
Hi,
To my question of yesterday dorachak did unfortunately give no answer. What a shame. So I had to work again. ![]()
Here is an example of exactly what I meant by my question. Left is the Z408 cipher, right a letter of Z. at (San Francisco Chronicle Letter – October 13 1969 Re: Murder of Paul Stine.) It can be found many of the same structures. My idea to compare all handwriten letters of Z with Z408 to search for a specific pattern or fingerprint. There is much work though, but I think it, I would be worth s to look for it.
Whether someone already has done before, I do not know, if so, I ask for a clue.


Zambac-
I’m sorry, but this seems like you are doing a lot of work on something that is entirely pointless. Already, doranchak has shown that these patterns commonly appear just based on the structure of the English language.
But even beyond that, your transcription of Zodiac’s letter is not accurate. For example, where Z’s letter has "could make the most noise" you have "could make the most nise"
Where Z’s letter has "parked their cars + sat there" you have "parked their cars and sat there"
As I said, I feel that this is absolutely and utterly pointless, but if you are going to do it, you AT LEAST have to transcribe what Zodiac wrote correctly. And so much of it is subjective to begin with.
-glurk
EDIT: Zambac has edited his post above and changed the image, so please note that my comments here refer to his ORIGINAL post and image, before he changed it.
——————————–
I don’t believe in monsters.

Hi,
To my question of yesterday dorachak did unfortunately give no answer. What a shame. So I had to work again.

Here is an example of exactly what I meant by my question. Left is the Z408 cipher, right a letter of Z. at (San Francisco Chronicle Letter – October 13 1969 Re: Murder of Paul Stine.) It can be found many of the same structures. My idea to compare all handwriten letters of Z with Z408 to search for a specific pattern or fingerprint. There is much work though, but I think it, I would be worth s to look for it.
Whether someone already has done before, I do not know, if so, I ask for a clue.
I don’t think this kind of analysis will reveal anything, because you can take any two pieces of text written by anyone and find the same kind of matching patterns.

Tom Voigt claims there is TRUE, REAL news coming on the 340, so maybe hold off until he reveals it. He should have an update on his site at http://www.zodiackiller.com , so rather than steal his thunder,I will just tell you to keep your eyes out for it on his site
There is more than one way to lose your life to a killer
http://www.zodiackillersite.com/
http://zodiackillersite.blogspot.com/
https://twitter.com/Morf13ZKS
Hi glurk,
many thanks for the note! I wrote it wrong …
Whether these are compare pointless, I do not know this will not until I’m done with all hand-writer letters out to. Maybe I’ll find something, who knows. ..
Maybe hiding in his letters a keyword.
Pointles is, everything that was previously there, or in other sites / forums it yielded no solution.
No one is trying something unusual. In a chaos you can also order one or meaningfulness.
A language hides more than it shows. We only have to look.
One question: Is it possible to find something if you do not know what it is?
I guess so!
Anyway, thanks again for your attention. ![]()
Hi doranchak,
ı think computer can not think, they can only be expected – with the information we write out. A program that thinks like Zodiac, there is not yet.
Also no program that can decipher the Z408 Exactly. Also, the last 18 letters. definitely not. What programs are used at all? Programs use at Zodiac or other ciphers absolutely nothing!
Because they can not think like a human. I think we will solve the ciphers as Mr. and Mrs. Harden, only with pen and head.
Zambac
EDIT: I confirmed what user qlurk says I have changed the image above after me qlurk user attention has made.
For the second time many thanks for you attention qlurk!!!!!!!
Hı quicktrader,
Sorry, excuse me, I have made myself very broad in your thread, do not come back for.
Zambac

Zambac, and that was good… It’s our thread (or morf’s) and I’m still convinced that those repeating structures will help us to better understand about this cipher. Thanks and go ahead with such valuable inputs.
QT
*ZODIACHRONOLOGY*
I got a stupid question…what if – using ZDK – approximately 20 words with 6 letters show up and in the next second they are gone? Like with an empty log file? How to avoid this? Thanks
My current hint with that one is to leave away the first line, as it shows up with better results imo.
QT
*ZODIACHRONOLOGY*
A new approach…mainly to reduce complexity of the cipher – what if we leave away some letters? When using e.g. ZDK or other decrypto tools…it is easier to crack any cipher with an e.g. 20 instead of 26 alphabet.
