asset'}]
RESILENTUISSUER_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
RESIDENTUISSUER_EG [{'index': 0, 'word': 'resident'}, {'index': 9, 'word': 'issue'}]
HESILENTUISSUEH_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
LESILENTUISSUEL_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
DESIRENTUISSUED_EG [{'index': 0, 'word': 'desire'}, {'index': 9, 'word': 'issue'}]
DESILENTUISSUED_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
CESILENTUISSUEC_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
UESILENTUISSUEU_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
MESILENTUISSUEM_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
FESILENTUISSUEF_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
PESILENTUISSUEP_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
GESILENTUISSUEG_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
WESILENTUISSUEW_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
YESILENTUISSUEY_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
BESILENTUISSUEB_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
BESIDENTUISSUEB_EG [{'index': 0, 'word': 'beside'}, {'index': 9, 'word': 'issue'}]
VESILENTUISSUEV_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
KESILENTUISSUEK_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
XESILENTUISSUEX_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
JESILENTUISSUEJ_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
QESILENTUISSUEQ_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
ZESILENTUISSUEZ_EG [{'index': 2, 'word': 'silent'}, {'index': 9, 'word': 'issue'}]
EESHAREIUASSURE_RR [{'index': 2, 'word': 'share'}, {'index': 9, 'word': 'assure'}]
EESHAMEIUASSUME_MR [{'index': 2, 'word': 'shame'}, {'index': 9, 'word': 'assume'}]
EESHOREIUASSURE_RR [{'index': 2, 'word': 'shore'}, {'index': 9, 'word': 'assure'}]
TESHAREIEASSERT_RR [{'index': 2, 'word': 'share'}, {'index': 9, 'word': 'assert'}]
TESHOREIEASSERT_RR [{'index': 2, 'word': 'shore'}, {'index': 9, 'word': 'assert'}]
DESERTNTEASSETD_TT [{'index': 0, 'word': 'desert'}, {'index': 9, 'word': 'asset'}]
EESEVEREUISSUEE_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
TESEVEREUISSUET_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
AESEVEREUISSUEA_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
OESEVEREUISSUEO_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
IESEVEREUISSUEI_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
NESEVEREUISSUEN_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
SESEVEREUISSUES_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
RESEVEREUISSUER_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
HESEVEREUISSUEH_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
LESEVEREUISSUEL_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
DESERTREEASSETD_TE [{'index': 0, 'word': 'desert'}, {'index': 9, 'word': 'asset'}]
DESEVEREUISSUED_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
CESEVEREUISSUEC_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
UESEVEREUISSUEU_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
MESEVEREUISSUEM_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
FESEVEREUISSUEF_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
PESEVEREUISSUEP_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
GESEVEREUISSUEG_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
WESEVEREUISSUEW_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
YESEVEREUISSUEY_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
BESEVEREUISSUEB_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
VESEVEREUISSUEV_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
KESEVEREUISSUEK_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
XESEVEREUISSUEX_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
JESEVEREUISSUEJ_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
QESEVEREUISSUEQ_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
ZESEVEREUISSUEZ_EE [{'index': 2, 'word': 'severe'}, {'index': 9, 'word': 'issue'}]
EESTATEHEASSETE_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
EESTAREHUASSURE_RR [{'index': 2, 'word': 'stare'}, {'index': 9, 'word': 'assure'}]
EESTOREHUASSURE_RR [{'index': 2, 'word': 'store'}, {'index': 9, 'word': 'assure'}]
TESTATEHEASSETT_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
TESTAREHEASSERT_RR [{'index': 2, 'word': 'stare'}, {'index': 9, 'word': 'assert'}]
TESTOREHEASSERT_RR [{'index': 2, 'word': 'store'}, {'index': 9, 'word': 'assert'}]
AESTATEHEASSETA_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
OESTATEHEASSETO_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
IESTATEHEASSETI_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
NESTATEHEASSETN_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
NESTAGEHIASSIGN_GR [{'index': 2, 'word': 'stage'}, {'index': 9, 'word': 'assign'}]
SESTATEHEASSETS_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
RESTATEHEASSETR_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
HESTATEHEASSETH_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
LESTATEHEASSETL_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
DESTATEHEASSETD_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
CESTATEHEASSETC_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
UESTATEHEASSETU_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
MESTATEHEASSETM_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
FESTATEHEASSETF_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
PESTATEHEASSETP_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
GESTATEHEASSETG_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
WESTATEHEASSETW_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
YESTATEHEASSETY_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
BESTATEHEASSETB_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
VESTATEHEASSETV_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
KESTATEHEASSETK_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
XESTATEHEASSETX_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
JESTATEHEASSETJ_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
QESTATEHEASSETQ_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
ZESTATEHEASSETZ_TR [{'index': 2, 'word': 'state'}, {'index': 9, 'word': 'asset'}]
RESISTTTEASSETR_TH [{'index': 0, 'word': 'resist'}, {'index': 9, 'word': 'asset'}]
DESIRETTUISSUED_EH [{'index': 0, 'word': 'desire'}, {'index': 9, 'word': 'issue'}]
BESIDETTUISSUEB_EH [{'index': 0, 'word': 'beside'}, {'index': 9, 'word': 'issue'}]
List complete
QT
*ZODIACHRONOLOGY*
