Dave,
Would you be able to elaborate on this :-
“ We have suspicions about his encoding steps, but we can’t be 100% sure about it, because different steps can produce the same results we see in the cipher solution.’

Instead of replying to everything above, I’d like to go for the ‘question’ part:
I think the question you should be asking is: If you take a million samples of text from random English-language sources, how often do you find the distribution of A’s to be anomalous?
Yes – because this could reveal some interesting facts. To do so, the standard deviation (and odds for such anormality) is a good instrument.
The text contains 37 A’s (10.9% of the cipher), correct? Scott Bryce’s letter frequency analysis gives an average 8.04% for the letter A. The letter ‘A’, however, occurs in the result more often than in average English text. One can imagine, that this is even a difference bigger than +/- 10%.
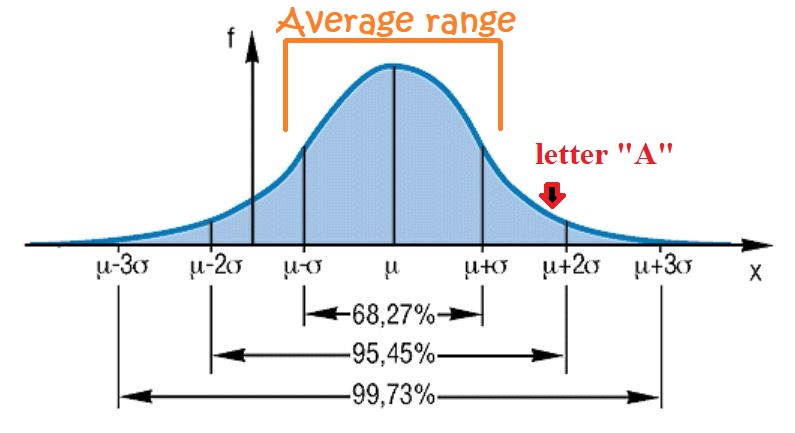
In a standard normal distribution (Gauss), there – always – is
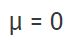
representing e.g. Scott Bryce’s average value (8.04% or 27.3 letters) and

representing the (full) set of letters A frequencies analyzed (the more letter A frequencies out of texts with length 340 the better, of course). So far, there is no reason why the frequency of the letter A should be far away from standard normal distribution, as we deal with frequency occurrences (texts with either very ‘few’ or ‘many’ certain letters simply are rare compared to average English).
I took the first ten chapters of Mark Twain’s Huckleberry Finn and separated them into 239 text fragments of length 340. Each of those fragments had one specific letter A frequency for itself. The empirical variance was as following:
n = 239
average frequency of letter A: 29.2
standard deviation (absolute): 5.32
standard deviation (percent): 18.2%
According to this English text example the letter A frequency deviates around 18% over a sample of 239 different texts.
Based on this ’empirical’ variance, we calculate:
Z = (37.0-29.2)/5.32 = 1.47
or
Φ or

for normal distribution of letter A frequencies
SD(29.2; 5.32)
P(X >= 37)
P(X >= 37) = 1 – P(X <= 37)
P(X >= 37) = 1 – P(Xst <= ((37-29.2)/5.32))
P(X >= 37) = 1.47
>> standard distribution table
P(X >= 37) = 1 – 0.92922
P(X >= 37) = 0.07078
P(X >= 37) = ~7.1%
This value is a statistical outlier. [corrected]. Please note there is no need to divide by 26 (alphabet) as there exist different values for each letters’ frequencies separately.
Opinions are welcome. In any case, chances that the ‘result’ is common English (Mark Twain) text, with regard to the letter A, are only about 7.1% (that such letter frequency is ‘realistic’). This could happen once in a while, for the letter A or another (why not..) but its not the best indication. But, keeping the alphabet in mind, it could happen with one letter – true.
QT
Update:
A is not the only letter:
A, C, D, E, F, K, T, V all show a z value greater than 1 (compared to Mark Twain)
A, R, S, T, W, X (compared to Scott Bryce) – but others do behave normal.
Compared to Scott Bryce’s frequency analysis, chances that there would occur only one additional letter A in the text is only at 3.4%.
ON AVERAGE the z value for all letters is 0.64 >>> leading to a 26.109% ‘chance’ that all letters, on average, could deviate "more extremely" than they already do. The value of 50% is the ideal average expectation, a 95% level however would rather not represent English language anymore. With this average (!) range (Gauss) of 73.891%, the ‘result’ proves to be pretty much somewhere on the border between "expected" and "non-expected" English language statistics (on average over all letters from A-Z).
The letter A certainly – this way or another – shows some (stronger) irregularity; most of the rest behaves pretty normal, imo.
QT
[was modified multiple times to get it improved – plz excuse]
https://en.wikipedia.org/wiki/Standard_normal_table (lookup from the third table)
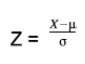
*ZODIACHRONOLOGY*
it most likely is not average English language
This is a very dangerous statement, all you are proving is that the distribution of the letter a is different from the average distribution but seeing as it is a short text this doesn’t say anything significant.
The text reads like any normal English text would.
I think it would be much more interesting to calculate the odds of this message appearing in the cypher by chance WHILE also containing another one. I think you’ll find that the odds of that are very close to 0.

