
Lets do discussion specifically on the Graysmith proposed solution to the 340 here:
And leave this thread more for QT’s excellent work on the 340.
There is some overlap as both QT and RG solve the + as an L,.
MODERATOR
Lets do discussion specifically on the Graysmith proposed solution to the 340 here:
http://www.zodiackillersite.com/viewtop … f=81&t=260
And leave this thread more for QT’s excellent work on the 340.
There is some overlap as both QT and RG solve the + as an L,.
Agreed, AK. I thought about starting a thread about Graysmith’s solution myself. The previous post wasn’t a comment on QT’s work (or yours), by the way- just some thoughts about partial solutions and solutions expanding upon them.

That’s ok, everybody is welcome…so let’s see who’ll crack it first ![]() D
D
QT
*ZODIACHRONOLOGY*

😆 I’ll be glad when you all solve this cypher. I’ve developed a permanent headache from trying to understand what is being said.

Give me psychology any day.
Well here goes. In that The Z. said "If you cops think I’m going to take on a bus the way I stated" and another letter said the cipher contained his name but actually included the phrase "I will not give you my name", why should one think the 340 cipher has a solution much less a useful message?
"Jerry, just remember, it’s not a lie if you believe it." George Costanza from Seinfeld

😆 I’ll be glad when you all solve this cypher. I’ve developed a permanent headache from trying to understand what is being said.
Give me psychology any day.
Well here goes. In that The Z. said "If you cops think I’m going to take on a bus the way I stated" and another letter said the cipher contained his name but actually included the phrase "I will not give you my name", why should one think the 340 cipher has a solution much less a useful message?
Because, just as you have shown precedent for lying and or misdirection, Zodiac also provided a precedent for supplying ciphers that did contain a message, the 408. So whilst it’s tempting to think that the 340 is gibberish there is more of a precedent for it not being given his previous actions concerning ciphers. Now, if he had supplied a cipher then later admitted it was nonsense to keep the cops busy then that would be a strong precedent for the 340 being the same. He didn’t though.
That being said. Useful message? we won’t know until we read it. Solvable? well that’s the crux of the matter really. It and the smaller ones might well be unsolvable whether by design or error or so contrived and bespoke as to make them virtually so but that doesn’t mean they don’t contain a message.
From a purely graphic pov, and I’ve mentioned this recently, the amount of work put into committing the 340 to paper makes me think it is valid. I know it doesn’t look like a lot of work but it was. To get that grid laid out, by whatever method, on blank paper with the symbols aligned and the whole thing positioned neatly within the space, well, someone else said this before, it’s a little work of art. This is just my opinion but Z put thought into his work and given that this is presented as a cipher, I think he would have felt untrue to himself if it wasn’t actually a cipher or a message of some sort.

“I don’t know Chief, he’s very smart or very dumb.“
I always had wondered if the 408 is solved perfectly correct..how can we know which of the three parts sent is actually the 1st, 2nd, 3rd..with 13 symbols remaining. But well, it’s a solid solution with loads of correctness in it.
And yes, imo the 340 is solvable in a similar way, too.
QT
*ZODIACHRONOLOGY*
Ok..another thought, you will be rewarded with ‘absolute Z cipher wiseness’ if reading all.. ![]()
We do know that Z had used the double symbol ‘++’ exactly three times in the 340 cipher.
This equals a frequency of 88 per 10,000 letters, therefore occurring 57% more often than any double letter may be expected ( http://tigger.uic.edu/~jleon/mcs425-s06 … r_freq.pdf). In the past I had assumed that this might be because of Zs characteristic to use the double letter ‘LL’ more often than usual.