So leaving away the letters
YBVKXJQZ
would also make 5.48% of the cleartext ‘unreadable’. Meaning 18 to 19 symbols not being solved, however 322 still being a readable cleartext? Complexity indeed would be reduced a lot..currently trying..
QT
*ZODIACHRONOLOGY*
Where to place the letter ‘V’?
We may assume that Z had used the letter V in words such as EVERY, VERY, EVEN, EVENTUALLY, HAVE, HAVING, GIVE, GAVE or HAVING.
The good part of it is that the frequency of ‘V’ is quite a predictable one. It should appear approximately 3 times in a 340-letter cleartext, therefore symbols such as the ‘+’ might be ruled out. Assuming that ‘V’ does appear 2, 3, or 4 times only, we’ve got approximately 20 different symbols where ‘V’ might occur. It also may be assumed (in a monoalphabetic homophone cipher) that Z had used only one symbol representing the letter ‘V’.
Now I did try some guessing: If Z had used either the phrase WOULD HAVE or COULD HAVE or SHOULD HAVE, in all cases we end up with the cleartext phrase ‘OULDHAVE’. Although not sure that he had used such a phrase, it’d supply us with four vowels and three frequent consonants.
I then tried to place the OULDHAVE phrase on different positions, where symbols with a frequency of 2-4 actually do occur. The result was astonishing – in many cases it was not possible to place the phrase without getting immediate ‘signals’ of it being an improper solution. In fact, in most of the 20 symbols it was not possible to place such a phrase at all without getting some nonsense elsewhere in the cipher. The most likely symbol representing the letter ‘V’ was either the reversed ‘B’ symbol or the ‘/’ symbol. Latter even leads to the ‘++’ being a ‘LL’ cleartext double vowel (line 5).
Let’s analyze what we got here:
– Z probably had used the letter ‘V’ at least once in the 340 cipher
– ‘V’ usually is accompanied by one or two vowels, it is sort of a stand-alone consonant that doesn’t do well with other consonants next to it (exceptions: ‘dv’, ‘rv’, ‘lv’)
– ‘V’ may occur at the beginning of a word, however (e.g. ‘very’)
– guessing words containing the letter ‘V’ makes it showing up on other, often unsuitable positions of the cipher
– guessing words containing the letter ‘V’ into the cipher may lead to other valid positions of accompanying vowels
– most likely, Z had used the word ‘have’ at least once in the 340
– possibly this ‘have’ was accompanied with a word such as ‘would’, ‘should’, ‘could’ or ‘must’
– in all of the four previously considered cases, a cleartext structure would show up like this:
_ O U L D H A V E
or
_ M U S T H A V E
This may even be expanded e.g. to the phrase OULDHAVENOT or OULDHAVETO leading to:
_ O U L D H A V E _ O
Latter is interesting again because of its vowel/consonant structure:
_ V V C C C V C V C V
or (with ‘must have not’)
_ C V C C C V C V C V
which might, after guessing and placing vowel/consonant structures, a good approach to get a partial cleartext of the cipher (good method to approach homophone ciphers, imo). Because we know that if ‘++’ is a double vowel (e.g. ‘EE’) AND ‘pO++’ being part of one word, then ‘p’ can be a vowel OR a consonant. Furthermore, if ‘++’ is a double consonant (e.g. ‘LL’) AND ‘pO++’ being part of one word, then ‘p’ must be a consonant OR the word will show up with a double vowel (e.g. ‘REALLY’).
It’s all about scrabble:
http://www.scrabblefinder.com/contains/v/
QT
*ZODIACHRONOLOGY*
Yo.
please don’t try to understand anything of what I’ll post as we are getting deeper into vowel-consonant analysing stuff.
‘First order analytics’, which actually is equal to letter frequency analysis, is limited somehow. We did already know that and keep in mind that the letter ‘E’ – in the 408 cipher – did actually show up for the first time on position #13 regarding the frequency of all present symbols.
Actually there is no good approach at all to solve monoalphabetic homophone ciphers, such as the 408 or the 340, except e.g. guessing. Or analyzing word patterns, thus ‘123442’ could represent ‘street’ and so on.