Let’s skip all the mathematics of this, and look at it from a purely visual, common sense viewpoint.
Here is the text of the 340 solution from this page:
https://threatpost.com/cryptologists-zo … er/162353/
I HOPE YOU ARE HAVING LOTS OF FUN IN TRYING TO CATCH ME THAT WASNT ME ON THE TV SHOW WHICH BRINGS UP A POINT ABOUT ME I AM NOT AFRAID OF THE GAS CHAMBER BECAUSE IT WILL SEND ME TO PARADICE ALL THE SOONER BECAUSE I NOW HAVE ENOUGH SLAVES TO WORK FOR ME WHERE EVERYONE ELSE HAS NOTHING WHEN THEY REACH PARADICE SO THEY ARE AFRAID OF DEATH I AM NOT AFRAID BECAUSE I KNOW THAT MY NEW LIFE IS LIFE WILL BE AN EASY ONE IN PARADICE DEATH
Here is a chart of the solution’s letter frequencies from my post above (I reduced the image size a bit):
Now, the question for anyone – preferably native English speakers – is, does the solution look like a normal, readable, coherent English message?
My answer is yes. In fact, without actually doing a letter frequency analysis, I would NEVER even notice the slight preponderance of the letter "A" or the slight paltriness of the letters "T" and "L." It reads EXACTLY like the sort of message that Zodiac would write.
——————————–
I don’t believe in monsters.
Glurk, don’t get me wrong I see that the text is English but I wanted to know how strong is the average deviation etc – it behaves normal but has a few outliers with one of them pretty strong ("A"). In the beginning I thought those outliers couldn’t be ‘true’ for cleartext – but they are. Despite that, the text indeed shows not only one but a few ‘outliers’. Hard to say where those came from, after all.
In fact, we still don’t know how many "outlier letters" a text of such length would ‘normally’ contain (it also depends on which frequency table one refers to). Here, compared to Scott Bryce’s table, its 6 out of 26 (alphabet) letters. Can’t even say if this is a lot or not. But I think to have this information is a pretty good start (the diagram is great but are the differences larger than actually expected or not [for each letter]?).
Letter D (9x) for example looks pretty normal compared to Scott Bryce (~13 expected) but weird compared to Mark Twain (~20 to be expected). Obviously, Mark Twain had liked the letter D. Also, I had to use the empirical variances from Mark Twain to compare (as I had no access to Scott Bryce’s background data).
letter A: z = 1.82 (Scott Bryce comparison)
BTW, the frequency order should be EAOITHNRSCLWFDMUBYGPVK. It shows that it is not very much "average" of expectation, too, but still is in such possible 73% range.
@themikado90: lots of stuff was corrected (not that easy this algebra ![]() ) thank you for letting me know
) thank you for letting me know
QT
*ZODIACHRONOLOGY*
Now, the question for anyone – preferably native English speakers – is, does the solution look like a normal, readable, coherent English message?
Yep, sure does.
Sorry, I’m still going with the word-search solution….which alludes to the killer’s full name, and does name ‘lee’ several times at least. It also has an uncanny amount of related words like ‘hoot’, ‘owl’, ‘wise’, ‘halloween’…..plus the instructions to ‘circle the words’ ![]()
http://www.zodiac340.com