Further I had assumed that this frequency, ’88 per 10,000′, leads to either the double letter ‘LL’ or the double letter ‘TT’, subsequently ‘LL’ being preferred as the overall frequency of the ‘+’ symbol, 7.06% (24 of 340) appeared to be a match to the statistical frequency of the letter ‘L’: 4.14% x 1.57 = 6.50%. The letter ‘T’ was ruled out, as ‘T’ would occur 9.25% x 1,57 = 14.52%, which is not implying with its statistical value (while the 6.50% could quite well be a match to the 7.06% of the ‘+’ symbol). http://scottbryce.com/cryptograms/stats.htm
This might, however, be false. Even if ‘LL’ would occur 57% more often, it doesn’t automatically lead to the conclusion that ‘L’ occurs with an overall 57% higher frequency. We should face that, if a double letter occurs 57% more frequent than expected, this doesn’t automatically mean that the whole (single) letter frequency is 57% higher as well.
We may therefore follow the thought that an unexpectedly higher frequency of ‘++’ (’88 per 10,000′ instead of e.g. ’56 per 10,000′) had simply occurred because the double letter had coincidentially occurred three times instead of two times only. This might happen by only using one more word (such as ‘shall’ or ‘will’), which would lead to a three times occurrence instead of a statistically more plausible occurrence of two times. In statistics, this is called an ‘outlier’ which biases a true statistical value.
The above average occurrence of the ‘+’ may therefore, for temporary reasons, be adjusted by assuming only two ‘++’ in the 340 cipher text. This appears absolutely plausible, as the frequency would then be ’58 per 10,000′, which fits perfectly the statistical pattern of double letters. It then still is implied to match the double letter frequency of ‘TT’ and ‘LL’, which usually appear 56 times per 10,000 letters, therefore two words with such double letter being present in the 340 cipher.
However, ‘TT’ and ‘LL’ are not the only double letters that may statistically appear with a frequency of two words per 340 letters.
Double letters such as ‘GG’ or ‘FF’ might be easily ruled out, as they usually don’t even make it up to two double letters in a cipher text of the length 340. Others double letters however, in fact only the double letters ‘EE’, ‘SS’ and ‘OO’, may quite well fit into that pattern, as their statistical value is close to or above 44 per 10,000, indicating that they have a potential to occur at least two, if not three times (‘outlier’) in the 340.
We may expect, based on the statistical evaluation of 3,2m letters, that the ‘++’ symbol represents a double letter which occurs two times in the 340. Those are the double letters ‘TT’, ‘LL’, ‘EE’, ‘SS’ and ‘OO’. All this is a statistical consideration under the assumption that the ’88 per 10,000′ frequency was caused by an outlier, one single word that had been added more often than it may have been expected according to statistical data.
Now my assumption:
First I assume that the ‘+’ symbol is representing one alphabetical letter only. If not, ‘+’ would presumably present the letter ‘E’, ‘T’ or ‘O’, as those double letter ‘candidates’ have a similar or higher overall frequency. Other letters, such as ‘G’, either don’t fit the double letter frequency pattern or would not fit the overall letter frequency at all. Also, we do know that Z, in the 408, had replaced some letters by only one symbol. So we may, for a short time, continue with this assumption:
The frequency of the symbol ‘+’ is 7.06% (24/340). But we may assume that, because of the outlier, the adjusted statistical frequency is at least less one of the double letters – because this one, the third one, is presumably an outlier (deviation is 57%, which would otherwise mean that Z had used this double letter 57% more often – which is quite a strong deviation). We therefore subtract at least one of the double letters, leading to a statistically adjusted frequency of ’23 per 340′ or 6.76%.
We do know that the letters ‘E’, ‘T’ and ‘O’ usually do have a higher overall frequency than 6.76%. Therefore more symbols would be required to represent those letters in the cipher. We also do know that the letter ‘L’ has an overall frequency of only 4.14%, which is significantly lower than the adjusted frequency of ‘+’ (6.76%). Therefore, contrary to my previous assumptions, the symbol ‘+’ presumably does NOT represent the letter ‘L’.
But what about the letter ‘S’?
‘S’ has an overall statistical frequency of 6.54% – this is very close to the outlier-adjusted frequency of 6.76%. The deviance in fact is 6.76/6.54 = 1,034, therefore only 3.4%! Scott Bryce even lists the double letter ‘SS’ as the most frequent double letter, indicating that three words containing the double letter ‘SS’ is in fact a good assumption for the ’88 per 10,000′ occurrence of ‘++’.