An additional approach, however, is the ‘second order analysis’. This actually is focussing on bigrams and statistical data of how often each alphabetical letter ‘touches’ the other ones. ![]()
Russian KGB friend ‘Boris Viktorovich Sukhotin’ was into that one and found an algorithm suitable for substitution ciphers to identify vowels. He wrote abstracts such as the
Оптимизационные методы исследования языка
http://search.library.wisc.edu/catalog? … iktorovich)%22&search_field=author
which I’d love to see translated into English (anybody from Wisconsin?).
A short description of this method, however, can be found in an abstract of Mr. Jacques B. M. Guy:
http://hum.uchicago.edu/jagoldsm/Papers … khotin.pdf
This abstract in fact is mainly nonsense, as Jaque Guy made a fatal scientific error:
‘Well, not Sukhotin’s algorithm word for word, but it boils down to exactly the same; it only gets there faster, with less number shuffling’
Lazy guy, this Mr. Guy. This is how science actually should not look like.
Guy was wrong, as the method described by him would only work if the first vowel is identified correctly as being a vowel. This, however, happens in Guy’s method only according to its contact frequency. Assuming the letter ‘T’ occurring more often than any other vowel and it will lead Mr. Guy into the desert nowhere (‘boiling down’…). I tried it with the ‘wbiol++…’ section and not only understood but can even test that he is (in that case) wrong.
Nevertheless, the idea of translating badly is a good one, and so did Caxton C. Foster quite a good job, too.
http://hum.uchicago.edu/jagoldsm/Papers … Caxton.pdf
Sadly I am not owning the 1956 edition of Helen Gaines’ ‘Cryptanalysis’ (Dover), so I can’t say if she had to add anything else to the work of this future KGB student Boris V. Sukhotin.
http://www.tandfonline.com/doi/abs/10.1 … ASZ1_l_tu4
Leaving all the science stuff behind (don’t like universities..only serial killers there), we still can continue. The site http://www.mcld.co.uk/decipher/ offers a nice tool to get the statistical values of bigrams in texts, therefore telling exactly how often each letter (or symbol) is in contact with each other symbol.
For the 340 this is a 63×63=3.969 work to do and, when entering the cipher, you will get something looking like this (smaller stuff for illustration only):
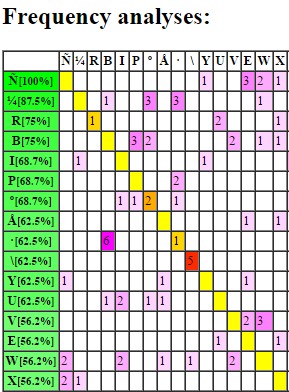
Good to see, however, that some bigrams in both directions show up more often than others. This happens in simple and homophone substitution ciphers. Of course we did all know that, e.g. that ‘TH’ is one of the most frequent bigrams.
Now comes the tricky part, which is in detail: P(Xi=b|Xi-1=a). This is the scientific way to express the probability of a bigram showing up in a text. No need to understanding such silly stuff, let’s better have a look at the results:
http://www.data-compression.com/english.html#notes
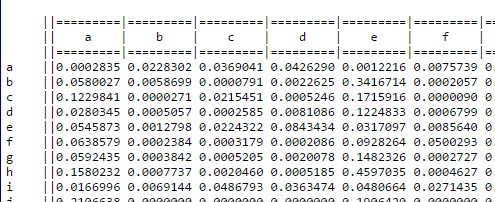
This wonderful site did analyse various books with approximately 5,000,000 letters and their contacts to each other. Therefore we got valid and statistically proven second order data, although adjustment for the ‘space’ list is required. Now what else can be easier than some 8-dimensional thinking and getting those two things (general bigram statistics and evaluation of the bigrams of the 340) together? Nothing!
Well, the truth is that in the 340, most of the symbols are connected to each other only once. This is what makes the cipher so incredibly hard to solve. We got some bigrams, e.g. ‘bF’ or ‘Fb’, and two trigrams and that’s it. So what can we do?