This may be accepted as the possibility of a statistical ‘hit’, testifying that Z had used the ‘SS’ not only as the most frequent double letter, but with almost precisely the same overall frequency that may be expected according to statistical data. In fact 3.4% is very, very close, and does this clearly support the idea of ‘S’ being a solution for the ‘+’ symbol, even under consideration of the more frequent letters ‘T’, ‘E’ or ‘O’..as I will explain, why:
Because the double letter ‘OO’ in fact appears only ’36 per ‘10,000’ times, which equals only 1.22 times – it therefore is present with rather one than two words in a 340 letter text.
The double letter ‘EE’, with a frequency of ’48 per 10,000′, would appear 1.63 times in such a 340 letter text. So would the double letter ‘TT’, with a frequency of ’56 per 10,000′, be present 1.90 times. However those two letters would require more symbols representing them due to their way higher overall frequency (‘T’ = 9.25%; ‘E’ = 12.51%).
‘S’ is therefore the only double letter, with ’43 per 10,000′ or 1.46 double letter words in a 340 letter text, that would not require any additional symbols. If Z had used the ‘SS’ only once more often than the statistic would say – three single words containing the double letter ‘SS’ – this is a very good statistical match.
All other letters may somehow be ruled out, let it be because of the double letter frequency (e.g. ‘GG’ or ‘FF’) or because of the overall letter frequency (‘L’). The idea of ‘+’ representing the letter ‘S’ is in fact strongly supported by the almost identical overall frequency, with a deviation of 3.4% only – which based on 340 letters for lingual statistics appears to be very significant. And not to forget: Even if Z had used ‘+’ for ‘E’ or ‘T’, it would be a sheer coincidence that one of the symbols representing this letter exactly hits the frequency of ‘S’ frequency by only 3.4%.
It even might be assumed to reduce the frequency of ‘+’ by both ‘++’ symbols of the ‘outlier’. Then in fact the overall frequency of the ‘+’ symbol would be ’22 per 340′, leading to a frequency of 6.47%. This is even closer to the statistical value of ‘S’ (6.54%) and is the deviation (between the outlier-adjusted frequency of ‘+’ compared to the frequency of ‘S’) then reduced to only 1.08%!
This is nothing, in fact we talk about the circumstance that – considering the statistically significant existence of an ‘outlier’ (+57%) – Z had used exactly as many ‘S’ letters as it would have been expected by statistical data!
So I clearly have to revise my personal assumption that ‘+’ represents the letter ‘L’. If we follow the combination of overall and double letter statistics, only one solution is applicable and, in fact, matching exactly the statistical expectancy – the letter ‘S’. Only if Z had – coincidentally or by purpose – chosen the exact frequency of ‘S’ for ‘+’ as being one of multiple symbols representing the letters ‘E’ or ‘T’, those two may still not be completely ruled out. If he had chosen only one ‘+’ symbol more – or less – it would immediately indicate that ‘+’ is representing either ‘T’ or ‘L’. With all respect, the 408 had patterns of sequences, but it does not seem as if – in addition to the number of different symbols – Z had put an eye on the overall amount of each of those symbols, too (as in fact their amount depends on the variety of symbols as well as the length of the cipher). Meaning Z would have chosen not 15 or 18 or 20 or 24 or 28 or 30 but exactly 22 or 23 ‘+’ symbols to (partially) represent the letter ‘T’ or ‘E’..which seems to be rather unlikely the case.
Matching the overall ‘S’ frequency exactly rather indicates that ‘S’ is a solid match for the ‘+’ symbol, with a significant outlier-adjusted deviation of 3.4% or even 1.08%, depending on the circumstance if the whole outlier (3rd ‘++’) or only one of its double letters (‘+’) is eliminated.
Now prove me wrong..
QT
*ZODIACHRONOLOGY*

The ++ MUST stand for one of the following:
BB/DD/EE/FF/GG/LL/MM/NN/OO/PP/RR/SS/TT/ZZ, since those are the only letters you can use back to back in a word, UNLESS, he has confused us and ended a word,and started another one, example: theshoWWillgoon, then it could be any letter, but assuming that’s not the case, it will most likely be one of those 14 letters
There is more than one way to lose your life to a killer
http://www.zodiackillersite.com/
http://zodiackillersite.blogspot.com/
https://twitter.com/Morf13ZKS

The ++ MUST stand for one of the following:
BB/DD/EE/FF/GG/LL/MM/NN/OO/PP/RR/SS/TT/ZZ, since those are the only letters you can use back to back in a word, UNLESS, he has confused us and ended a word,and started another one, example: theshoWWillgoon, then it could be any letter, but assuming that’s not the case, it will most likely be one of those 14 letters
There are more than you think, morf. Not a complete list, but a few common word examples:
AA: aardvark, bazaar
CC: accelerate, accept, accent, access, accidentally, acclaim, accommodate, account
HH: bathhouse, beachhead, fishhook, hitchhike, roughhousing, withholding
II: genii, radii, skiing, taxiing
KK: bookkeeper, jackknife, knickknack, trekked, yakked
UU: continuum, muumuu, vacuum
VV: civvies, divvy, skivvies
WW: arrowwood, glowworm, powwow, screwworm
-glurk
——————————–
I don’t believe in monsters.

No one said the doubles need be within a single word. What about "sicKKiller" as an example?
Here is the data I collected from a HUGE amount of English text from books on Project Gutenberg. This is the data that is used in ZKDecrypto for double letters, log-weighted:
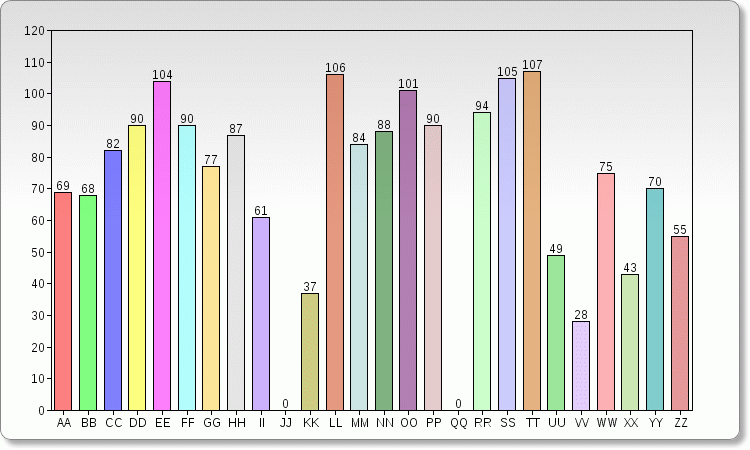
This is based on text with all spaces removed, so word abutments are considered.
-glurk
EDIT: Here they are in order:
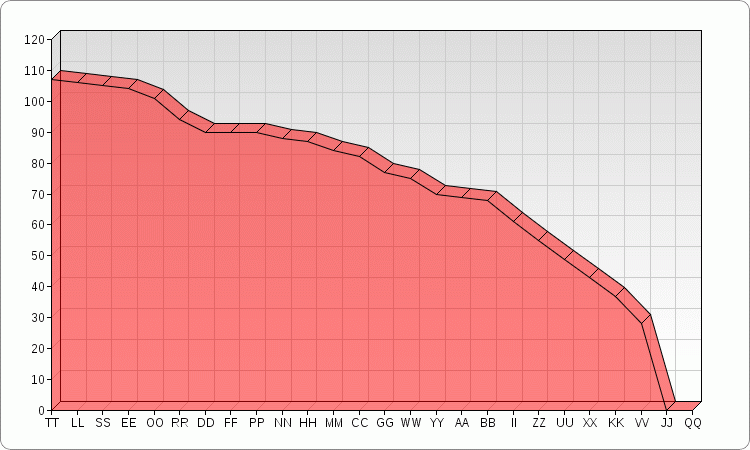
——————————–
I don’t believe in monsters.