Yes, we can. Let’s have a closer at it. Indeed there is a way to transpond the general statistical data to the amount of letters which are expected to be in the 340. Therefore we take the previous statistics and calculate
StatValue x FrequencyExp x 340
with
StatValue = the statistical frequency of bigrams
FrequencyExp = the expected frequency of a letter (‘Scott Bryce’)
in a cipher with the length of 340. According to Scott Bryce (or any other alphabetical first order frequency talbe) the letter ‘A’ for example would show up with a frequency of 8,0% or 27.2 times in a text with the length of 340 letters. This multiplicated with the (general) statistical value of bigrams leads us to the amount of bigrams in the 340 with the letter ‘A’ being involved (e.g. ‘AN’, ‘AT’, ‘LA’ etc.).
We therefore can evaluate HOW OFTEN a bigram with the letter ‘A’ would show up in a normal text. And this is interesting because we now know that the letter A mostly shows up in connection with the letter ‘T’ and ‘N’. It does not show up very often in bigrams with the letters AEIOU, which is the main idea of Sukhotin’s theory. It is exceptional that vowels show up together very often and is this ‘second order statistic’ valid even if Z had used some letters more frequently than others, either by purpose or accidentially.
But this is the boring part.
What is more fascinating is that based on a text with the length of 340 only few bigrams have a (numeric) frequency of 4 or higher. So in fact the only bigrams that are expected to show up at least four times in the 340 are the following:
EA ED ND DE HE RE SE TE NG TH AN EN IN ON TO ER ES AT ST OU
It is obvious that all the others, e.g. MU (4.58% with ‘M’ to be expected only 8.6 times in the 340) will get a number of 8.6 x 0.0458 = 0,39 times showing up in the 340. It therefore will probably not show up at all, and if so, probably not 3 or 4 times.
It’s still tricky. If we look at the frequency of bigrams in the 340, a frequency of e.g. 4 bigrams doesn’t necessarily mean that it represents the general amount of four expected bigrams. Why? Because we handle homophones! Therefore some other symbols could lead to additional bigrams with e.g. the letter ‘A’ being involved.

BUT: IF there are other homophones involved, leading to additional bigrams, then we have to analyse the bigrams with a higher frequency of four per 340 (see above) and decide:
1. Which bigram (statistic) is complying with a frequency of e.g. four per 340?
2. IF additional homophones are involved, leading to a higher amount of bigrams which we cannot see yet: Which bigrams are then complying with an even higher frequency than four per 340?
Now we are getting closer to it. The amount of bigrams in the 340 is four. IF additional homophones are involved, leading to a hidden amount of bigrams >4 only the following (statistical) bigrams are into the run:
ED (6)
ND (6)
HE (10)
AN (6)
EN (5)
IN (7)
RE (6)
TH (14)
ER (9)
ES (5)
ST (5)
out of which we now can choose, of course. What appears to be a dead-end, in fact, is not. We now have a fourth approach:
1. Guessing
2. Symbol frequency (first order)
3. Double letter frequency (second order)
4. Bigram frequency (second order)
and can we furthermore look at e.g. reversible or non-reversible bigrams (e.g. ‘bF’ or ‘Fb’).
And we are not limited to that:
Statistical interpretation of the 340’s bigrams also shows that the symbol ‘+’ is in contact with not only a few but even more than 50% of all the other symbols. Not necessarily does this mean that it is a vowel (e.g. ‘E’), as it could still be a consonant (e.g. ‘T’). But now we can compare it to the behaviour (I’m going to call it ‘cozyness’) of e.g. the double letter ‘G’. This potential double letter is mainly in contact only with five alphabetical letters, the letters A, E, H, O, R (all bigrams together with ‘G’ are expected to appear only once in the 340).
It therefore is very unlikely that G represents e.g. the ‘+’ symbol:
1. Guessing leads to no conclusion due to many words existing with ‘G’ or ‘GG’ – inconclusive
2. Letter Frequency of ‘G’ is generally lower (first order) – inconclusive
3. Double letter frequency is approximately 1-2, therfore could be ok to appear 3 times (second order)- inconclusive
4. Bigrams with ‘G’ mostly (e.g. 95%) cover 5 of 26 alphabetical letters (19%). Bigrams with ‘+’, however, cover approximately 13 of 26 alphabetical letters (50%), (second order) – conclusive!
Thus we can say: Guessing didn’t work. We also had always the sneaking suspicion that ‘G’ would not have a frequency of 7%, however we couldn’t be sure. It was still possible that ‘G’ represents the ‘GG’ or ‘++’ double letter somehow. But the last analysis, the bigram, showed us that it is very unlikely that ‘G’ is equal to the ‘+’ symbol because of the amount of alphabetical letters it is connected to in bigrams (‘cozyness’). This is why, we can rule out ‘G’ for being the ‘+’ symbol.