The ++ MUST stand for one of the following:
BB/DD/EE/FF/GG/LL/MM/NN/OO/PP/RR/SS/TT/ZZ, since those are the only letters you can use back to back in a word, UNLESS, he has confused us and ended a word,and started another one, example: theshoWWillgoon, then it could be any letter, but assuming that’s not the case, it will most likely be one of those 14 letters
This approach totally makes sense (following the way the 408 was solved successfully) but it presumes that the 340 cipher is created by simple substitution and that the cipher is meant to be read in a normal manner (left to right or, I suppose, backwards could work as well). The dilemma, IMO, is that the 340 should then have been easy pickins for ZKDekrypto, should it not? If we could guess the right double letter combo, we would be left with a cipher that is shorter than the 408 and with more symbols already accounted for than the Hardens had to work with. The fact that it’s proven to be anything but easy pickins leads me to believe that the solution probably involves some sort of additional twist or two… or more…
True..I have already tried it..with ‘LL’, which imo is false. I think trying it with similar settings (another issue on its own..) and e.g. ‘S’ for the ‘+’ would in fact make very much sense..nevertheless, it’s still shorter than the 408, with more symbols present, so it could be that the program won’t make it?
Anybody an idea under which settings the 408 runs clear (Failures, Swaps, Tolerance)?
QT
*ZODIACHRONOLOGY*
No quicktrader I think you are wrong. You were right before ![]()
Glurk’s study shows that TT, LL, SS and EE are the most used in English writing, with LL being the second most used.
In the first Zodiac Code he used "S" 24 times. Only once was there a "SS", and that happened in the phrase "it iS So much fun". Zodiac neved used a word that has "SS" in it, not once. Compare that to the number of words he used in the first code that had "LL" – SEVEN different words! And they are words we might think it is likely he also used in the 340 code. They were kill, killing, thrilling, collecting, shall, will, all. Zodiac also used these words with a single "L". – like, people, wild, girl, slaves, slow, animal, afterlife.
By my rough quick count, the letter "L" appears 33 times in the 408 code. About 8.1% of the letters are "L", which is about double normal usage, as it happens that many words Z liked to use have either L or LL in them. So if Z used "L" 8.1% of the time in the 408, it seems to me that 9.7% use in the 340 code is within normal deviation, really only two more uses of a word like kill, killing, collecting, etc., would do it. And if we strike the untranslated last 18, leaving us 390 translated letters, the 33 uses of "L" amount to 8.5%, which is even closer to my proposed 9.7%. in the 340 code.
MODERATOR
Thanks for confusing me that early in the morning..while ZKDecrypto is running in the background.. ![]()
To figure out a Z-related alphabetical letter distribution, I sometimes do a quick check against his letters – what else. Many of them can be found at
http://en.wikisource.org/wiki/Zodiac_Killer_letters
and as far as I know does it contain text data of approximately 16,500 letters. In fact Z had used the letter combination ‘LL’ or ‘L L’ about 220 times (please use your browser search function instead of counting..), which is an incredibly high ‘133 per 10,000’ frequency of the double letter ‘LL’ (usually its about ’56 per 10,000′). From that point of view, you therefore may be right.
Z’s overall frequency of the letter ‘L’ however, in that context, is about 1,000 times in that 16,500 letters, which equals about 6.12% only. Could still work with a 7.05% quota of the ‘+’ symbol in the 340, true (deviation 15%).
The ‘SS’ or ‘S S’ however, Z had used approximately 52+24=76 times in those 16,500 letters…this equals a ’46 per 10,000′ frequency – and with a deviation of this is a very good match with the expected ’43 per 10,000′ ( http://tigger.uic.edu/~jleon/mcs425-s06 … r_freq.pdf). Deviation is only 7%, showing that Z had used the letter SS only slightly more often than statistic would expect.