As you can see, we are still dealing with statistics. Hopefully you can see that the bigram statistics is more independent to any outliers than simple letter frequency. The permutation from letter frequency to bigram frequency also leads to other more qualified assumptions, even if we consider the cipher being a homophone chiffre. Letters might be excluded more easily, bigrams might be narrowed to be placed at certains positions of the cipher.
Here we go with the letters’ ‘cozyness’ in bigrams (e.g. ‘D’ being expected to be in contact with mostly 7 different letters leads to 7/26 = 26.7%):
A 53,8%
B 15,4%
C 26,9%
D 26,9%
E 59,3%
F 23,1%
G 19,2%
H 19,2%
I 50,0%
J 0,0%
K 3,8%
L 26,9%
M 19,2%
N 34,6%
O 42,3%
P 19,2%
Q 0,0%
R 42,3%
S 38,5%
T 42,3%
U 19,2%
V 3,8%
W 19,2%
X 0,0%
Y 11,5%
Z 0,0%
We can see that most letters do not prefer being in contact with >30% of the other letters of the alphabet. Therefore we can select A, E, I, O, R, S, T as being potential candidates for ‘+’. A and I might be ruled out due to the double letter frequency. Remaining are E, O, R, S, T as the only (!) candidates for ‘+’.
Next step? Finding such a letter being in contact with approximately 50% of all other alphabetical letters. This under consideration of it being a double letter appearing approximately three times. And having a frequency of 7% or higher. Then combining it with the frequent bigrams such as ‘bF’ or ‘Fb’ and putting in the values into the ZDK crack machine.
We’ll see. ![]()
QT
*ZODIACHRONOLOGY*
Please at least give the previous post a short look.
This is the visualization of bigram statistics, limited applicable (valid but the amount of bigrams in the 340 are not) to the 340 cipher. The highest peak is the bigram ‘QU’ as in 99% of all ‘Q’ the letter ‘U’ is following.
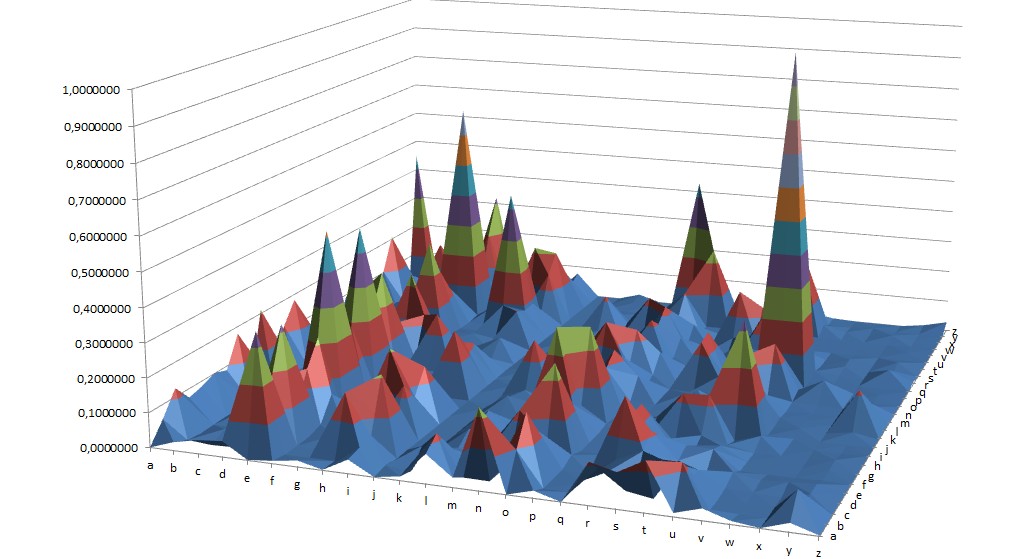
QT
*ZODIACHRONOLOGY*

Yo.
please don’t try to understand anything of what I’ll post as we are getting deeper into vowel-consonant analysing stuff.
No problemo. ![]()

“I don’t know Chief, he’s very smart or very dumb.“