Both is possible, however the deviation is higher in the first analysis, even greater is the distance to the expected non-Z-modified letter frequency expectation. The second is imo a better match not only because of the outlier theory – supporting both letters in a similar way – but also because of the excellent match with the overall ‘S’ frequency – and due to the fact that this would be represented by only one symbol. But I agree, LL is still a possibility.
In that context btw I see the reversed PP symbols as being a one-time-frequency double letter…the combination of ‘PP’ indicates that this letter is also represented by only one symbol (as otherwise the next symbol would have come into effect immediately after the first one). This implies that there is another double-letter with an overall frequency of +/-3%. This could be the letter ‘DD’, as this is working out with both. DD has a double letter frequency of ’13 per 10,000′, therefore about 0.442 times in the 340 cipher and in fact occurs only once AND has an overall frequency of 3.99%.
Therefore it could be a very good match for that one…the letters O R F P are similar to this expected ‘1x double letter in the 340’ frequency, however O and R have much higher frequencies, F is similarly close with 2.3% (actually overall frequency, P is not that close with 2.0% but still might be a match.
So I’d conclude that the reverse P symbol is representing its clear text letter without any other symbols involved and that this cleartext letter is either D, F, or P. However there still is the possibility that Z had used a symbol twice one after another in a homophone sequence, but I’d say this is rather unlikeley as Z had not done so in the 408, at least not in the beginning of the homophone sequences. ![]()
Imo we do expect for 99% sure (personal opinions of course allowed, e.g. what if Z had used homophone sequences using two identical symbols in a row instead of changing symbols each time, at least at the beginning of the cipher, as he had done in the 408):
‘++’ is representing one clear text letter without any other symbols involved
‘++’ is thought to be either EE, TT, LL, OO or SS, according to its double letter frequency
‘++’ has a statistical ‘outlier’- caused by one single word – leading to a 3x per 340 instead of an expected 2x per 340 frequency (which is the highest double letter frequency at all).
‘++’ is expected to be SS according to its overall frequency with a significant outlier-adjusted match of deviation (<3%, a perfect match of exactly the correct amount of letters expected) ![]()
‘++’ may however still represent ‘LL’ if Z had used the letter ‘L’ with an above-average overall & double letter frequency (+70% compared to Scott Bryce but only +15% compared to various Z communications)
‘++’ may rather not be any other letter, not ‘EE’ or ‘TT’ or ‘OO’ etc. as those would require additional symbols that in general would ‘destroy’ the occurrence of any double letter due to Z changing the symbols
‘++’ may rather not be any other letter, not ‘EE’ or ‘TT’ or ‘OO’ etc. as those are statistically not applicable with both, double letter and overall letter frequency
‘++’ may at least once be followed by the ending -ING and/or -ED ![]()
‘O’ is expected to be a vowel (est. 95%) as it occurs twice before a ‘+’ as well as once after a reversed ‘p’, which both are expected to be consonants ![]()
‘pp’ is representing one clear text letter without any other symbols involved, otherwise no double letter would occur in the cipher
‘pp’ has a double letter frequency of 1 per 340, therefore is thought to be either D, F, P, R but not E, T, L, O, S as those have significantly higher double letter frequencies
‘p’ could still represent any other letter with an expected double letter frequency of less or more than 1 per 340
‘p’ however has an overall frequency of 3.2%, indicating that it is rather not E, T, L, O, S, R, A, I, N, H as they do have a significantly higher overall frequency (starting from 4.14% up)
‘p’ however has an overall frequency of 3.2%, indicating that it is rather not W, Y, B, V, K, J, X, Q, Z as they do have a significantly lower overall frequency (starting from 1.92% down)
‘p’ therefore may be expected to come out the family of C, D, U, M, F, P, G ![]()
All this used with ZK Decrypto leads to a nice value of 32,000 points, but no solution yet. ![]()
BTW, I have replaced the 407kb language dictionary file with a 8,000kb file..however I still got the feeling that its quality is not only bad but also not sufficient enough…anybody an idea if there is a good dictionary file somewhere? Thx,
QT
*ZODIACHRONOLOGY*
